Reranking partisan animosity in algorithmic social media feeds alters affective polarization
作者: Tiziano Piccardi, Martin Saveski, Chenyan Jia, Jeffrey T. Hancock, Jeanne L. Tsai, Michael Bernstein
分类: cs.CY, cs.AI, cs.HC, cs.SI
发布日期: 2024-11-22 (更新: 2025-11-28)
期刊: Science; Volume 390 | Issue 6776; 27 November 2025
💡 一句话要点
通过重排序算法社交媒体信息流中的党派敌意内容,改变情感极化现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感极化 算法干预 社交媒体 大型语言模型 现场实验
📋 核心要点
- 社交媒体算法对用户情感极化影响显著,但平台垄断研究数据,第三方难以评估算法效果。
- 论文提出一种独立于平台的算法重排序方法,通过调整用户接触到的反民主和党派敌意内容,研究其对情感极化的影响。
- 实验结果表明,改变用户接触到的党派敌意内容,能够显著影响其对对立党派的情感,为算法干预情感极化提供了依据。
📝 摘要(中文)
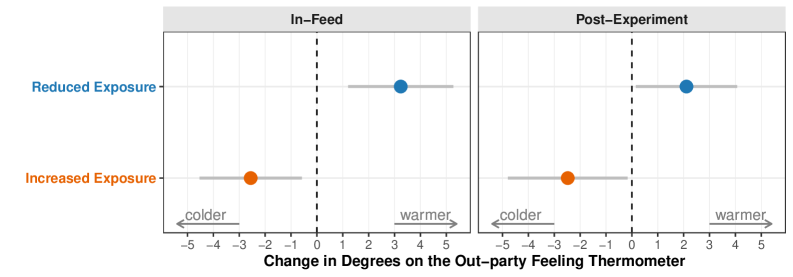
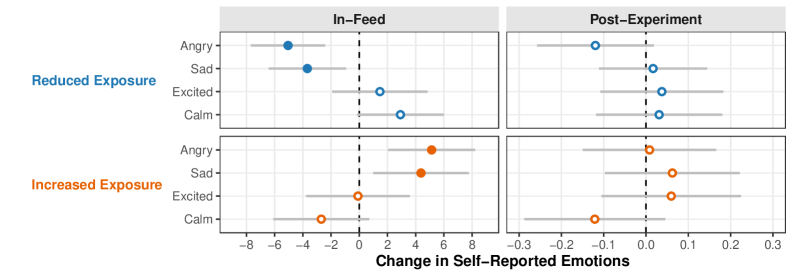
当前,社交媒体平台掌握着研究信息流排序算法影响的绝对权力。我们开发了一种独立于平台的算法,可以实时重排序参与者的信息流。利用该方法,我们在2024年美国总统竞选期间,在X平台上对1256名参与者进行了一项预注册的为期10天的现场实验。我们的实验使用大型语言模型来重排序表达反民主态度和党派敌意(AAPA)的帖子。减少或增加AAPA内容的暴露,使对立党派的党派敌意在100分的情感温度计上移动了两个点。各党派之间没有明显的差异,这为暴露于AAPA内容会改变情感极化提供了因果证据。这项工作建立了一种无需平台合作即可研究信息流算法的方法,从而能够在自然环境中独立评估排序干预措施。
🔬 方法详解
问题定义:论文旨在解决社交媒体算法如何影响用户情感极化的问题。现有研究依赖于平台提供的数据,第三方研究者难以独立评估算法的影响。此外,现有方法难以在自然环境中进行干预实验,无法有效验证算法对用户情感的因果影响。
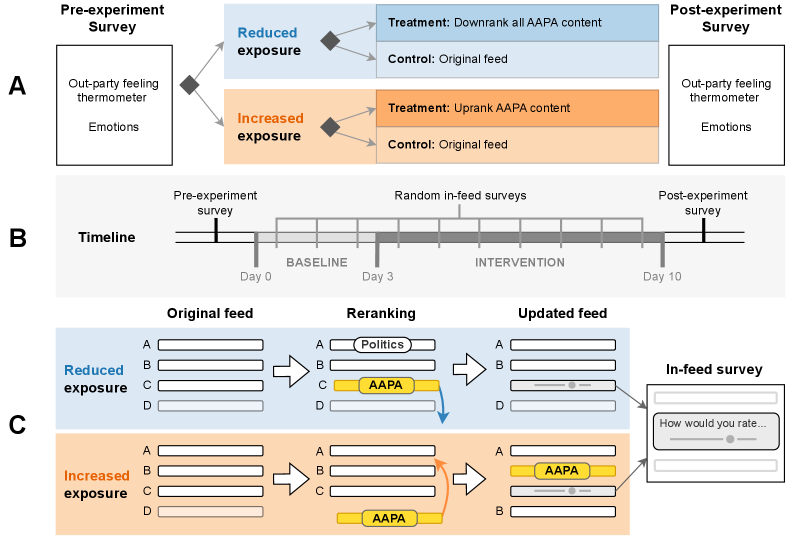
核心思路:论文的核心思路是通过开发一种独立于平台的算法重排序方法,实时干预用户在社交媒体上看到的信息流,从而研究不同类型内容(特别是反民主和党派敌意内容)对用户情感极化的影响。这种方法允许研究者在自然环境中进行可控的实验,并建立因果关系。
技术框架:该研究的技术框架主要包括以下几个部分:1) 开发一个平台独立的算法重排序系统,该系统可以实时拦截并修改用户在X平台上的信息流;2) 使用大型语言模型(LLM)来识别和评估帖子中表达的反民主态度和党派敌意(AAPA);3) 设计一个实验方案,将参与者随机分配到不同的组,分别暴露于不同程度的AAPA内容;4) 通过情感温度计等指标,测量参与者对对立党派的情感变化。
关键创新:该研究的关键创新在于开发了一种独立于平台的算法重排序方法,使得研究者可以在不依赖平台合作的情况下,研究社交媒体算法的影响。这种方法为独立评估排序干预措施提供了可能,并为理解算法对用户情感的因果影响提供了新的视角。
关键设计:实验的关键设计包括:1) 使用大型语言模型对帖子进行AAPA评分,并根据评分进行重排序;2) 将参与者随机分配到不同的实验组,控制AAPA内容的暴露程度;3) 使用情感温度计等指标,量化参与者对对立党派的情感变化;4) 进行预注册,以确保研究的透明度和可重复性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,减少或增加用户接触到的反民主和党派敌意(AAPA)内容,能够显著影响其对对立党派的情感。具体而言,AAPA暴露程度的变化,使对立党派的党派敌意在100分的情感温度计上移动了两个点。该结果为算法干预情感极化提供了有力的因果证据。
🎯 应用场景
该研究成果可应用于评估和改进社交媒体算法,以减少情感极化和社会分裂。独立于平台的算法重排序方法,为第三方机构评估算法的社会影响提供了技术基础。此外,该方法还可用于研究其他类型内容(如虚假信息、仇恨言论)对用户行为的影响,为构建更健康的网络生态系统提供支持。
📄 摘要(原文)
Today, social media platforms hold sole power to study the effects of feed ranking algorithms. We developed a platform-independent method that reranks participants' feeds in real-time and used this method to conduct a preregistered 10-day field experiment with 1,256 participants on X during the 2024 U.S. presidential campaign. Our experiment used a large language model to rerank posts that expressed antidemocratic attitudes and partisan animosity (AAPA). Decreasing or increasing AAPA exposure shifted out-party partisan animosity by two points on a 100-point feeling thermometer, with no detectable differences across party lines, providing causal evidence that exposure to AAPA content alters affective polarization. This work establishes a method to study feed algorithms without requiring platform cooperation, enabling independent evaluation of ranking interventions in naturalistic settings.