Can LLMs plan paths in the real world?
作者: Wanyi Chen, Meng-Wen Su, Nafisa Mehjabin, Mary L. Cummings
分类: cs.AI, cs.RO
发布日期: 2024-11-26 (更新: 2024-12-02)
💡 一句话要点
评估LLM在真实世界路径规划中的能力,发现其可靠性不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 路径规划 真实世界 车辆导航 实验评估
📋 核心要点
- 现有车辆导航系统逐渐集成LLM,但LLM在真实世界路径规划中的能力尚不明确,存在潜在风险。
- 通过设计真实场景测试LLM的路径规划能力,评估其在复杂环境下的可靠性,并分析错误原因。
- 实验结果表明,当前LLM在真实路径规划中表现出不可靠性,需要进一步研究和改进。
📝 摘要(中文)
随着大型语言模型(LLM)越来越多地集成到车辆导航系统中,理解它们进行路径规划的能力至关重要。本文在不同设置和难度下,通过六个真实世界的路径规划场景测试了三个LLM。实验表明,所有LLM在所有场景中都出现了大量错误,表明它们作为路径规划器是不可靠的。我们建议未来的工作重点是实施现实检查机制,增强模型透明度,并开发更小的模型。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在真实世界路径规划任务中的能力。现有方法,即直接将LLM应用于路径规划,存在缺乏现实世界约束和验证的痛点,导致规划结果可能不准确甚至不安全。
核心思路:论文的核心思路是通过设计一系列真实世界的路径规划场景,直接测试LLM在这些场景下的表现,从而评估其可靠性。通过观察LLM在不同难度和设置下的错误率,来判断其是否适合作为路径规划器。
技术框架:论文采用实验评估的方法。首先,选择三个LLM作为测试对象。然后,设计六个真实世界的路径规划场景,这些场景在难度和设置上有所不同。最后,将LLM应用于这些场景,记录其输出的路径,并分析其错误率。没有明确的架构图,主要在于实验设计和结果分析。
关键创新:论文的关键创新在于其评估方法,即直接在真实世界场景中测试LLM的路径规划能力。与以往可能侧重于模拟环境或理论分析的研究不同,本文更关注LLM在实际应用中的表现。
关键设计:实验设计是关键。六个场景的设计需要覆盖不同的环境、难度和约束条件,以全面评估LLM的能力。此外,错误率的定义和计算方式也需要仔细考虑,以确保评估结果的准确性。
🖼️ 关键图片
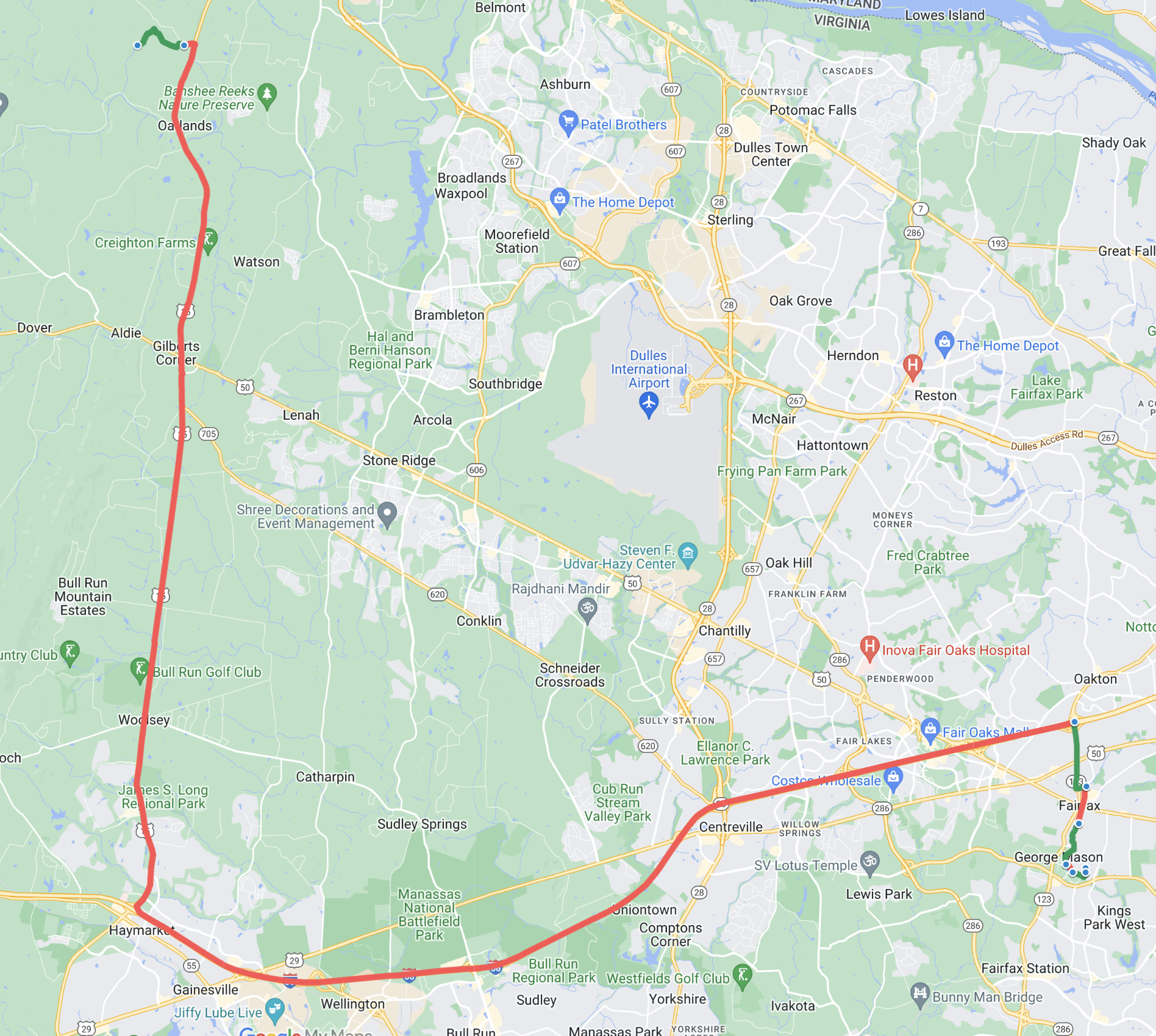
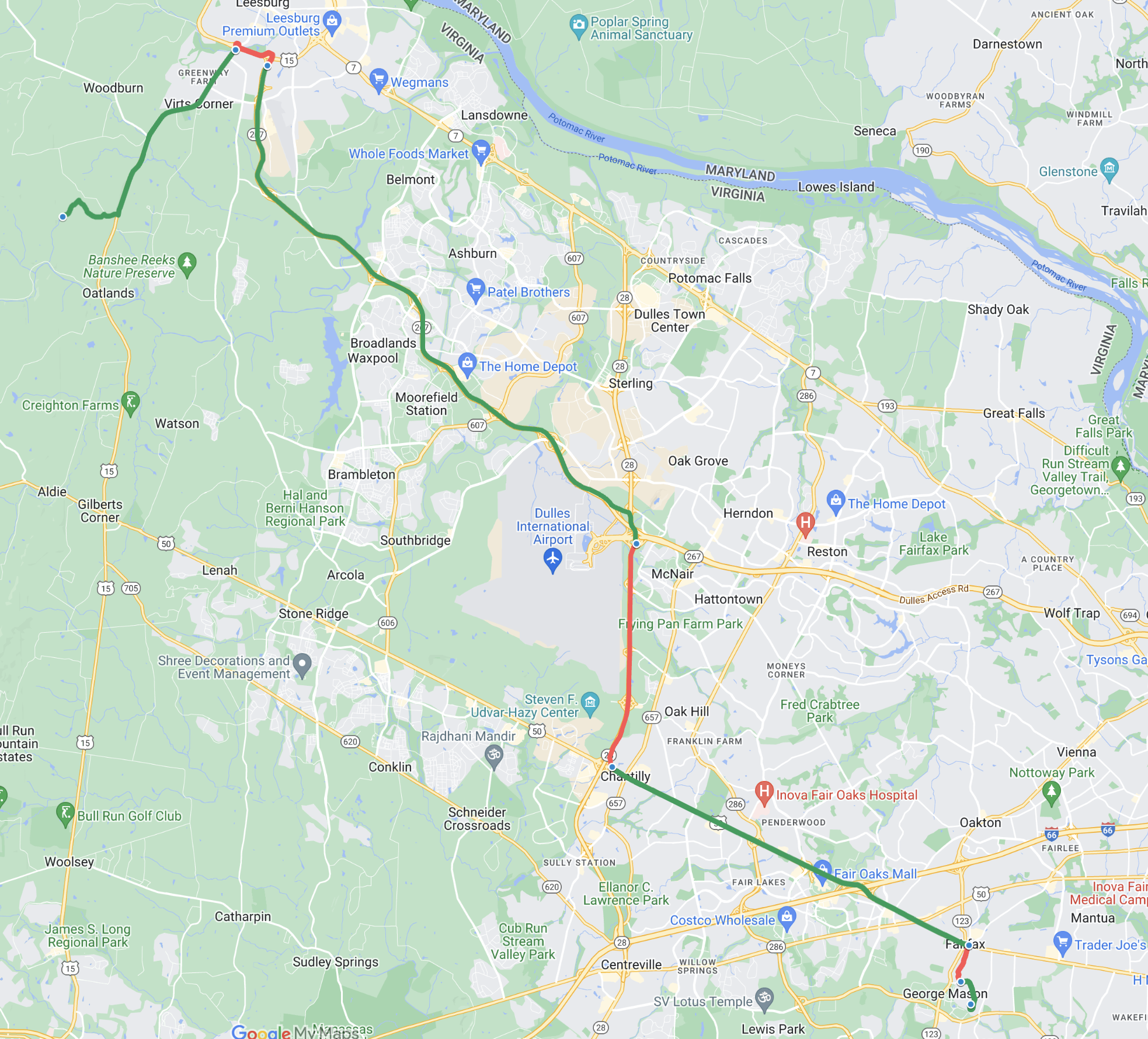
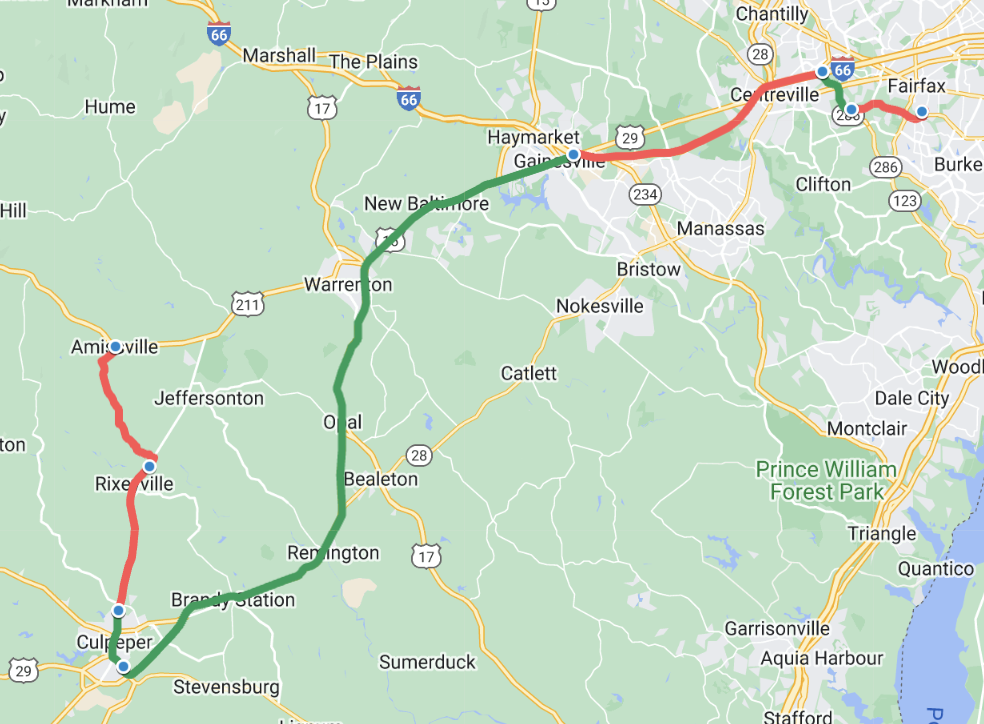
📊 实验亮点
实验结果表明,所有被测试的LLM在所有六个真实世界路径规划场景中都表现出不可靠性,出现了大量的错误。这直接揭示了当前LLM在实际路径规划应用中的局限性,强调了进一步研究和改进的必要性。具体的错误类型和频率未在摘要中详细说明。
🎯 应用场景
该研究结果对车辆导航系统、机器人导航、以及其他需要路径规划的领域具有重要意义。它提醒开发者在将LLM应用于这些领域时需要谨慎,并强调了开发更可靠的路径规划算法的重要性。未来的研究可以集中在如何提高LLM的现实感知能力和推理能力,使其能够更好地适应真实世界的复杂环境。
📄 摘要(原文)
As large language models (LLMs) increasingly integrate into vehicle navigation systems, understanding their path-planning capability is crucial. We tested three LLMs through six real-world path-planning scenarios in various settings and with various difficulties. Our experiments showed that all LLMs made numerous errors in all scenarios, revealing that they are unreliable path planners. We suggest that future work focus on implementing mechanisms for reality checks, enhancing model transparency, and developing smaller models.