Dspy-based Neural-Symbolic Pipeline to Enhance Spatial Reasoning in LLMs
作者: Rong Wang, Kun Sun, Jonas Kuhn
分类: cs.AI, cs.CL
发布日期: 2024-11-27 (更新: 2024-12-12)
💡 一句话要点
提出基于DSPy的神经符号流水线,提升LLM在空间推理任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 空间推理 大型语言模型 神经符号计算 答案集编程 DSPy 迭代反馈 逻辑推理
📋 核心要点
- 现有LLM在空间推理方面存在不足,难以有效处理涉及空间关系的复杂问题。
- 提出一种神经符号框架,结合LLM的语义理解能力和ASP的逻辑推理能力,通过迭代反馈提升性能。
- 实验表明,该框架在StepGame和SparQA数据集上显著优于基线方法,准确率分别提升40-50%和8-15%。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出了卓越的能力,但它们在空间推理方面常常遇到困难。本文提出了一种新颖的神经符号框架,通过LLMs和答案集编程(ASP)之间的迭代反馈来增强LLMs的空间推理能力。我们在两个基准数据集StepGame和SparQA上评估了我们的方法,实现了三种不同的策略:(1)直接提示基线,(2)Facts+Rules提示,和(3)基于DSPy的LLM+ASP流水线,具有迭代改进。我们的实验结果表明,LLM+ASP流水线明显优于基线方法,在StepGame上平均达到82%的准确率,在SparQA上达到69%的准确率,分别比直接提示提高了40-50%和8-15%。成功源于三个关键创新:(1)通过模块化流水线有效分离语义解析和逻辑推理,(2)LLMs和ASP求解器之间的迭代反馈机制,提高了程序速率,(3)强大的错误处理,解决了解析、接地和求解失败。此外,我们提出了Facts+Rules作为一种轻量级替代方案,在复杂的SparQA数据集上实现了可比的性能,同时降低了计算开销。我们对不同LLM架构(Deepseek, Llama3-70B, GPT-4.0 mini)的分析证明了该框架的通用性,并提供了对实现复杂性和推理能力之间权衡的见解,有助于开发更具可解释性和可靠性的AI系统。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在空间推理任务中表现不佳的问题。现有的LLM虽然在许多任务中表现出色,但在处理需要理解和推理空间关系的任务时,准确率较低,缺乏可靠性。这主要是因为LLM缺乏明确的逻辑推理能力,难以处理复杂的空间约束。
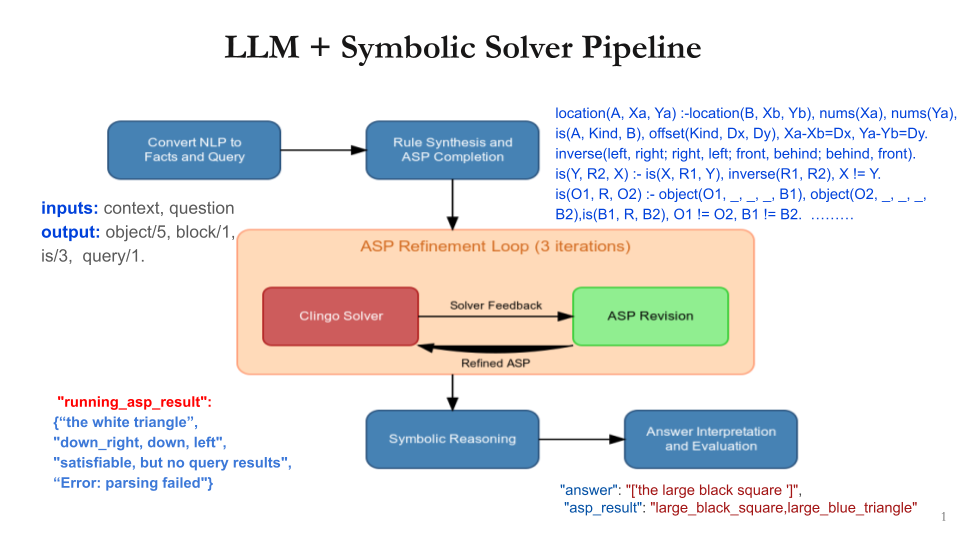
核心思路:论文的核心思路是将LLM的语义理解能力与答案集编程(ASP)的逻辑推理能力相结合,构建一个神经符号流水线。通过迭代反馈机制,LLM负责语义解析,将自然语言输入转化为逻辑规则和事实,ASP求解器负责逻辑推理,生成答案。LLM根据ASP的反馈不断优化解析结果,从而提高整体性能。
技术框架:该框架包含以下主要模块:1) LLM语义解析模块:将自然语言输入解析为ASP可理解的逻辑规则和事实。2) ASP求解器:根据LLM提供的规则和事实进行逻辑推理,生成答案或发现矛盾。3) 迭代反馈模块:将ASP求解器的结果反馈给LLM,LLM根据反馈调整解析结果,进行下一轮推理。整个流程迭代进行,直到达到预定的迭代次数或满足收敛条件。
关键创新:该方法最重要的创新点在于将神经模型(LLM)与符号推理(ASP)相结合,形成一个可迭代优化的流水线。与直接使用LLM进行推理相比,该方法能够有效分离语义解析和逻辑推理,利用ASP的精确推理能力弥补LLM的不足。此外,迭代反馈机制能够不断修正LLM的解析错误,提高程序速率。
关键设计:论文使用了DSPy框架来优化LLM的提示工程,使其能够更好地生成ASP代码。在迭代过程中,LLM会根据ASP求解器的反馈(例如,是否存在矛盾)来调整其输出。此外,论文还设计了鲁棒的错误处理机制,以应对解析、接地和求解过程中可能出现的错误。Facts+Rules方法作为一种轻量级替代方案,通过直接在提示中提供事实和规则,减少了计算开销。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于DSPy的LLM+ASP流水线在StepGame和SparQA数据集上显著优于基线方法。在StepGame上,该方法达到了82%的准确率,比直接提示提高了40-50%。在SparQA上,该方法达到了69%的准确率,比直接提示提高了8-15%。Facts+Rules方法在SparQA数据集上取得了与LLM+ASP流水线相当的性能,同时降低了计算开销。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、游戏AI、地理信息系统等领域。通过提升LLM的空间推理能力,可以使AI系统更好地理解和处理现实世界的空间关系,从而实现更智能、更可靠的决策和行为。未来,该方法有望扩展到其他需要复杂推理的任务中,例如知识图谱推理、常识推理等。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they often struggle with spatial reasoning. This paper presents a novel neural-symbolic framework that enhances LLMs' spatial reasoning abilities through iterative feedback between LLMs and Answer Set Programming (ASP). We evaluate our approach on two benchmark datasets: StepGame and SparQA, implementing three distinct strategies: (1) direct prompting baseline, (2) Facts+Rules prompting, and (3) DSPy-based LLM+ASP pipeline with iterative refinement. Our experimental results demonstrate that the LLM+ASP pipeline significantly outperforms baseline methods, achieving an average 82% accuracy on StepGame and 69% on SparQA, marking improvements of 40-50% and 8-15% respectively over direct prompting. The success stems from three key innovations: (1) effective separation of semantic parsing and logical reasoning through a modular pipeline, (2) iterative feedback mechanism between LLMs and ASP solvers that improves program rate, and (3) robust error handling that addresses parsing, grounding, and solving failures. Additionally, we propose Facts+Rules as a lightweight alternative that achieves comparable performance on complex SparQA dataset, while reducing computational overhead.Our analysis across different LLM architectures (Deepseek, Llama3-70B, GPT-4.0 mini) demonstrates the framework's generalizability and provides insights into the trade-offs between implementation complexity and reasoning capability, contributing to the development of more interpretable and reliable AI systems.