Regret-Free Reinforcement Learning for LTL Specifications
作者: Rupak Majumdar, Mahmoud Salamati, Sadegh Soudjani
分类: cs.AI, cs.LG
发布日期: 2024-11-18 (更新: 2025-06-06)
💡 一句话要点
针对未知动态系统的LTL规范,提出无悔强化学习算法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 线性时序逻辑 无悔学习 马尔可夫决策过程 控制器综合
📋 核心要点
- 现有LTL控制算法通常只提供渐近保证,缺乏对学习过程中瞬态性能的评估。
- 论文提出一种无悔在线学习算法,将LTL控制问题转化为可达-避免问题,并独立学习图结构。
- 该算法为LTL控制器综合提供了清晰的性能界限,能够在有限学习阶段评估与最优行为的接近程度。
📝 摘要(中文)
本文针对控制理论中一个重要问题,即学习控制一个具有高级时序规范的未知动态系统,提出了首个无悔在线算法,用于学习线性时序逻辑(LTL)规范下的控制器。假设底层(未知)动态由有限状态和动作马尔可夫决策过程(MDP)建模。核心技术成果是针对MDP上无限视界可达-避免问题的无悔学习算法。对于一般的LTL规范,证明了在图结构已知的情况下,综合问题可以简化为可达-避免问题。此外,提供了一种学习图结构的算法,该算法假定已知最小转移概率,并且独立于主要的无悔算法运行。LTL控制器综合算法提供了在有限数量的学习阶段后,我们与实现最佳行为的接近程度的清晰界限。相比之下,以前的LTL综合算法仅提供渐近保证,无法深入了解学习阶段的瞬态性能。
🔬 方法详解
问题定义:论文旨在解决在未知动态系统下,如何学习满足线性时序逻辑(LTL)规范的控制器。现有LTL控制算法的痛点在于,它们通常只提供渐近收敛保证,无法在学习的早期阶段提供关于性能的可靠信息,即缺乏对瞬态性能的评估。
核心思路:论文的核心思路是将LTL控制器的综合问题分解为两个子问题:首先,将LTL规范下的控制问题转化为一个可达-避免问题;其次,设计一个无悔学习算法来解决这个可达-避免问题。此外,论文还提出了一个独立的算法来学习系统的图结构,从而使整个控制器的学习过程更加高效。这样设计的目的是为了能够提供在有限学习阶段内,控制器性能的明确界限,从而克服现有算法的不足。
技术框架:整体框架包含以下几个主要阶段:1) 将LTL规范转化为可达-避免问题;2) 设计无悔学习算法,在MDP上解决无限视界可达-避免问题;3) 独立学习MDP的图结构,该过程依赖于对最小转移概率的先验知识;4) 将学习到的策略应用于实际系统,并评估其性能。
关键创新:最重要的技术创新点在于提出了一个无悔在线学习算法,该算法能够为LTL控制器综合提供清晰的性能界限,而不仅仅是渐近保证。与现有方法相比,该算法能够在学习的早期阶段提供关于控制器性能的可靠信息,从而更好地指导学习过程。
关键设计:论文的关键设计包括:1) 将LTL规范转化为可达-避免问题的具体方法;2) 无悔学习算法的设计,需要仔细选择合适的探索-利用策略,以保证算法的收敛性和性能;3) 图结构学习算法的设计,需要考虑如何有效地利用对最小转移概率的先验知识,以加速学习过程。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
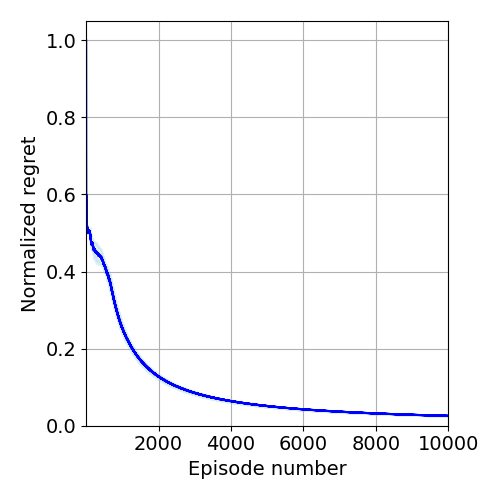
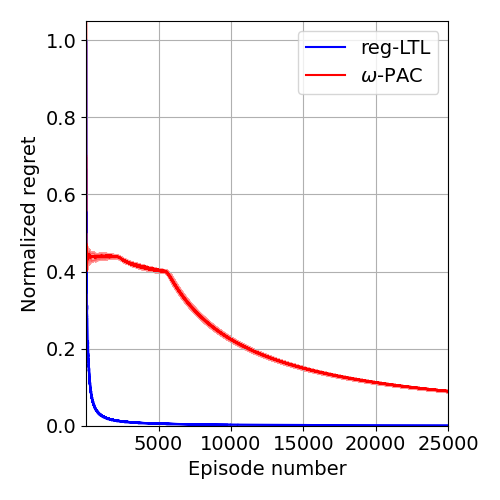
📊 实验亮点
论文的主要亮点在于提出了首个针对LTL规范的无悔强化学习算法,并提供了在有限学习阶段内,控制器性能的明确界限。与之前的算法相比,该算法不仅提供了渐近保证,还能够评估学习过程中的瞬态性能,从而更好地指导学习过程。具体的性能数据、对比基线和提升幅度需要在论文中查找(未知)。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、任务规划等领域,尤其是在需要满足复杂时序约束的场景下。例如,可以用于开发能够安全高效地完成特定任务的机器人,或者用于设计能够满足交通规则和乘客舒适度要求的自动驾驶系统。该研究的实际价值在于提高了控制系统的可靠性和安全性,并为未来的自主系统设计提供了新的思路。
📄 摘要(原文)
Learning to control an unknown dynamical system with respect to high-level temporal specifications is an important problem in control theory. We present the first regret-free online algorithm for learning a controller for linear temporal logic (LTL) specifications for systems with unknown dynamics. We assume that the underlying (unknown) dynamics is modeled by a finite-state and action Markov decision process (MDP). Our core technical result is a regret-free learning algorithm for infinite-horizon reach-avoid problems on MDPs. For general LTL specifications, we show that the synthesis problem can be reduced to a reach-avoid problem once the graph structure is known. Additionally, we provide an algorithm for learning the graph structure, assuming knowledge of a minimum transition probability, which operates independently of the main regret-free algorithm. Our LTL controller synthesis algorithm provides sharp bounds on how close we are to achieving optimal behavior after a finite number of learning episodes. In contrast, previous algorithms for LTL synthesis only provide asymptotic guarantees, which give no insight into the transient performance during the learning phase.