Deciphering genomic codes using advanced NLP techniques: a scoping review
作者: Shuyan Cheng, Yishu Wei, Yiliang Zhou, Zihan Xu, Drew N Wright, Jinze Liu, Yifan Peng
分类: q-bio.GN, cs.AI
发布日期: 2024-11-25
💡 一句话要点
综述:利用先进NLP技术解读基因组编码,聚焦LLM与Transformer架构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 基因组学 自然语言处理 大型语言模型 Transformer模型 基因组编码 调控注释预测 分词 生物信息学
📋 核心要点
- 现有基因组分析方法难以有效处理大规模、复杂的基因组测序数据。
- 利用NLP技术,特别是LLM和Transformer架构,对基因组数据进行编码和解读。
- 研究表明,分词和Transformer模型能够有效提升基因组数据的处理和理解能力。
📝 摘要(中文)
本综述旨在研究自然语言处理(NLP)技术,特别是大型语言模型(LLM)和Transformer架构,在解读基因组编码中的应用,重点关注分词(tokenization)、Transformer模型和调控注释预测。由于人类基因组测序数据庞大而复杂,给有效分析带来了挑战。本综述评估了最新文献中的数据和模型可访问性,从而更好地理解这些工具在处理基因组测序数据方面的现有能力和局限性。遵循PRISMA指南,我们在多个数据库中进行了范围界定审查。纳入的研究侧重于应用于基因组测序数据分析的NLP方法。结果表明,分词和Transformer模型增强了基因组数据的处理和理解,并可应用于预测转录因子结合位点和染色质可及性等调控注释。NLP和LLM在基因组测序数据解释中的应用是一个有前景的领域,可以简化大规模基因组数据的处理,并更好地理解其复杂结构,从而推动个性化医疗的进步。
🔬 方法详解
问题定义:该论文旨在解决基因组测序数据分析中面临的挑战,即如何有效地处理和理解大规模、复杂的基因组数据。现有方法在处理此类数据时效率较低,难以充分挖掘基因组中的信息。
核心思路:论文的核心思路是将自然语言处理(NLP)技术,特别是大型语言模型(LLM)和Transformer架构,应用于基因组数据的分析。基因组序列可以被视为一种特殊的“语言”,因此可以借鉴NLP领域的技术来进行处理和理解。
技术框架:该综述研究了使用NLP技术处理基因组数据的整体流程,主要包括以下几个阶段:数据预处理(例如,基因组序列的清洗和格式化)、分词(将基因组序列分割成有意义的单元,类似于NLP中的tokenization)、模型训练(使用Transformer等模型学习基因组序列的模式和规律)、以及下游任务(例如,预测基因组的调控注释,如转录因子结合位点)。
关键创新:关键创新在于将NLP领域先进的技术(如Transformer模型)应用于基因组数据的分析。Transformer模型在处理序列数据方面表现出色,能够捕捉基因组序列中的长程依赖关系,从而提高分析的准确性和效率。
关键设计:论文综述了不同研究中使用的分词方法、Transformer模型的结构和参数设置、以及用于训练模型的损失函数等技术细节。例如,一些研究采用了k-mer分词方法,将基因组序列分割成长度为k的片段。另一些研究则使用了预训练的语言模型,并在基因组数据上进行微调。
🖼️ 关键图片
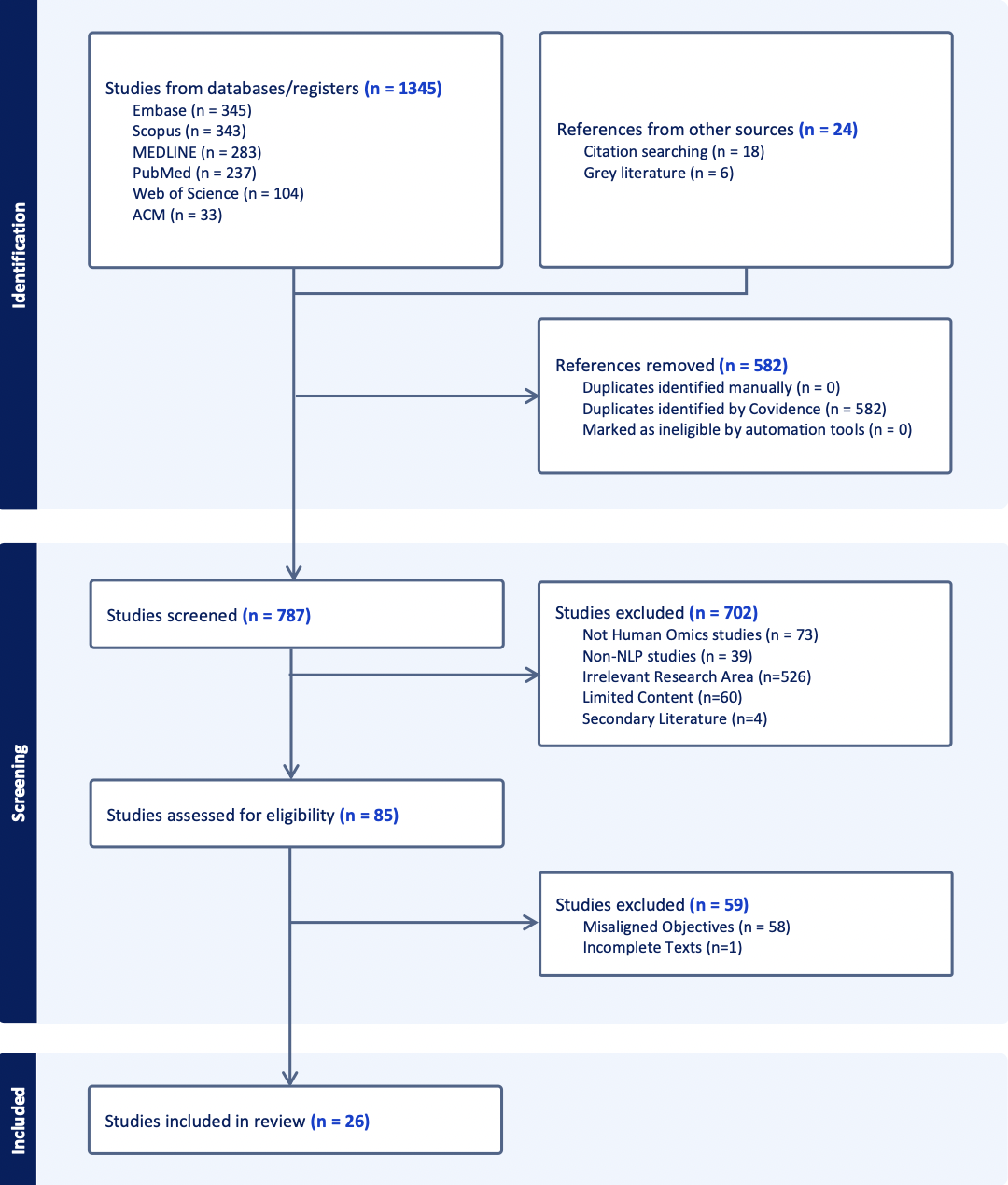
📊 实验亮点
该综述总结了2021年至2024年4月间发表的26项研究,这些研究表明,分词和Transformer模型能够有效增强基因组数据的处理和理解能力,并可应用于预测转录因子结合位点和染色质可及性等调控注释。这为利用NLP技术解决基因组学问题提供了有力的证据。
🎯 应用场景
该研究具有广泛的应用前景,包括:加速基因组数据分析,提高分析效率;更深入地理解基因组的复杂结构和功能;推动个性化医疗的发展,根据个体基因组信息制定更精准的治疗方案;药物研发,通过分析基因组数据发现新的药物靶点。
📄 摘要(原文)
Objectives: The vast and complex nature of human genomic sequencing data presents challenges for effective analysis. This review aims to investigate the application of Natural Language Processing (NLP) techniques, particularly Large Language Models (LLMs) and transformer architectures, in deciphering genomic codes, focusing on tokenization, transformer models, and regulatory annotation prediction. The goal of this review is to assess data and model accessibility in the most recent literature, gaining a better understanding of the existing capabilities and constraints of these tools in processing genomic sequencing data. Methods: Following Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, our scoping review was conducted across PubMed, Medline, Scopus, Web of Science, Embase, and ACM Digital Library. Studies were included if they focused on NLP methodologies applied to genomic sequencing data analysis, without restrictions on publication date or article type. Results: A total of 26 studies published between 2021 and April 2024 were selected for review. The review highlights that tokenization and transformer models enhance the processing and understanding of genomic data, with applications in predicting regulatory annotations like transcription-factor binding sites and chromatin accessibility. Discussion: The application of NLP and LLMs to genomic sequencing data interpretation is a promising field that can help streamline the processing of large-scale genomic data while also providing a better understanding of its complex structures. It has the potential to drive advancements in personalized medicine by offering more efficient and scalable solutions for genomic analysis. Further research is also needed to discuss and overcome current limitations, enhancing model transparency and applicability.