The Moral Mind(s) of Large Language Models
作者: Avner Seror
分类: cs.CY, cs.AI
发布日期: 2024-11-19 (更新: 2025-04-25)
💡 一句话要点
利用显示偏好理论评估大型语言模型的道德推理一致性与异质性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 道德推理 显示偏好理论 伦理对齐 人工智能伦理
📋 核心要点
- 大型语言模型在伦理敏感任务中的应用日益广泛,但其内在道德偏好和一致性尚不明确。
- 本研究利用显示偏好理论,通过构建道德困境来推断LLM的潜在效用函数,以此评估其道德推理。
- 实验结果表明,LLM在道德推理上存在共享核心,但也存在显著差异,部分模型展现出更灵活的视角。
📝 摘要(中文)
随着大型语言模型(LLMs)越来越多地参与具有伦理和社会风险的任务,一个关键问题出现了:它们是否表现出一种涌现的“道德思维”——一种指导其决策的、一致的道德偏好结构?这种结构在不同模型之间共享的程度如何?为了研究这一点,我们对近40个领先的LLM应用了显示偏好理论的工具,向每个模型展示了许多结构化的道德困境,涵盖了伦理推理的五个基本维度。使用概率理性测试,我们发现来自每个主要提供商的至少一个模型的行为与近似稳定的道德偏好一致,表现得好像受到潜在效用函数的指导。然后,我们估计了这些效用函数,发现大多数模型聚集在道德中立的立场附近。为了进一步描述异质性,我们采用了一种非参数排列方法,构建了一个基于显示偏好模式的概率相似性网络。结果揭示了LLM道德推理中的一个共享核心,但也存在有意义的差异:一些模型表现出跨视角的灵活推理,而另一些模型则坚持更严格的伦理概况。这些发现为评估LLM中的道德一致性提供了一个新的经验视角,并为跨AI系统进行伦理对齐的基准测试提供了一个框架。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)是否具有一致的“道德思维”,以及不同LLM之间道德偏好结构是否存在差异的问题。现有方法难以量化和比较LLMs的道德推理能力,缺乏一种系统性的评估框架。现有方法的痛点在于难以从LLM的实际决策行为中推断其潜在的道德偏好。
核心思路:论文的核心思路是借鉴经济学中的显示偏好理论,将LLM在道德困境中的选择视为其道德偏好的“显示”。通过构建一系列结构化的道德困境,并观察LLM在这些困境中的选择,可以推断出LLM的潜在效用函数,从而量化其道德偏好。这种方法允许研究者以一种相对客观和可比较的方式评估不同LLM的道德推理能力。
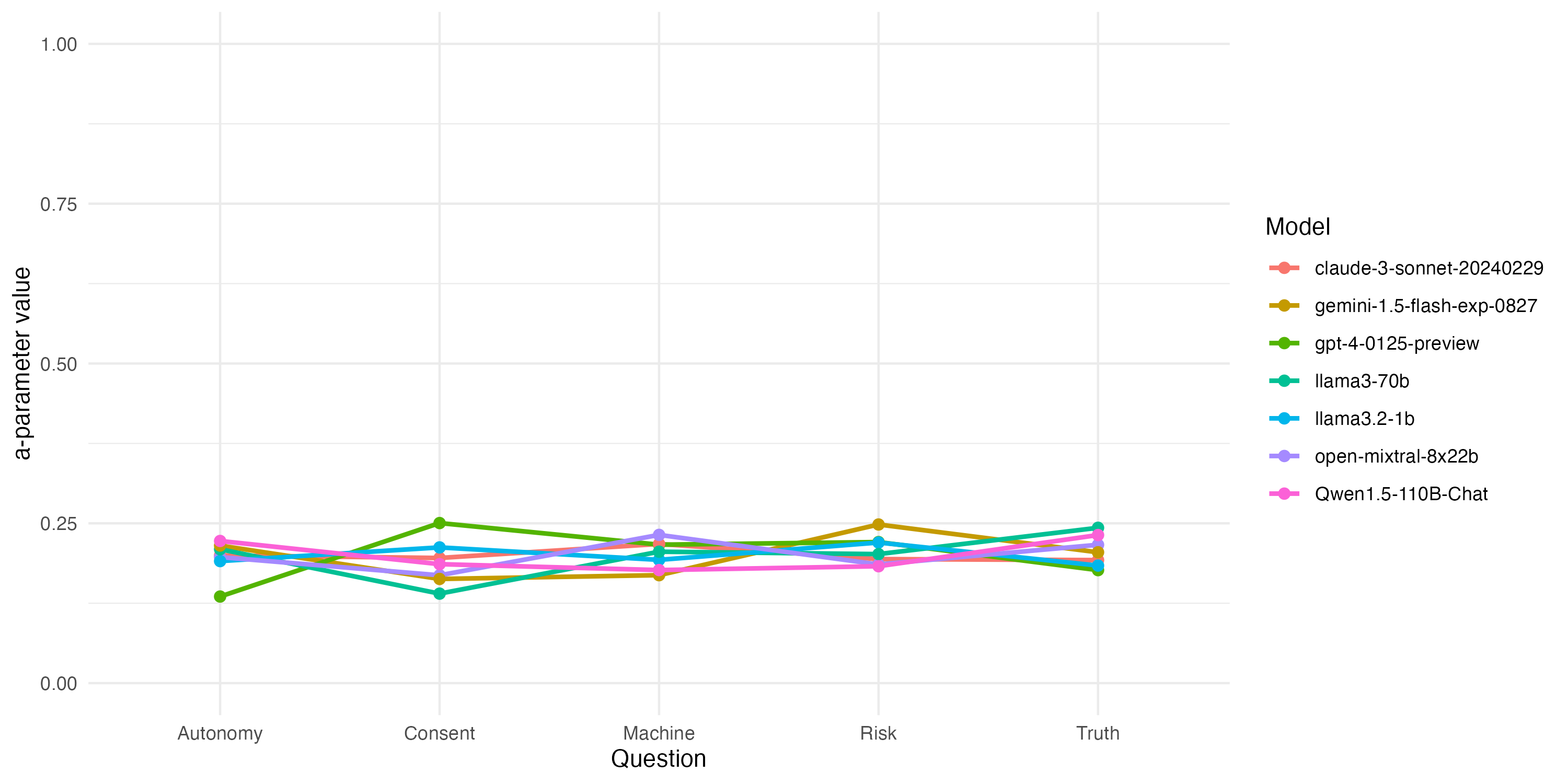
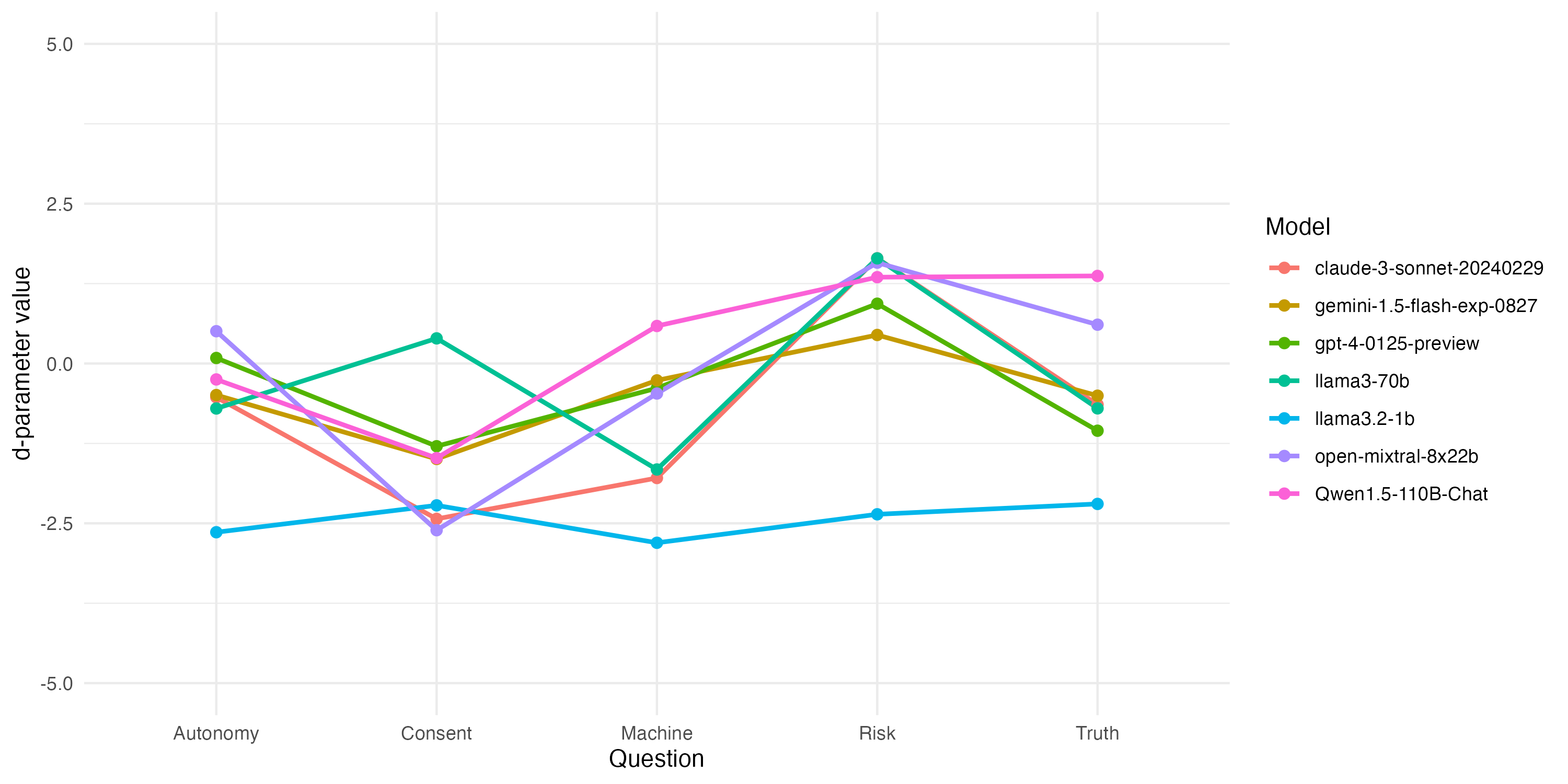
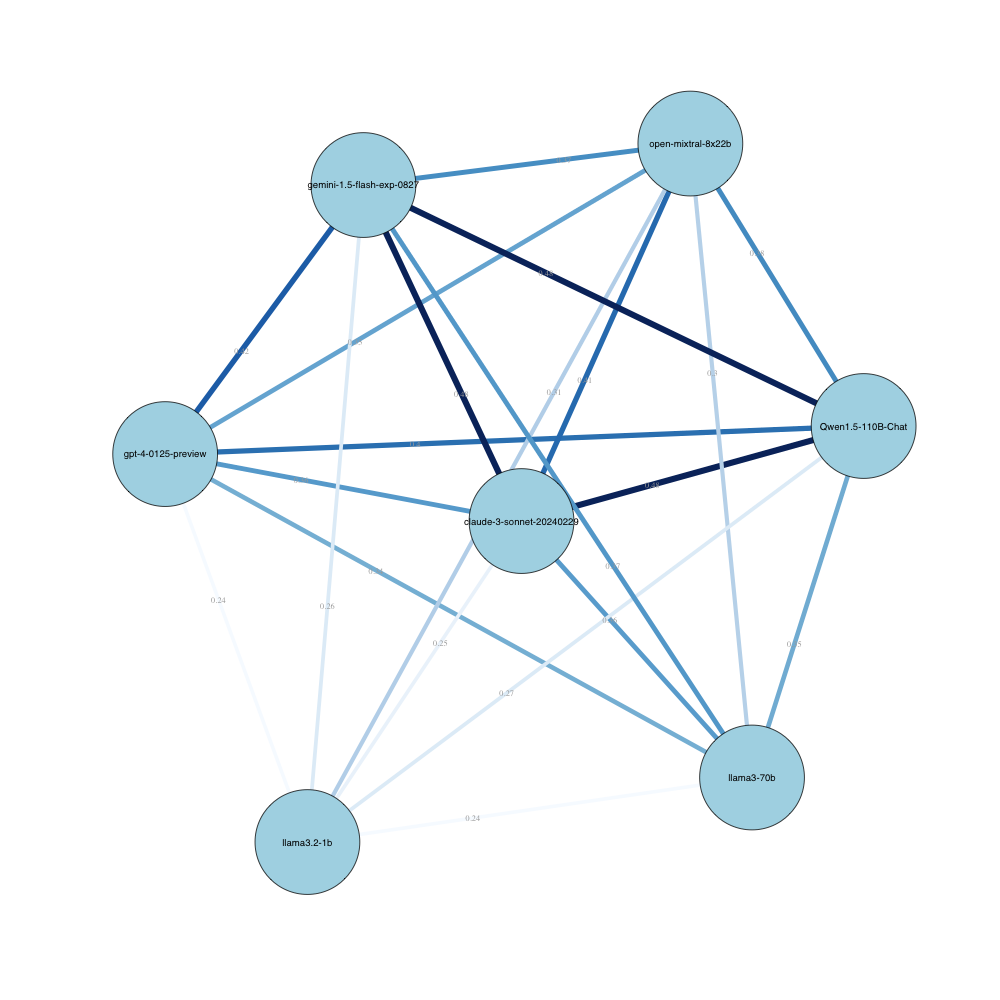
技术框架:整体框架包括以下几个主要阶段: 1. 道德困境构建:设计一系列结构化的道德困境,涵盖伦理推理的五个基本维度(具体维度未知)。 2. LLM决策收集:将这些道德困境呈现给近40个领先的LLM,并记录它们的决策。 3. 理性测试:使用概率理性测试来验证LLM的决策是否与稳定的道德偏好一致。 4. 效用函数估计:如果LLM通过了理性测试,则估计其潜在的效用函数,从而量化其道德偏好。 5. 相似性网络构建:使用非参数排列方法,构建一个基于显示偏好模式的概率相似性网络,以分析不同LLM之间的道德偏好差异。
关键创新:最重要的技术创新点是将显示偏好理论应用于LLM的道德推理评估。与传统的基于规则或基于价值观的伦理评估方法不同,该方法直接从LLM的实际决策行为中推断其潜在的道德偏好,从而避免了主观偏见。此外,该方法还提供了一种量化和比较不同LLM道德推理能力的框架。
关键设计:论文的关键设计包括: 1. 道德困境的设计:确保道德困境具有结构化和可比较性,以便能够准确地推断LLM的道德偏好。 2. 概率理性测试:选择合适的概率理性测试来验证LLM的决策是否与稳定的道德偏好一致(具体测试方法未知)。 3. 效用函数估计方法:选择合适的效用函数估计方法来量化LLM的道德偏好(具体方法未知)。 4. 相似性网络构建方法:选择合适的非参数排列方法来构建概率相似性网络,以分析不同LLM之间的道德偏好差异。
🖼️ 关键图片
📊 实验亮点
研究发现,至少有一个来自每个主要提供商的LLM表现出与稳定道德偏好一致的行为,表明其决策受到潜在效用函数的指导。通过估计这些效用函数,发现大多数模型聚集在道德中立的立场附近。此外,研究还揭示了LLM道德推理中的共享核心和显著差异,一些模型展现出更灵活的视角。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的伦理对齐,确保AI系统在伦理敏感场景中的行为符合人类价值观。此外,该框架可用于开发更安全、更可靠的AI系统,并为AI伦理治理提供理论基础。未来,该方法可扩展到其他类型的AI系统,例如机器人和自动驾驶汽车。
📄 摘要(原文)
As large language models (LLMs) increasingly participate in tasks with ethical and societal stakes, a critical question arises: do they exhibit an emergent "moral mind" - a consistent structure of moral preferences guiding their decisions - and to what extent is this structure shared across models? To investigate this, we applied tools from revealed preference theory to nearly 40 leading LLMs, presenting each with many structured moral dilemmas spanning five foundational dimensions of ethical reasoning. Using a probabilistic rationality test, we found that at least one model from each major provider exhibited behavior consistent with approximately stable moral preferences, acting as if guided by an underlying utility function. We then estimated these utility functions and found that most models cluster around neutral moral stances. To further characterize heterogeneity, we employed a non-parametric permutation approach, constructing a probabilistic similarity network based on revealed preference patterns. The results reveal a shared core in LLMs' moral reasoning, but also meaningful variation: some models show flexible reasoning across perspectives, while others adhere to more rigid ethical profiles. These findings provide a new empirical lens for evaluating moral consistency in LLMs and offer a framework for benchmarking ethical alignment across AI systems.