Fairness at Every Intersection: Uncovering and Mitigating Intersectional Biases in Multimodal Clinical Predictions
作者: Resmi Ramachandranpillai, Kishore Sampath, Ayaazuddin Mohammad, Malihe Alikhani
分类: cs.AI
发布日期: 2024-11-30
💡 一句话要点
提出一种多模态临床预测中缓解交叉偏见的方法,提升公平性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 交叉偏见 多模态学习 临床预测 电子健康记录 公平性 子群体分析 预训练语言模型
📋 核心要点
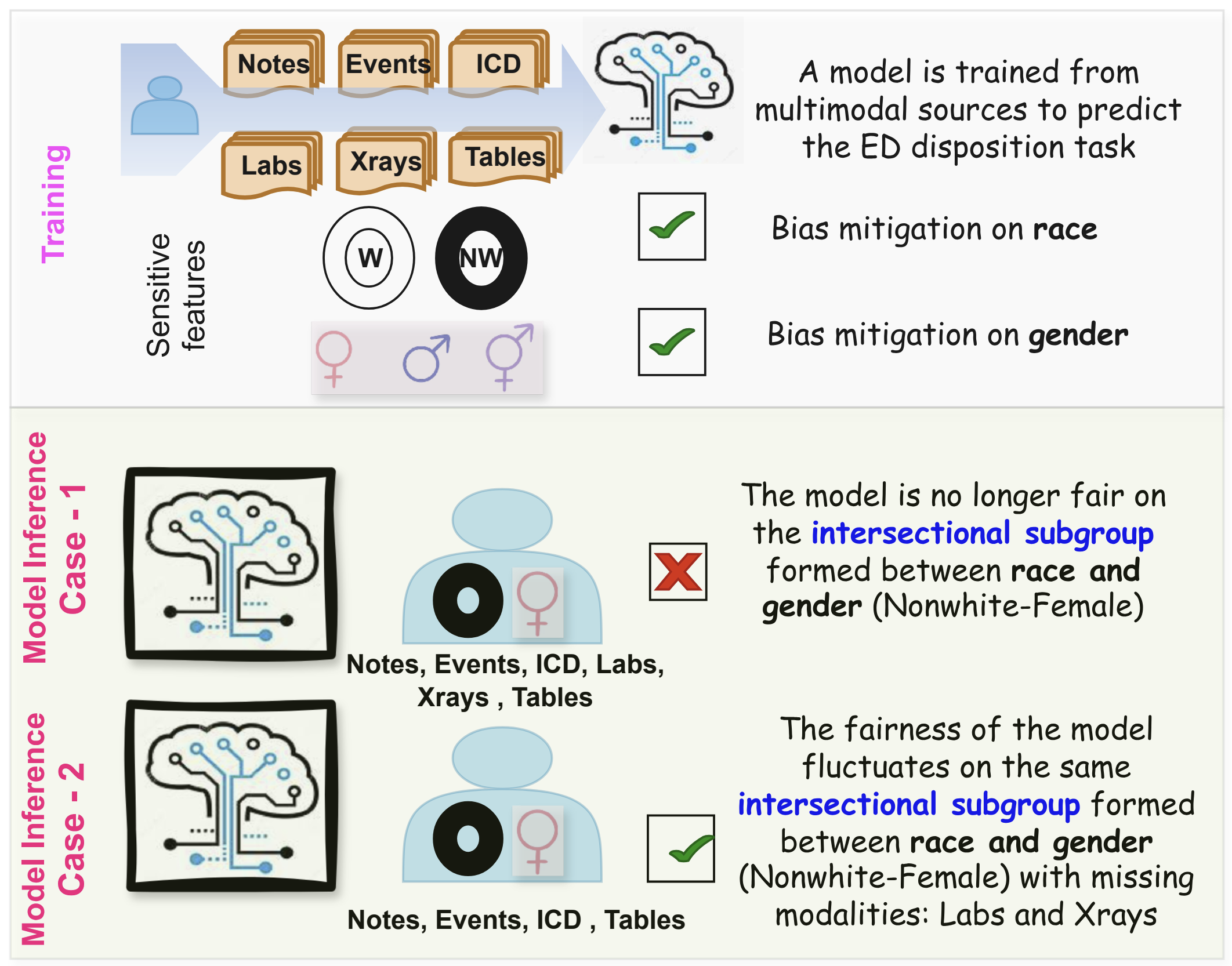
- 现有临床决策方法忽略了由多种人口属性交叉形成的子群体,导致对特定人群的偏见。
- 该论文提出在交叉子群体层面进行偏见缓解,针对不同子群体的分布和偏见模式进行优化。
- 实验表明,该方法在多个数据集和嵌入上具有鲁棒性,有效缓解了多模态环境中的交叉偏见。
📝 摘要(中文)
利用电子健康记录(EHR)进行自动临床决策中的偏见,会在患者护理和治疗结果中造成显著差异。传统方法主要关注于源自单一属性的偏见缓解策略,忽略了交叉子群体——由各种人口统计交叉(如种族、性别、民族等)形成的群体。由于这些子群体中分布和偏见模式各不相同,针对单一属性的缓解策略应用于交叉子群体在统计上变得不相关。EHR的多模态性质——来自文本、时间序列、表格、事件和图像等各种来源的数据——增加了另一层复杂性,因为对少数群体的影响可能在不同模态之间波动。本文初步探索了预测中潜在的交叉偏见,通过获取广泛的多模态数据集MIMIC-Eye1和MIMIC-IV ED,并提出在交叉子群体层面进行缓解。通过利用预训练的临床语言模型(LM)MedBERT、Clinical BERT和Clinical BioBERT的强大功能,从多模态来源学习统一的文本表示,我们在数据集上执行和基准测试下游任务和偏见评估。研究结果表明,所提出的子群体特定偏见缓解方法在不同的数据集、子群体和嵌入中都具有鲁棒性,证明了其在多模态环境中解决交叉偏见的有效性。
🔬 方法详解
问题定义:论文旨在解决在多模态临床预测中,由于电子健康记录(EHR)数据中存在的交叉偏见,导致对特定患者群体(例如,按种族、性别等交叉分组)的不公平预测问题。现有方法主要关注于单一属性的偏见缓解,无法有效处理交叉子群体中复杂的偏见模式,导致统计上的不相关性。
核心思路:论文的核心思路是在交叉子群体层面进行偏见缓解。这意味着不再将偏见视为单一属性的问题,而是针对由多个属性组合定义的特定子群体,设计相应的缓解策略。这种方法能够更好地捕捉不同子群体中偏见的分布和模式,从而提高缓解效果。
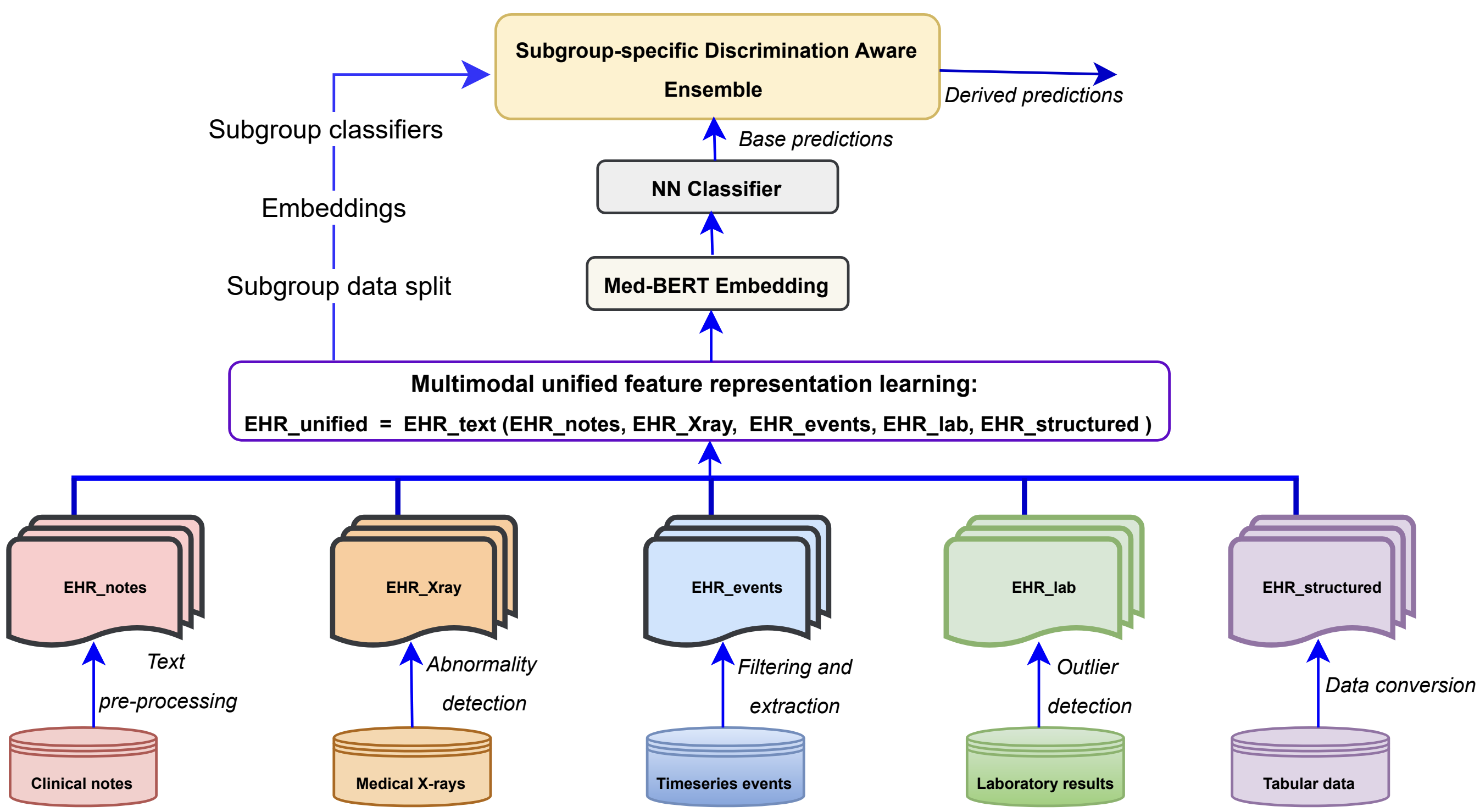
技术框架:整体框架包括数据预处理、多模态特征提取、统一文本表示学习、下游任务预测和偏见评估与缓解几个主要阶段。首先,从MIMIC-Eye1和MIMIC-IV ED等多模态数据集中提取文本、时间序列、表格和图像等特征。然后,利用预训练的临床语言模型(如MedBERT、Clinical BERT和Clinical BioBERT)学习统一的文本表示,将不同模态的信息融合到文本空间中。最后,在下游任务(如疾病预测)上进行训练和评估,并针对交叉子群体进行偏见评估和缓解。
关键创新:最重要的技术创新点在于提出了交叉子群体层面的偏见缓解策略。与传统的单一属性偏见缓解方法相比,该方法能够更精确地识别和缓解特定子群体中的偏见,从而提高整体的公平性。此外,利用预训练的临床语言模型进行多模态特征融合,也提高了模型的性能和泛化能力。
关键设计:论文的关键设计包括:1) 针对不同交叉子群体,设计不同的偏见缓解策略;2) 利用预训练的临床语言模型,学习统一的文本表示,融合多模态信息;3) 使用特定的偏见评估指标,量化不同子群体中的偏见程度;4) 通过调整模型参数或修改训练数据,实现偏见缓解。具体的参数设置、损失函数和网络结构等细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
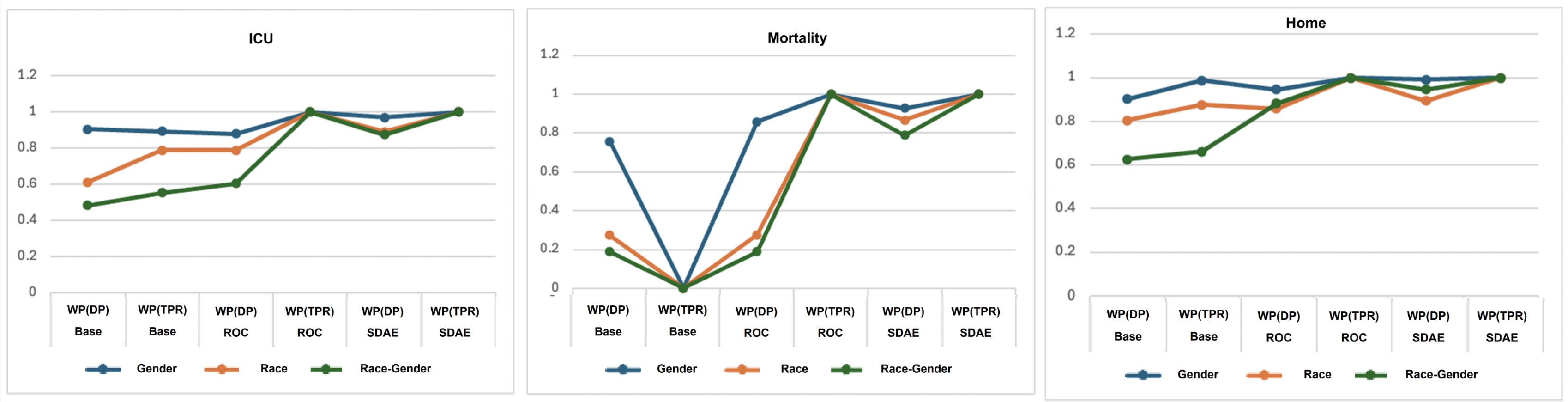
实验结果表明,所提出的子群体特定偏见缓解方法在MIMIC-Eye1和MIMIC-IV ED数据集上均表现出良好的鲁棒性。无论使用MedBERT、Clinical BERT还是Clinical BioBERT等不同的预训练语言模型,该方法都能有效缓解交叉子群体中的偏见,提升下游任务的公平性。具体的性能提升数据未知,但结论表明该方法具有普遍适用性。
🎯 应用场景
该研究成果可应用于临床决策支持系统,辅助医生进行更公平、更准确的诊断和治疗。通过缓解电子健康记录中的交叉偏见,可以减少医疗资源分配不均,改善少数族裔的医疗服务质量,最终提升整体医疗系统的公平性和可信度。未来,该方法可以推广到其他领域,如金融、教育等,以解决类似的偏见问题。
📄 摘要(原文)
Biases in automated clinical decision-making using Electronic Healthcare Records (EHR) impose significant disparities in patient care and treatment outcomes. Conventional approaches have primarily focused on bias mitigation strategies stemming from single attributes, overlooking intersectional subgroups -- groups formed across various demographic intersections (such as race, gender, ethnicity, etc.). Rendering single-attribute mitigation strategies to intersectional subgroups becomes statistically irrelevant due to the varying distribution and bias patterns across these subgroups. The multimodal nature of EHR -- data from various sources such as combinations of text, time series, tabular, events, and images -- adds another layer of complexity as the influence on minority groups may fluctuate across modalities. In this paper, we take the initial steps to uncover potential intersectional biases in predictions by sourcing extensive multimodal datasets, MIMIC-Eye1 and MIMIC-IV ED, and propose mitigation at the intersectional subgroup level. We perform and benchmark downstream tasks and bias evaluation on the datasets by learning a unified text representation from multimodal sources, harnessing the enormous capabilities of the pre-trained clinical Language Models (LM), MedBERT, Clinical BERT, and Clinical BioBERT. Our findings indicate that the proposed sub-group-specific bias mitigation is robust across different datasets, subgroups, and embeddings, demonstrating effectiveness in addressing intersectional biases in multimodal settings.