PerfCodeGen: Improving Performance of LLM Generated Code with Execution Feedback
作者: Yun Peng, Akhilesh Deepak Gotmare, Michael Lyu, Caiming Xiong, Silvio Savarese, Doyen Sahoo
分类: cs.SE, cs.AI, cs.CL, cs.PL
发布日期: 2024-11-18
💡 一句话要点
PerfCodeGen:利用执行反馈提升LLM生成代码的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 性能优化 大型语言模型 运行时反馈 自我完善 软件开发 代码效率 无训练
📋 核心要点
- 现有LLM代码生成评估侧重于功能正确性,忽略了代码效率这一重要方面,无法满足程序员对高性能代码的需求。
- PerfCodeGen通过在LLM的自我完善迭代中融入运行时反馈,指导模型生成更高效的代码,无需额外训练。
- 实验表明,PerfCodeGen显著提升了LLM生成代码的运行时效率,在多个基准测试中达到SOTA,甚至超越了人工编写的参考代码。
📝 摘要(中文)
大型语言模型(LLM)已被广泛应用于辅助软件开发任务,但对其性能评估主要集中在生成代码的功能正确性上。然而,人类程序员不仅要求LLM生成的代码正确,而且要求其具有最佳效率。我们提出了PerfCodeGen,这是一个无需训练的框架,通过将测试用例执行期间的运行时反馈纳入自我完善迭代中,来提高LLM生成代码的性能。与使用复杂提示技巧的基础LLM相比,PerfCodeGen在更高比例的问题上实现了加速。应用于Phi-3-mini等开放语言模型时,PerfCodeGen实现了与GPT-4等强大的闭源模型相当的运行时效率。在HumanEval、MBPP和APPS等基准测试中,我们实现了最先进的运行时效率,在使用GPT-3.5和GPT-4的PerfCodeGen中,经常超过ground truth参考解决方案。此外,我们还证明了我们的方法在提高包括Phi-3-mini、Llama 3 8B、Mixtral 8x7B、Command R和Llama 3 70B在内的一系列不同大小的开放LLM的代码质量方面的有效性。
🔬 方法详解
问题定义:论文旨在解决LLM生成代码效率低下的问题。现有方法主要关注代码的功能正确性,而忽略了代码的运行速度和资源消耗,导致生成的代码在实际应用中可能存在性能瓶颈。
核心思路:论文的核心思路是利用代码执行的运行时反馈来指导LLM进行自我完善。通过测量生成的代码在测试用例上的运行时间,并将这些信息反馈给LLM,使其能够学习到如何生成更高效的代码。这种方法模拟了人类程序员通过测试和调试来优化代码的过程。
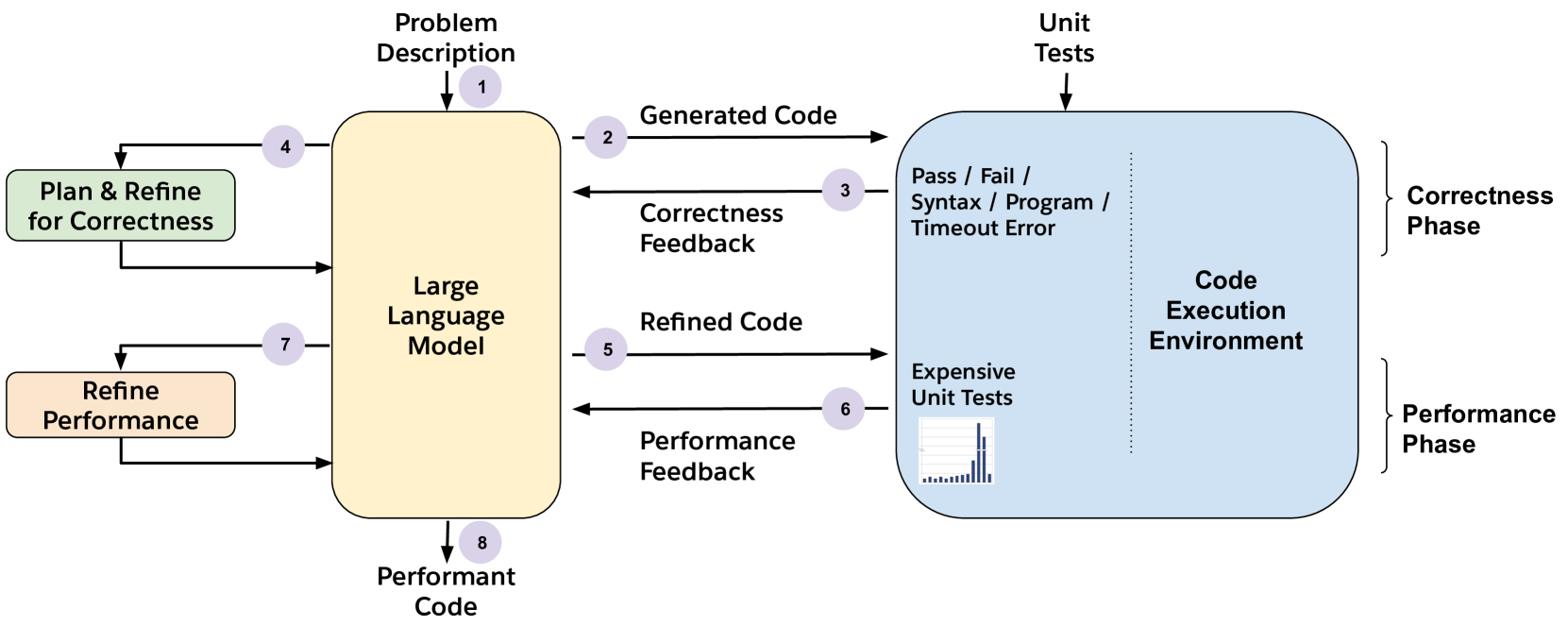
技术框架:PerfCodeGen是一个迭代式的框架,主要包含以下几个阶段:1) LLM生成初始代码;2) 在测试用例上执行生成的代码并测量运行时;3) 将运行时信息作为反馈提供给LLM;4) LLM基于反馈进行代码的自我完善;5) 重复步骤2-4,直到达到预定的迭代次数或性能目标。
关键创新:PerfCodeGen的关键创新在于将运行时反馈融入到LLM的代码生成过程中。与传统的基于静态分析或代码风格的优化方法不同,PerfCodeGen直接利用代码执行的实际性能来指导LLM进行优化,从而能够更有效地提高代码的效率。此外,该方法是无需训练的,可以直接应用于各种预训练的LLM。
关键设计:PerfCodeGen的关键设计包括:1) 如何有效地测量代码的运行时,例如使用时间戳或性能分析工具;2) 如何将运行时信息编码成LLM可以理解的提示,例如使用自然语言描述或数值表示;3) 如何控制迭代的次数和停止条件,以避免过度优化或陷入局部最优。
🖼️ 关键图片
📊 实验亮点
PerfCodeGen在HumanEval、MBPP和APPS等基准测试中取得了显著的性能提升,经常超越ground truth参考解决方案。例如,使用GPT-3.5和GPT-4的PerfCodeGen在多个问题上实现了比人工编写代码更快的运行速度。此外,PerfCodeGen还能够有效提高各种开放LLM(如Phi-3-mini、Llama 3等)的代码质量。
🎯 应用场景
PerfCodeGen具有广泛的应用前景,可以应用于各种软件开发场景,例如自动代码生成、代码优化和代码修复。它可以帮助程序员快速生成高效、可靠的代码,提高开发效率和软件质量。此外,该方法还可以用于教育领域,帮助学生学习如何编写高性能的代码。
📄 摘要(原文)
Large Language Models (LLMs) are widely adopted for assisting in software development tasks, yet their performance evaluations have narrowly focused on the functional correctness of generated code. Human programmers, however, require LLM-generated code to be not only correct but also optimally efficient. We propose PerfCodeGen, a training-free framework that enhances the performance of LLM-generated code by incorporating feedback based on runtime during test case execution into the self-refinement iterations. With PerfCodeGen, we achieve speedups for a significantly higher proportion of problems compared to using the base LLM with sophisticated prompting techniques. Applied to open language models like Phi-3-mini, PerfCodeGen achieves runtime efficiency comparable to prompting powerful closed models like GPT-4. We achieve state-of-the-art runtime efficiency on benchmarks such as HumanEval, MBPP, and APPS, frequently surpassing the ground truth reference solutions with PerfCodeGen using GPT-3.5 and GPT-4. Additionally, we demonstrate the effectiveness of our approach in enhancing code quality across a range of open LLMs of varying sizes including Phi-3-mini, Llama 3 8B, Mixtral 8x7B, Command R, and Llama 3 70B.