Unified Parameter-Efficient Unlearning for LLMs
作者: Chenlu Ding, Jiancan Wu, Yancheng Yuan, Jinda Lu, Kai Zhang, Alex Su, Xiang Wang, Xiangnan He
分类: cs.AI, cs.LG
发布日期: 2024-11-30 (更新: 2025-04-18)
💡 一句话要点
提出LLMEraser,用于LLM中高效、统一的参数高效解学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 解学习 参数高效微调 影响函数 隐私保护
📋 核心要点
- 现有LLM解学习方法通常范围有限,需要大量重新训练,效率低下。
- LLMEraser通过系统分类解学习任务,并利用影响函数进行精确的参数调整,实现高效解学习。
- 实验表明,LLMEraser在多种解学习场景下表现出色,保持了模型整体性能。
📝 摘要(中文)
大型语言模型(LLMs)的出现彻底改变了自然语言处理,使其能够在各种任务中实现高级理解和推理能力。针对特定领域对这些模型进行微调,特别是通过参数高效微调(PEFT)策略(如LoRA),由于其效率已成为一种普遍做法。然而,这也引发了重大的隐私和安全问题,因为模型可能会无意中保留和传播敏感或不良信息。为了解决这些问题,我们引入了一种新颖的实例级解学习框架LLMEraser,该框架系统地对解学习任务进行分类,并使用影响函数应用精确的参数调整。与通常在范围上受到限制且需要大量重新训练的传统解学习技术不同,LLMEraser旨在处理广泛的解学习任务,而不会影响模型性能。在基准数据集上进行的大量实验表明,LLMEraser擅长有效地管理各种解学习场景,同时保持模型的整体完整性和有效性。
🔬 方法详解
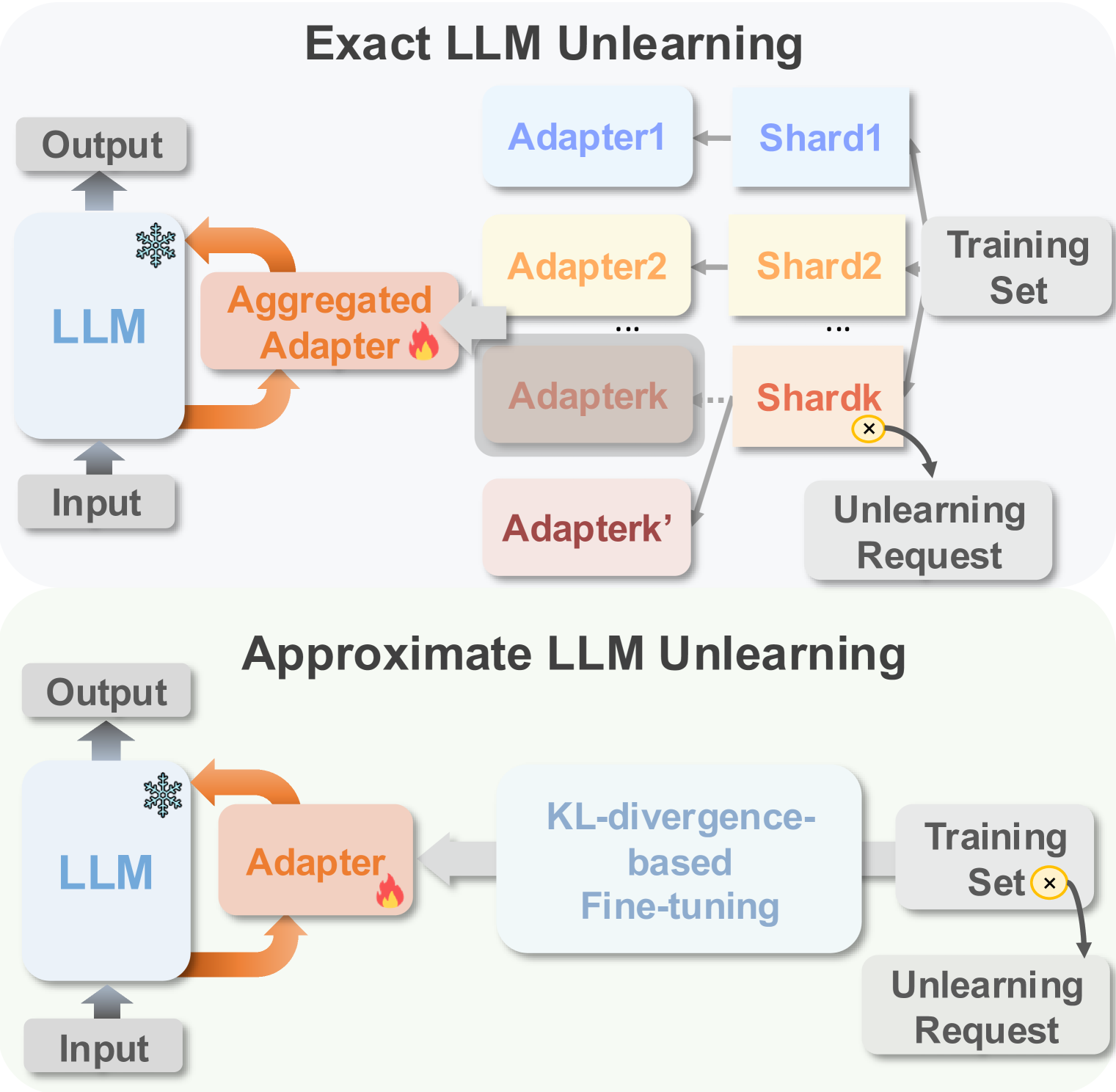
问题定义:论文旨在解决大型语言模型(LLMs)在经过微调后,可能无意中保留和传播敏感或不良信息的问题。现有的解学习方法通常需要大量重新训练,计算成本高昂,且适用范围有限,难以应对各种解学习场景。
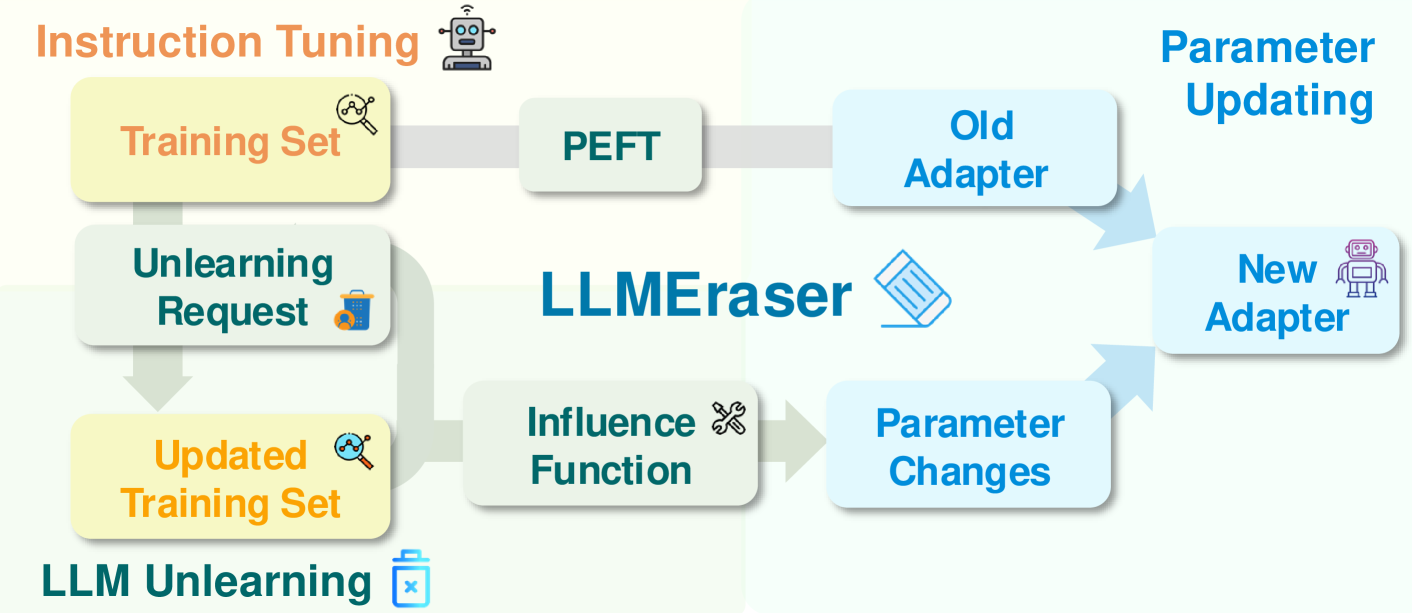
核心思路:LLMEraser的核心思路是利用影响函数来精确调整模型参数,从而实现高效的实例级别解学习。通过系统地对解学习任务进行分类,并针对不同类型的任务应用相应的参数调整策略,可以在不进行大规模重新训练的情况下,有效地“擦除”模型中不需要的信息。
技术框架:LLMEraser框架主要包含以下几个阶段:1) 解学习任务分类:将解学习任务划分为不同的类别,例如删除特定实例、删除特定概念等。2) 影响函数计算:针对每个解学习任务,计算需要调整的参数的影响函数。影响函数衡量了模型参数对特定实例或概念的预测结果的影响程度。3) 参数调整:根据影响函数的结果,对模型参数进行精确的调整,以达到解学习的目的。
关键创新:LLMEraser的关键创新在于其统一的参数高效解学习框架,能够处理各种解学习任务,而无需进行大规模的重新训练。通过结合参数高效微调(PEFT)策略和影响函数,LLMEraser能够在保证解学习效果的同时,显著降低计算成本。与现有方法相比,LLMEraser具有更高的效率和更广的适用性。
关键设计:LLMEraser的关键设计包括:1) 针对不同解学习任务的参数调整策略。2) 基于影响函数的参数更新公式。3) 与参数高效微调(PEFT)策略(如LoRA)的集成,以进一步提高解学习效率。具体的参数设置和损失函数选择可能需要根据具体的LLM和解学习任务进行调整。
🖼️ 关键图片

📊 实验亮点
论文在基准数据集上进行了大量实验,证明了LLMEraser在各种解学习场景下的有效性。实验结果表明,LLMEraser能够在保持模型整体性能的同时,有效地删除模型中不需要的信息。具体的性能数据和对比基线在论文中有详细描述,展示了LLMEraser相对于现有方法的显著优势。
🎯 应用场景
LLMEraser可应用于各种需要保护用户隐私和数据安全的场景,例如金融、医疗、法律等领域。通过使用LLMEraser,可以确保LLM在提供智能服务的同时,不会泄露用户的敏感信息。此外,LLMEraser还可以用于删除LLM中的不良信息,例如仇恨言论、虚假新闻等,从而提高LLM的社会责任感。
📄 摘要(原文)
The advent of Large Language Models (LLMs) has revolutionized natural language processing, enabling advanced understanding and reasoning capabilities across a variety of tasks. Fine-tuning these models for specific domains, particularly through Parameter-Efficient Fine-Tuning (PEFT) strategies like LoRA, has become a prevalent practice due to its efficiency. However, this raises significant privacy and security concerns, as models may inadvertently retain and disseminate sensitive or undesirable information. To address these issues, we introduce a novel instance-wise unlearning framework, LLMEraser, which systematically categorizes unlearning tasks and applies precise parameter adjustments using influence functions. Unlike traditional unlearning techniques that are often limited in scope and require extensive retraining, LLMEraser is designed to handle a broad spectrum of unlearning tasks without compromising model performance. Extensive experiments on benchmark datasets demonstrate that LLMEraser excels in efficiently managing various unlearning scenarios while maintaining the overall integrity and efficacy of the models.