Mars-PO: Multi-Agent Reasoning System Preference Optimization
作者: Xiaoxuan Lou, Chaojie Wang, Bo An
分类: cs.AI
发布日期: 2024-11-28
💡 一句话要点
Mars-PO:通过多智能体推理系统偏好优化提升LLM数学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 多智能体系统 偏好优化 指令微调
📋 核心要点
- 大型语言模型在数学推理方面面临挑战,自回归生成易导致错误和不一致。
- Mars-PO利用多智能体系统,结合高质量输出构建鲁棒的偏好对进行训练。
- 实验表明,Mars-PO显著提升了LLM在数学推理基准上的性能,超越了现有方法。
📝 摘要(中文)
本文提出了一种名为Mars-PO的新框架,旨在通过多智能体系统提升大型语言模型(LLM)的数学推理能力。由于自回归生成过程的特点,LLM在多步推理中容易出现错误、幻觉和不一致性。Mars-PO将多个智能体的高质量输出组合成一个混合正样本集,并将其与特定于智能体的负样本配对,从而构建用于训练的鲁棒偏好对。通过使智能体与共享的正样本对齐,同时解决个体弱点,Mars-PO在数学推理基准测试中实现了显著的性能提升。例如,在MATH基准测试中,最先进的指令调整LLM Llama3.1-8B-Instruct的准确率从50.38%提高到57.82%。实验结果进一步表明,该方法始终优于其他基线,如监督微调、原始DPO及其增强版本,突出了该方法的有效性。
🔬 方法详解
问题定义:大型语言模型(LLM)在数学推理任务中表现欠佳,尤其是在多步推理过程中,容易产生错误、幻觉和不一致性。现有的方法,如监督微调和直接偏好优化(DPO),无法充分利用不同模型输出中的优势,并且难以有效区分高质量和低质量的推理路径。
核心思路:Mars-PO的核心思路是利用多智能体系统,每个智能体代表一个LLM。通过让多个智能体独立生成推理过程,然后将它们的高质量输出组合成一个共享的正样本集。同时,每个智能体保留其自身的负样本,用于区分个体弱点。这种方式能够让智能体学习到更鲁棒的偏好,从而提升整体的数学推理能力。
技术框架:Mars-PO框架包含以下几个主要步骤:1) 使用多个LLM(智能体)独立生成数学问题的解答;2) 从每个智能体的输出中筛选出高质量的解答,并将它们组合成一个共享的正样本集;3) 为每个智能体构建偏好对,其中正样本来自共享的正样本集,负样本来自该智能体自身的低质量输出;4) 使用偏好优化算法(如DPO)训练每个智能体,使其更倾向于生成高质量的解答。
关键创新:Mars-PO的关键创新在于其多智能体协作和混合偏好学习机制。与传统的单模型训练方法不同,Mars-PO能够利用多个模型的优势,并通过共享正样本和个体负样本的方式,更有效地学习到高质量的推理策略。这种方法能够更好地解决LLM在数学推理中遇到的错误、幻觉和不一致性问题。
关键设计:在Mars-PO中,关键的设计包括:1) 如何定义和筛选高质量的解答(例如,通过验证答案的正确性或使用奖励模型);2) 如何构建有效的偏好对(例如,通过选择具有代表性的负样本);3) 如何选择合适的偏好优化算法(例如,DPO或IPO);4) 如何平衡共享正样本和个体负样本之间的权重,以避免过度拟合或欠拟合。
🖼️ 关键图片

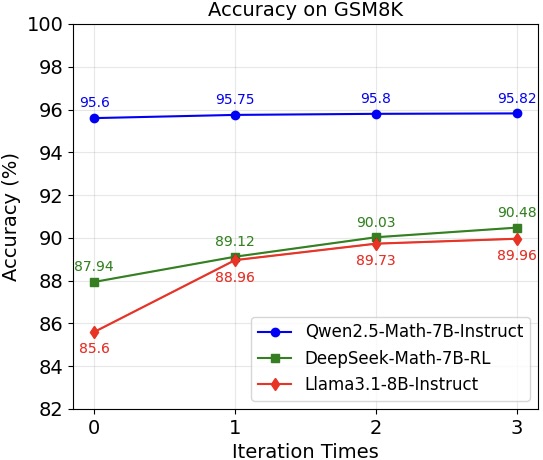

📊 实验亮点
Mars-PO在MATH基准测试中,将Llama3.1-8B-Instruct的准确率从50.38%提高到57.82%,显著优于监督微调和原始DPO及其增强版本。实验结果表明,Mars-PO能够有效地提升LLM的数学推理能力,并且具有良好的泛化性能。
🎯 应用场景
Mars-PO具有广泛的应用前景,可用于提升LLM在各种需要复杂推理能力的场景中的表现,例如科学研究、金融分析、法律咨询等。通过提高LLM的推理准确性和可靠性,可以使其在这些领域发挥更大的作用,并为人类提供更有效的决策支持。
📄 摘要(原文)
Mathematical reasoning is a fundamental capability for large language models (LLMs), yet achieving high performance in this domain remains a significant challenge. The auto-regressive generation process often makes LLMs susceptible to errors, hallucinations, and inconsistencies, particularly during multi-step reasoning. In this paper, we propose Mars-PO, a novel framework to improve the mathematical reasoning capabilities of LLMs through a multi-agent system. It combines high-quality outputs from multiple agents into a hybrid positive sample set and pairs them with agent-specific negative samples to construct robust preference pairs for training. By aligning agents with shared positive samples while addressing individual weaknesses, Mars-PO achieves substantial performance improvements on mathematical reasoning benchmarks. For example, it increases the accuracy on the MATH benchmark of the state-of-the-art instruction-tuned LLM, Llama3.1-8B-Instruct, from 50.38% to 57.82%. Experimental results further demonstrate that our method consistently outperforms other baselines, such as supervised fine-tuning, vanilla DPO, and its enhanced versions, highlighting the effectiveness of our approach.