From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
作者: Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, Huan Liu
分类: cs.AI, cs.CL
发布日期: 2024-11-25 (更新: 2025-09-29)
备注: EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
探索LLM作为裁判:机遇、挑战与未来方向的全面综述
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM裁判 人工智能评估 自然语言处理 基准测试 机器翻译评估 文本生成评估
📋 核心要点
- 传统AI评估方法在开放和动态场景中表现不足,无法有效处理复杂任务。
- 论文综述了“LLM-as-a-judge”范式,利用LLM进行评分、排名和选择,以提升评估效果。
- 论文系统地分析了LLM裁判的三个维度:评估对象、评估方法和基准测试,并指出了未来方向。
📝 摘要(中文)
评估和评价一直是人工智能(AI)和自然语言处理(NLP)领域中的关键挑战。传统方法,通常是基于匹配或基于小型模型的方法,在开放式和动态场景中常常表现不足。大型语言模型(LLM)的最新进展激发了“LLM-as-a-judge”的范式,即利用LLM对各种机器学习评估场景进行评分、排名或选择。本文对基于LLM的判断和评估进行了全面的综述,提供了对这个不断发展的领域的深入概述。我们首先从输入和输出的角度给出了定义。然后,我们引入了一个系统的分类法,从三个维度探讨LLM-as-a-judge:判断什么、如何判断以及如何进行基准测试。最后,我们还强调了这个新兴领域面临的关键挑战和有希望的未来方向。更多关于LLM-as-a-judge的资源可在网站https://llm-as-a-judge.github.io和https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge上找到。
🔬 方法详解
问题定义:论文旨在解决人工智能和自然语言处理领域中评估和评价的难题。传统方法,如基于匹配或小型模型的方法,在处理开放式和动态场景时存在局限性,无法准确评估复杂任务的性能。这些方法难以适应快速变化的环境和多样化的评估需求。
核心思路:论文的核心思路是探索和综述“LLM-as-a-judge”范式,即利用大型语言模型(LLM)作为评估者,对各种机器学习任务进行评分、排名或选择。这种方法旨在利用LLM强大的语言理解和生成能力,提供更全面、更准确的评估结果。通过模仿人类专家的判断过程,LLM可以更好地捕捉任务的细微差别和复杂性。
技术框架:论文采用系统性的分类方法来研究LLM-as-a-judge。首先,从输入和输出的角度定义了LLM裁判的概念。然后,从三个维度对LLM裁判进行了深入分析:(1) What to judge(评估对象):确定需要评估的具体任务或模型。(2) How to judge(评估方法):研究不同的LLM评估策略,如评分、排名、选择等。(3) How to benchmark(基准测试):探讨如何设计有效的基准测试来评估LLM裁判的性能。
关键创新:论文的关键创新在于对LLM-as-a-judge范式的全面综述和系统性分析。它不仅总结了现有的研究成果,还提出了一个清晰的分类框架,帮助研究人员更好地理解和应用LLM裁判。此外,论文还指出了该领域面临的关键挑战和有希望的未来方向,为未来的研究提供了指导。与传统方法相比,LLM裁判能够处理更复杂的评估任务,并提供更细粒度的评估结果。
关键设计:论文本身是一篇综述,没有涉及具体的参数设置、损失函数或网络结构。然而,它讨论了LLM裁判在不同评估任务中的应用,并分析了不同评估策略的优缺点。未来的研究可以关注如何优化LLM裁判的提示工程、如何设计更有效的基准测试,以及如何解决LLM裁判的偏见问题。
🖼️ 关键图片
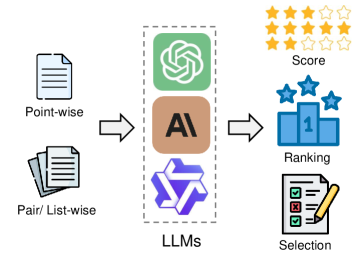

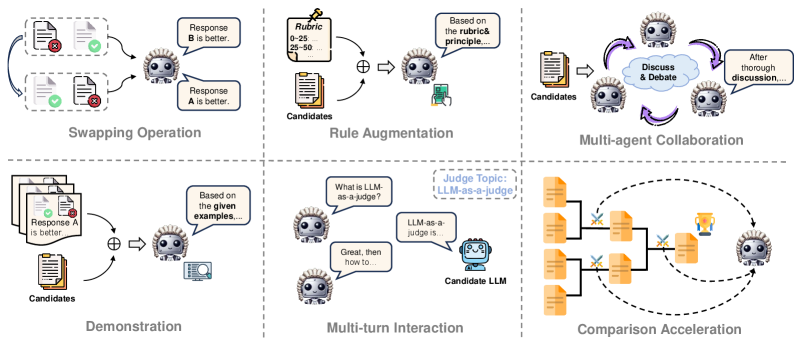
📊 实验亮点
该论文是一篇综述性文章,主要贡献在于对LLM-as-a-judge领域进行了系统性的梳理和分析,并提出了未来研究方向。虽然没有具体的实验数据,但它为研究人员提供了一个全面的视角,帮助他们了解该领域的现状和发展趋势。该综述总结了现有方法,并指出了LLM作为裁判的潜力与挑战。
🎯 应用场景
LLM-as-a-judge具有广泛的应用前景,可用于自动评估机器翻译质量、生成文本的流畅性和创造性、对话系统的响应质量等。它还可以应用于教育领域,自动评估学生的作业和考试答案。通过提供更准确、更全面的评估,LLM-as-a-judge可以促进AI技术的进步和应用,并提高各个领域的效率和质量。
📄 摘要(原文)
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). Traditional methods, usually matching-based or small model-based, often fall short in open-ended and dynamic scenarios. Recent advancements in Large Language Models (LLMs) inspire the "LLM-as-a-judge" paradigm, where LLMs are leveraged to perform scoring, ranking, or selection for various machine learning evaluation scenarios. This paper presents a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to review this evolving field. We first provide the definition from both input and output perspectives. Then we introduce a systematic taxonomy to explore LLM-as-a-judge along three dimensions: what to judge, how to judge, and how to benchmark. Finally, we also highlight key challenges and promising future directions for this emerging area. More resources on LLM-as-a-judge are on the website: https://llm-as-a-judge.github.io and https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge.