MAS-Attention: Memory-Aware Stream Processing for Attention Acceleration on Resource-Constrained Edge Devices
作者: Mohammadali Shakerdargah, Shan Lu, Chao Gao, Di Niu
分类: cs.DC, cs.AI, cs.PF
发布日期: 2024-11-20 (更新: 2025-05-16)
备注: Accepted to MLSys 2025,
💡 一句话要点
MAS-Attention:面向资源受限边缘设备的内存感知注意力加速方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 注意力机制 边缘计算 异构计算 内存优化 流处理
📋 核心要点
- 注意力机制在基础模型中至关重要,但其计算和内存复杂度随上下文长度呈平方级增长,对边缘设备构成挑战。
- MAS-Attention通过并行利用边缘设备上的异构计算单元(向量和矩阵处理单元),并采用多层分块策略,优化注意力计算。
- 实验结果表明,MAS-Attention在边缘计算场景中,相比FLAT方法,速度提升高达2.75倍,能耗降低54%。
📝 摘要(中文)
基础模型的出现彻底改变了各个领域,在计算语言学、计算机视觉和其他领域实现了前所未有的任务准确性和灵活性。注意力机制已成为基础模型的重要组成部分,因为它具有出色的序列相关性捕获能力。然而,随着上下文长度的增加,注意力机制在内存和计算方面的复杂度呈二次方增长。尽管已经为数据中心级GPU和加速器开发了许多基于融合的精确注意力加速算法,利用了多核并行性和数据局部性,但在计算单元有限且片上缓存严格的资源受限边缘神经加速器上加速注意力仍然是一个重大挑战。本文提出了一种在内存受限的边缘加速器上进行精确注意力推理加速的方案,通过并行化利用异构计算单元(即向量处理单元和矩阵处理单元)。我们的方法包括将工作负载调度到这些不同的计算单元中,采用多层分块方案,将注意力中的分块向量工作负载和矩阵工作负载作为两个流进行处理,同时考虑工作负载的依赖关系。我们搜索分块因子以最大化两个计算单元的并行化,同时考虑I/O开销,并提出一种主动缓存覆盖策略,以避免实际中不希望出现的缓存溢出。基于开源仿真框架的广泛结果表明,与边缘计算场景中最先进的注意力融合方法(FLAT)相比,速度提高了2.75倍,能耗降低了54%。在真实世界的边缘神经处理单元上的进一步实验表明,与FLAT相比,注意力的速度提高了1.76倍,且不影响模型输出的准确性。
🔬 方法详解
问题定义:论文旨在解决在资源受限的边缘设备上高效执行注意力机制的问题。现有方法,如FLAT,虽然在数据中心级GPU上表现良好,但无法充分利用边缘设备上有限的计算资源和内存,导致性能瓶颈。尤其是在边缘设备上,内存访问延迟和I/O开销成为限制注意力机制加速的关键因素。
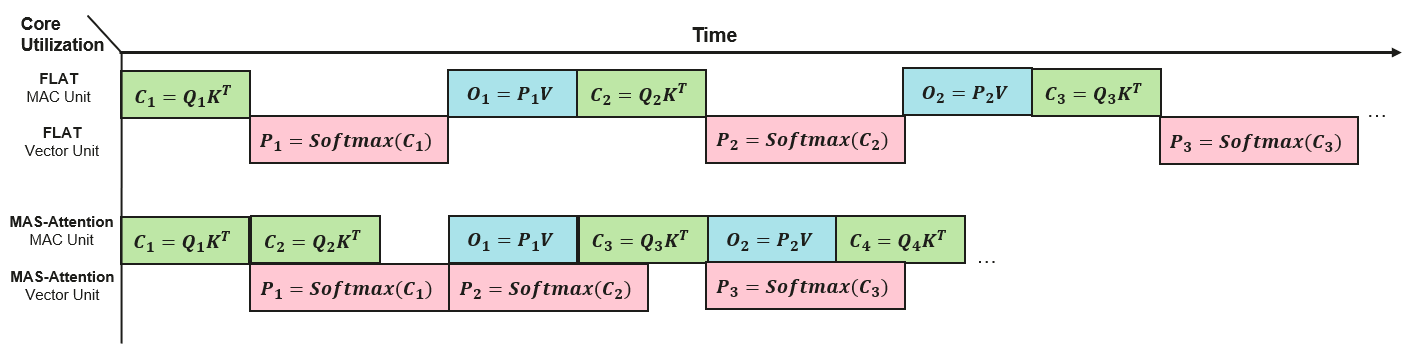
核心思路:论文的核心思路是通过并行化利用边缘设备上的异构计算单元(向量处理单元和矩阵处理单元),并采用多层分块策略,将注意力计算分解为多个流,从而最大化计算单元的利用率,并减少内存访问开销。这种方法旨在充分利用边缘设备的硬件特性,实现高效的注意力加速。
技术框架:MAS-Attention的技术框架主要包含以下几个阶段:1) 工作负载分析:分析注意力计算中的向量和矩阵操作,确定计算依赖关系。2) 多层分块:将向量和矩阵工作负载划分为多个tile,以便在不同的计算单元上并行处理。3) 异构计算单元调度:根据tile的大小和计算依赖关系,将tile调度到向量处理单元和矩阵处理单元上。4) 主动缓存覆盖:设计缓存管理策略,避免不必要的缓存溢出,减少内存访问延迟。
关键创新:MAS-Attention的关键创新在于其内存感知的流处理方法,该方法能够充分利用边缘设备上的异构计算资源,并通过多层分块和主动缓存覆盖策略,最大限度地减少内存访问开销。与现有方法相比,MAS-Attention能够更好地适应边缘设备的资源限制,实现更高的计算效率。
关键设计:论文的关键设计包括:1) 分块因子搜索:通过搜索最佳的分块因子,最大化计算单元的并行化程度,同时考虑I/O开销。2) 主动缓存覆盖策略:根据计算依赖关系和缓存容量,主动覆盖缓存中的数据,避免不必要的缓存溢出。3) 异构计算单元调度策略:根据tile的大小和计算依赖关系,将tile调度到最合适的计算单元上,实现最佳的计算效率。
🖼️ 关键图片


📊 实验亮点
MAS-Attention在开源仿真框架上的实验结果表明,与最先进的注意力融合方法FLAT相比,速度提高了2.75倍,能耗降低了54%。在真实世界的边缘神经处理单元上的实验表明,与FLAT相比,注意力的速度提高了1.76倍,且不影响模型输出的准确性。这些结果表明MAS-Attention在边缘设备上具有显著的性能优势。
🎯 应用场景
MAS-Attention适用于需要高性能和低功耗的边缘计算应用,例如智能监控、自动驾驶、机器人等。通过加速注意力机制,可以提升这些应用在边缘设备上的推理速度和准确性,从而实现更智能、更高效的边缘计算。
📄 摘要(原文)
The advent of foundation models have revolutionized various fields, enabling unprecedented task accuracy and flexibility in computational linguistics, computer vision and other domains. Attention mechanism has become an essential component of foundation models, due to their superb capability of capturing correlations in a sequence. However, attention results in quadratic complexity in memory and compute as the context length grows. Although many fusion-based exact attention acceleration algorithms have been developed for datacenter-grade GPUs and accelerators leveraging multi-core parallelism and data locality, yet it remains a significant challenge to accelerate attention on resource-constrained edge neural accelerators with limited compute units and stringent on-chip caches. In this paper, we propose a scheme for exact attention inference acceleration on memory-constrained edge accelerators, by parallelizing the utilization of heterogeneous compute units, i.e., vector processing units and matrix processing units. Our method involves scheduling workloads onto these different compute units in a multi-tiered tiling scheme to process tiled vector workloads and matrix workloads in attention as two streams, respecting the workload dependencies. We search for tiling factors to maximize the parallelization of both compute units while considering I/O overhead, and propose a proactive cache overwrite strategy to avoid undesirable cache spills in reality. Extensive results based on open-sourced simulation frameworks show up to 2.75x speedup and 54% reduction in energy consumption as compared to the state-of-the-art attention fusion method (FLAT) in the edge computing scenario. Further experiments on a real-world edge neural processing unit demonstrate speedup of up to 1.76x for attention as compared to FLAT, without affecting model output accuracy.