CPRM: A LLM-based Continual Pre-training Framework for Relevance Modeling in Commercial Search
作者: Kaixin Wu, Yixin Ji, Zeyuan Chen, Qiang Wang, Cunxiang Wang, Hong Liu, Baijun Ji, Jia Xu, Zhongyi Liu, Jinjie Gu, Yuan Zhou, Linjian Mo
分类: cs.AI, cs.CL, cs.IR, cs.LG
发布日期: 2024-12-02 (更新: 2025-02-18)
备注: NAACL 2025
💡 一句话要点
CPRM:一种基于LLM的持续预训练框架,用于提升商业搜索中的相关性建模。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 持续预训练 相关性建模 商业搜索 上下文学习
📋 核心要点
- 现有基于LLM的相关性模型在商业搜索中面临领域知识不足、上下文学习能力欠缺以及对结构化item信息利用不充分等挑战。
- CPRM框架通过联合预训练、上下文预训练和阅读理解等模块,持续提升LLM在商业搜索相关性建模方面的能力。
- 离线实验和在线A/B测试表明,CPRM框架显著优于现有基线模型,验证了其在提升商业搜索相关性方面的有效性。
📝 摘要(中文)
本文提出CPRM(Continual Pre-training for Relevance Modeling),一个用于LLM持续预训练的框架,旨在解决商业搜索引擎中query和item相关性建模的问题。现有方法存在领域知识不足、上下文学习潜力未充分利用、结构化item文本利用率低、以及query和背景知识匮乏等问题。CPRM框架包含三个模块:1) 采用query和多字段item联合预训练,增强领域知识;2) 应用上下文预训练,在相关query或item序列上预训练LLM;3) 对item进行阅读理解,生成相关的领域知识和背景信息(例如,生成摘要和对应的query),进一步强化LLM。离线实验和在线A/B测试结果表明,与强基线模型相比,CPRM模型取得了令人信服的性能。
🔬 方法详解
问题定义:论文旨在解决商业搜索引擎中query和item之间的相关性建模问题。现有的基于LLM的方法存在以下痛点:缺乏领域特定知识,无法充分利用上下文学习的潜力,对结构化的item文本利用不足,并且缺乏相应的query和背景知识。
核心思路:论文的核心思路是通过持续预训练的方式,让LLM逐步学习和适应商业搜索领域的知识和特点。通过联合预训练、上下文预训练和阅读理解等手段,增强LLM对query和item之间关系的理解,从而提升相关性建模的准确性。
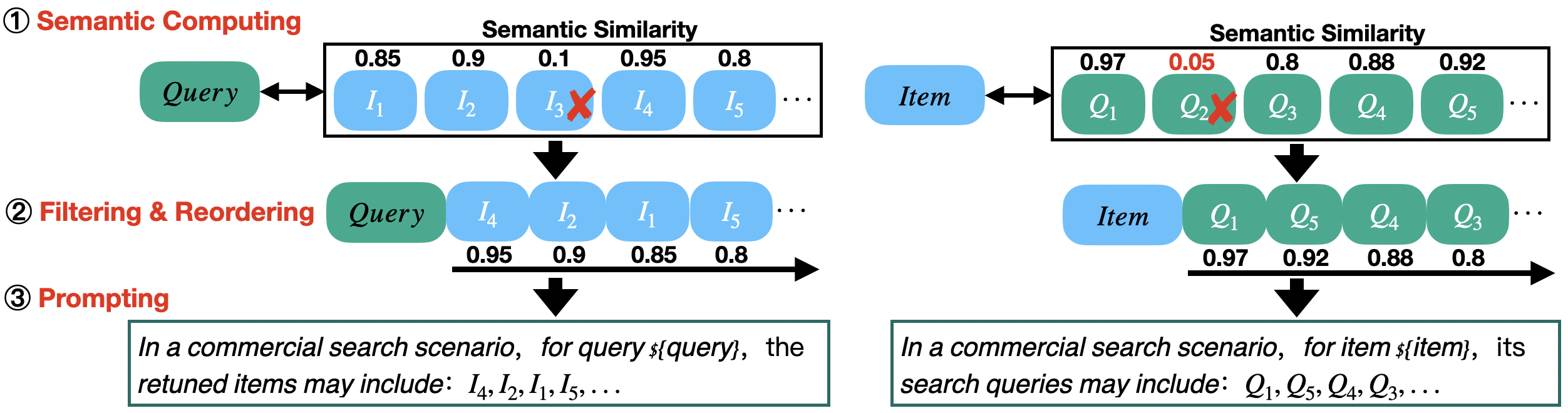
技术框架:CPRM框架包含三个主要模块: 1. 联合预训练:使用query和多字段item进行联合预训练,增强LLM的领域知识。 2. 上下文预训练:在相关的query或item序列上进行预训练,使LLM能够更好地理解上下文信息。 3. 阅读理解:对item进行阅读理解,生成相关的领域知识和背景信息,例如生成摘要和对应的query,进一步强化LLM。
关键创新:CPRM的关键创新在于提出了一个完整的持续预训练框架,该框架能够有效地利用query、item以及它们之间的关系,从而提升LLM在商业搜索相关性建模方面的能力。特别是上下文预训练模块,通过在相关序列上进行预训练,使LLM能够更好地捕捉上下文信息,这与传统的独立query-item对的训练方式有本质区别。
关键设计:论文中没有详细描述具体的参数设置、损失函数和网络结构等技术细节。但是,可以推断,联合预训练可能采用对比学习或生成式预训练目标,上下文预训练可能采用序列预测或掩码语言模型等方法,阅读理解模块可能采用抽取式或生成式阅读理解模型。具体的技术细节需要参考论文的补充材料或代码。
🖼️ 关键图片


📊 实验亮点
CPRM模型在离线实验和在线A/B测试中均表现出色,证明了其有效性。具体性能数据和提升幅度未在摘要中明确给出,但强调了其相对于强基线模型取得了“令人信服的性能”。这表明CPRM在实际应用中具有显著的优势。
🎯 应用场景
CPRM框架可应用于各种商业搜索引擎,以提升搜索结果的相关性和用户体验。通过持续预训练,该框架能够使LLM更好地理解用户意图和item特征,从而提供更准确、更个性化的搜索结果。此外,该框架还可以应用于推荐系统、广告检索等领域,具有广泛的应用前景。
📄 摘要(原文)
Relevance modeling between queries and items stands as a pivotal component in commercial search engines, directly affecting the user experience. Given the remarkable achievements of large language models (LLMs) in various natural language processing (NLP) tasks, LLM-based relevance modeling is gradually being adopted within industrial search systems. Nevertheless, foundational LLMs lack domain-specific knowledge and do not fully exploit the potential of in-context learning. Furthermore, structured item text remains underutilized, and there is a shortage in the supply of corresponding queries and background knowledge. We thereby propose CPRM (Continual Pre-training for Relevance Modeling), a framework designed for the continual pre-training of LLMs to address these issues. Our CPRM framework includes three modules: 1) employing both queries and multi-field item to jointly pre-train for enhancing domain knowledge, 2) applying in-context pre-training, a novel approach where LLMs are pre-trained on a sequence of related queries or items, and 3) conducting reading comprehension on items to produce associated domain knowledge and background information (e.g., generating summaries and corresponding queries) to further strengthen LLMs. Results on offline experiments and online A/B testing demonstrate that our model achieves convincing performance compared to strong baselines.