Marconi: Prefix Caching for the Era of Hybrid LLMs
作者: Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zancato, Tri Dao, Yida Wang, Ravi Netravali
分类: cs.DC, cs.AI, cs.LG
发布日期: 2024-11-28 (更新: 2025-04-10)
备注: MLSys 2025 camera-ready version
💡 一句话要点
Marconi:为混合LLM时代设计的前缀缓存系统,提升长上下文处理效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 前缀缓存 混合LLM 长上下文 缓存策略 状态空间模型
📋 核心要点
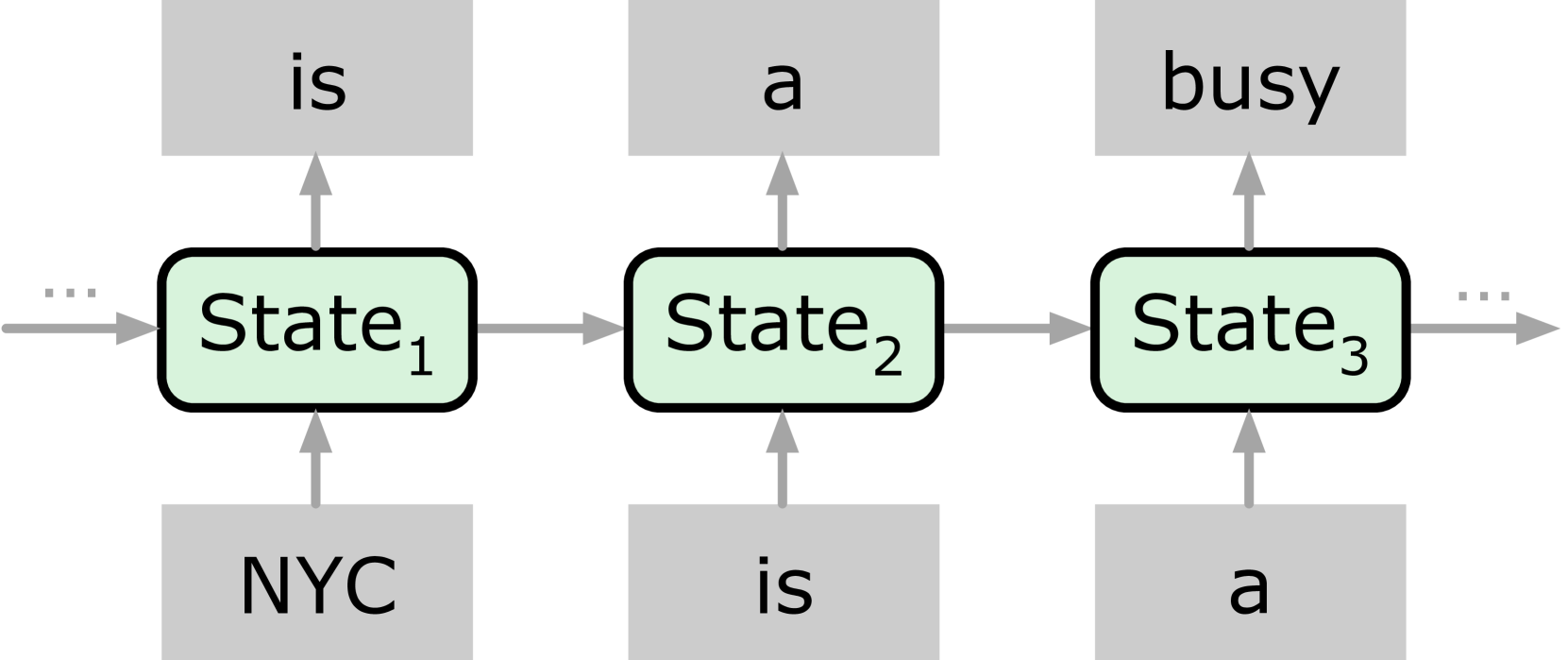
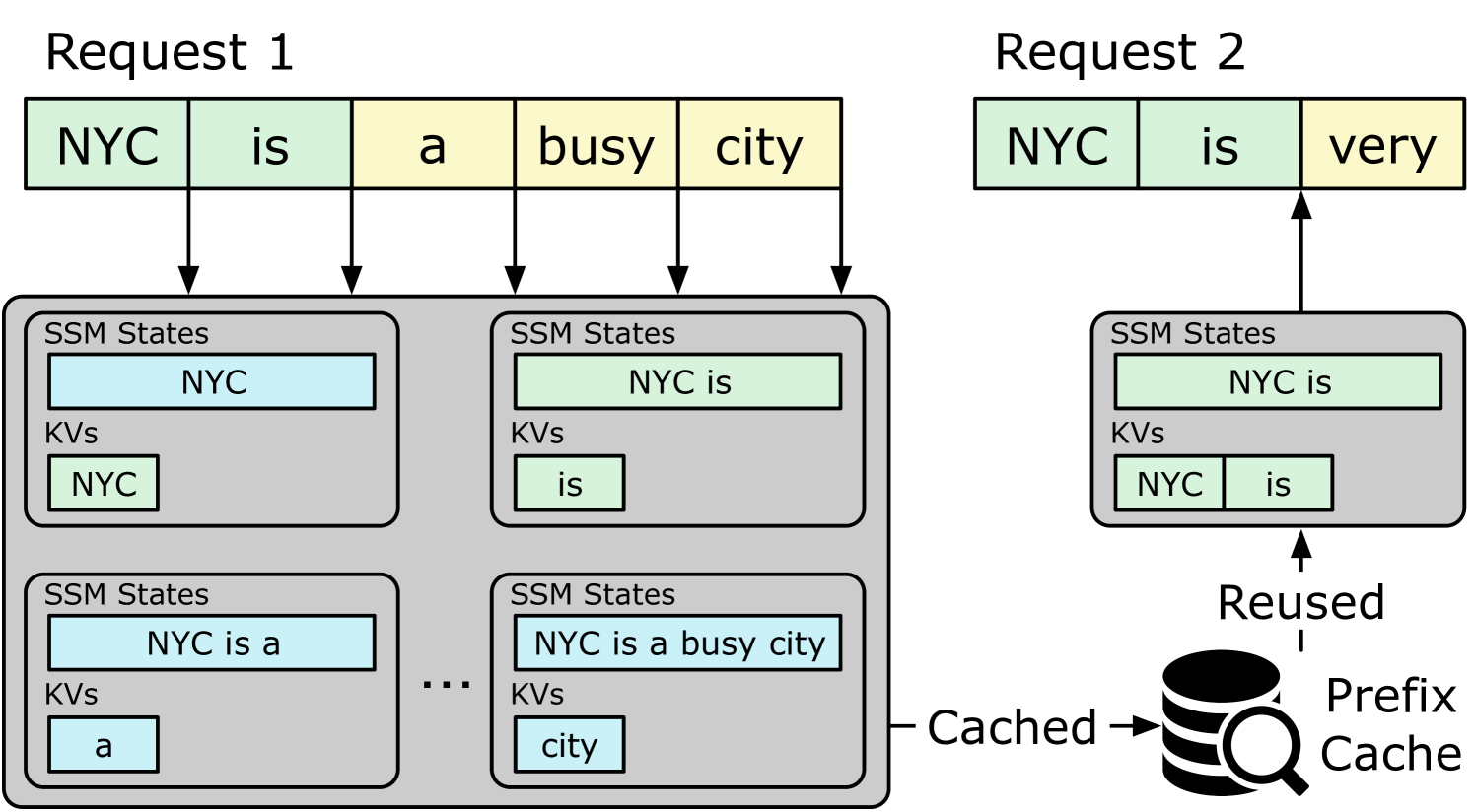
- 混合LLM模型在长上下文处理中面临前缀缓存效率低下的问题,现有方法无法有效处理循环层的原地状态更新。
- Marconi通过新颖的准入和驱逐策略,结合重用可能性预测和计算节省评估,优化缓存条目的选择。
- 实验结果表明,Marconi在token命中率上显著优于现有技术,有效降低了TTFT,提升了长文本处理效率。
📝 摘要(中文)
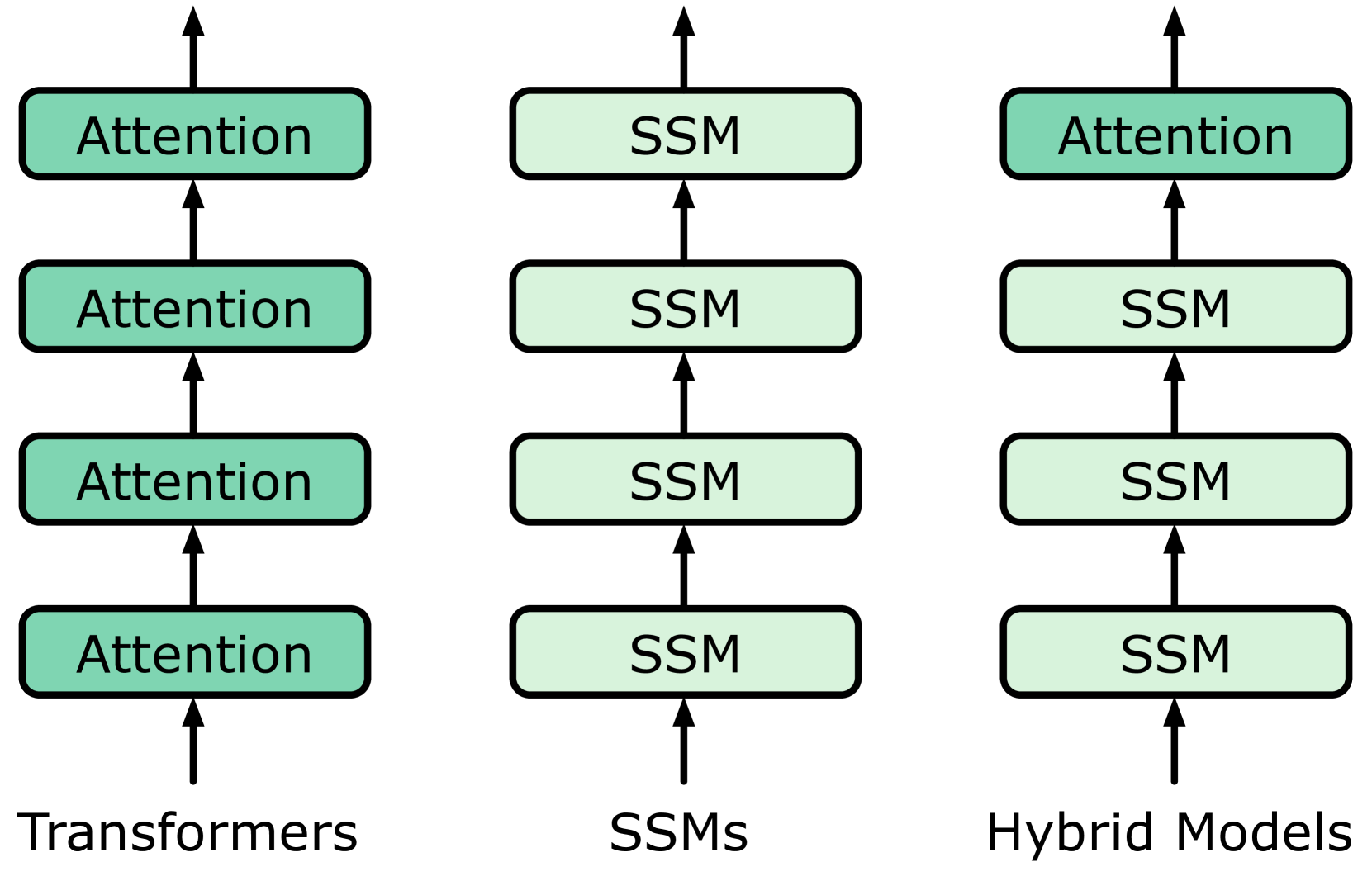
混合模型结合了Attention层的语言建模能力和循环层(例如状态空间模型)的效率,在实际应用中支持大型语言模型中的长上下文。然而,这些模型的独特性质使得诸如前缀缓存等优化技术的使用变得复杂,因为前缀缓存旨在跳过跨请求的冗余计算。最显著的是,它们对循环层使用原地状态更新,这排除了对部分序列重叠回滚缓存条目的可能性,而是强制要求完全匹配的缓存命中;其结果是每个序列产生大量(大型)缓存条目,其中大多数提供的重用机会极少。我们提出了Marconi,这是第一个支持混合LLM高效前缀缓存的系统。Marconi的关键在于其新颖的准入和驱逐策略,这些策略不仅基于最近性,还基于(1)对不同命中场景分类中重用可能性的预测,以及(2)命中相对于内存占用所带来的计算节省,从而更明智地评估潜在的缓存条目。在不同的工作负载和混合模型中,与最先进的前缀缓存系统相比,Marconi实现了高达34.4倍的token命中率提升(TTFT降低71.1%或617毫秒)。
🔬 方法详解
问题定义:现有前缀缓存系统在混合LLM模型中效率低下。混合模型中循环层的原地状态更新特性,导致无法有效利用部分序列重叠的缓存条目,只能依赖完全匹配,造成大量冗余缓存,降低了缓存命中率和整体性能。现有缓存策略主要基于最近性,未能充分考虑缓存条目的重用价值和计算节省。
核心思路:Marconi的核心思路是设计一种更智能的缓存管理策略,该策略不仅考虑缓存条目的最近使用情况,还预测其在不同场景下的重用可能性,并评估其带来的计算节省。通过综合考虑这些因素,Marconi能够更有效地选择和保留有价值的缓存条目,从而提高缓存命中率和整体性能。
技术框架:Marconi系统主要包含以下几个关键模块:1) 缓存条目评估模块:该模块负责评估每个潜在缓存条目的重用可能性和计算节省。2) 准入策略模块:该模块根据缓存条目的评估结果,决定是否将其添加到缓存中。3) 驱逐策略模块:该模块负责在缓存空间不足时,选择要从缓存中移除的条目。4) 缓存管理模块:该模块负责缓存的存储、检索和更新。
关键创新:Marconi的关键创新在于其准入和驱逐策略。这些策略不仅考虑了缓存条目的最近性,还引入了重用可能性预测和计算节省评估机制。具体来说,Marconi定义了一系列命中场景,并针对每个场景预测缓存条目的重用概率。此外,Marconi还考虑了缓存命中带来的计算节省,并将其与缓存条目的内存占用进行比较,从而更有效地选择有价值的缓存条目。与现有方法相比,Marconi能够更有效地利用缓存空间,提高缓存命中率。
关键设计:Marconi的关键设计包括:1) 重用可能性预测模型:该模型用于预测缓存条目在不同命中场景下的重用概率。模型的具体结构和训练方法未知。2) 计算节省评估函数:该函数用于评估缓存命中带来的计算节省,并将其与缓存条目的内存占用进行比较。具体函数形式未知。3) 准入和驱逐策略:这些策略基于重用可能性预测和计算节省评估结果,决定是否将缓存条目添加到缓存中或从缓存中移除。具体策略细节未知。
🖼️ 关键图片
📊 实验亮点
Marconi在多种工作负载和混合模型上进行了评估,实验结果表明,与最先进的前缀缓存系统相比,Marconi实现了高达34.4倍的token命中率提升,TTFT降低了71.1%(或617毫秒)。这些结果表明,Marconi能够显著提高混合LLM模型的推理效率。
🎯 应用场景
Marconi适用于需要处理长上下文的混合LLM模型,例如对话系统、文档摘要、代码生成等。通过提高缓存命中率,Marconi可以显著降低推理延迟,提高用户体验。该研究对于提升LLM在资源受限环境下的部署效率具有重要意义,并为未来的缓存系统设计提供了新的思路。
📄 摘要(原文)
Hybrid models that combine the language modeling capabilities of Attention layers with the efficiency of Recurrent layers (e.g., State Space Models) have gained traction in practically supporting long contexts in Large Language Model serving. Yet, the unique properties of these models complicate the usage of complementary efficiency optimizations such as prefix caching that skip redundant computations across requests. Most notably, their use of in-place state updates for recurrent layers precludes rolling back cache entries for partial sequence overlaps, and instead mandates only exact-match cache hits; the effect is a deluge of (large) cache entries per sequence, most of which yield minimal reuse opportunities. We present Marconi, the first system that supports efficient prefix caching with Hybrid LLMs. Key to Marconi are its novel admission and eviction policies that more judiciously assess potential cache entries based not only on recency, but also on (1) forecasts of their reuse likelihood across a taxonomy of different hit scenarios, and (2) the compute savings that hits deliver relative to memory footprints. Across diverse workloads and Hybrid models, Marconi achieves up to 34.4$\times$ higher token hit rates (71.1% or 617 ms lower TTFT) compared to state-of-the-art prefix caching systems.