Harnessing multiple LLMs for Information Retrieval: A case study on Deep Learning methodologies in Biodiversity publications
作者: Vamsi Krishna Kommineni, Birgitta König-Ries, Sheeba Samuel
分类: cs.IR, cs.AI
发布日期: 2024-11-14
💡 一句话要点
利用多LLM进行信息检索:生物多样性出版物中深度学习方法案例研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息检索 大型语言模型 深度学习 生物多样性 检索增强生成 多模型集成 自动化信息提取
📋 核心要点
- 现有深度学习方法细节隐藏在非结构化文本中,难以获取和理解,阻碍了知识传播和复现。
- 提出一种基于多LLM和RAG的流程,从科学出版物中自动提取和处理深度学习方法细节。
- 在生物多样性出版物数据集上验证,仅基于文本内容实现了69.5%的准确率,提升了信息检索效果。
📝 摘要(中文)
深度学习(DL)技术越来越多地应用于各个领域的科学研究中,以解决复杂的研究问题。然而,这些DL模型的具体方法细节通常隐藏在非结构化文本中,导致关于模型设计、训练和评估的关键信息难以获取和理解。为了解决这个问题,本文结合检索增强生成(RAG)方法,使用五个不同的开源大型语言模型(LLM):Llama-3 70B、Llama-3.1 70B、Mixtral-8x22B-Instruct-v0.1、Mixtral 8x7B和Gemma 2 9B,自动提取和处理科学出版物中的DL方法细节。我们从五个LLM的输出构建了一个投票分类器,以准确报告DL方法信息。我们使用生物多样性出版物测试了我们的方法,并在我们之前的研究基础上进行了改进。为了验证我们的流程,我们使用了两个与DL相关的生物多样性出版物数据集:一个来自我们先前工作的100个出版物的精选集和一个来自《生态信息学》杂志的364个出版物的集合。结果表明,多LLM、RAG辅助的流程增强了DL方法信息的检索,仅基于出版物中的文本内容,实现了69.5%的准确率(600次比较中有417次)。该性能是根据可以访问代码、图表、表格和其他补充信息的人工注释者进行评估的。虽然在生物多样性领域进行了演示,但我们的方法并不局限于该领域;它可以应用于其他科学领域,在这些领域中,详细的方法报告对于推进知识和确保可重复性至关重要。这项研究提出了一种可扩展且可靠的自动化信息提取方法,有助于更好地实现研究的可重复性和知识转移。
🔬 方法详解
问题定义:论文旨在解决科学出版物中深度学习方法细节难以提取和理解的问题。现有方法主要依赖人工阅读和分析,效率低下且容易出错。此外,深度学习模型的具体设计、训练和评估信息往往分散在文本各处,难以系统性地获取。
核心思路:论文的核心思路是利用多个大型语言模型(LLM)的优势,结合检索增强生成(RAG)技术,自动化地从科学出版物中提取深度学习方法信息。通过集成多个LLM的输出,并采用投票分类器,提高信息提取的准确性和鲁棒性。
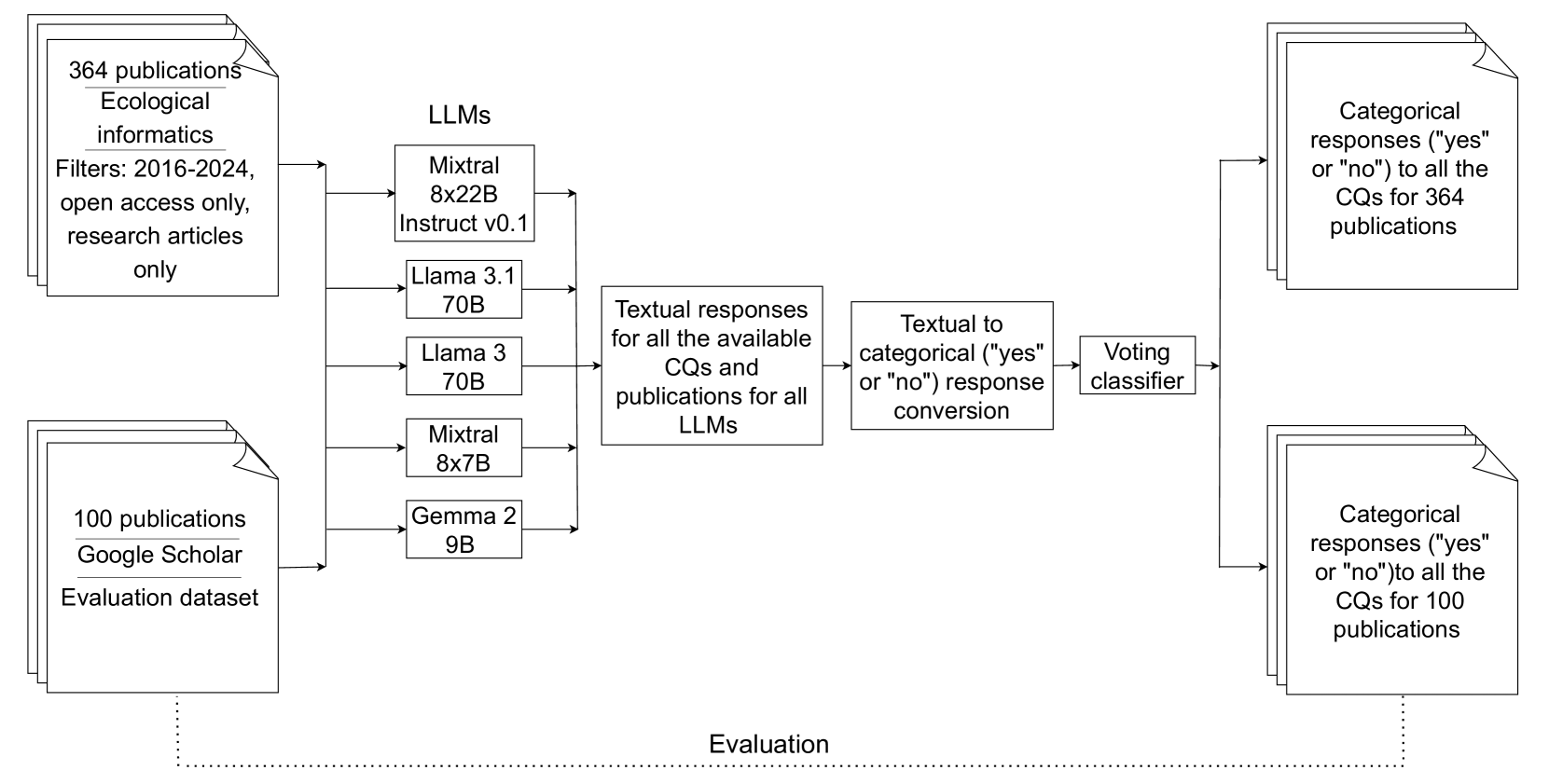
技术框架:该方法的技术框架主要包括以下几个阶段:1) 数据准备:收集和整理包含深度学习方法描述的科学出版物;2) LLM推理:使用多个LLM(Llama-3 70B、Llama-3.1 70B、Mixtral-8x22B-Instruct-v0.1、Mixtral 8x7B和Gemma 2 9B)对出版物文本进行分析,提取深度学习方法的相关信息;3) RAG增强:利用检索增强生成技术,从相关文献中检索与当前出版物相关的知识,辅助LLM进行信息提取;4) 投票分类:将多个LLM的输出进行集成,采用投票分类器确定最终的提取结果;5) 评估验证:使用人工标注的数据集对提取结果进行评估,验证方法的准确性和有效性。
关键创新:该方法的主要创新点在于:1) 结合多个LLM进行信息提取,利用不同模型的优势,提高提取的准确性和鲁棒性;2) 采用RAG技术,从相关文献中检索知识,辅助LLM进行信息提取,提高提取的全面性和准确性;3) 构建投票分类器,对多个LLM的输出进行集成,减少单个模型的偏差,提高提取的可靠性。
关键设计:在LLM推理阶段,需要设计合适的prompt,引导LLM提取所需的深度学习方法信息。RAG模块需要选择合适的检索策略和知识库。投票分类器需要选择合适的投票策略,例如多数投票或加权投票。此外,还需要对LLM的输出进行后处理,例如去除冗余信息、纠正错误等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在生物多样性出版物数据集上取得了显著的性能提升,仅基于文本内容实现了69.5%的准确率。与人工标注相比,该方法能够自动化地提取深度学习方法信息,大大提高了效率。此外,通过集成多个LLM的输出,该方法能够有效地减少单个模型的偏差,提高提取的可靠性。
🎯 应用场景
该研究成果可应用于多个领域,包括生物多样性、医学、材料科学等,用于自动化提取和分析科学文献中的方法信息。这有助于研究人员快速了解和比较不同研究的方法细节,促进知识共享和技术创新,并提高研究的可重复性。未来,该方法可扩展到其他类型的信息提取任务,例如提取实验参数、数据集信息等。
📄 摘要(原文)
Deep Learning (DL) techniques are increasingly applied in scientific studies across various domains to address complex research questions. However, the methodological details of these DL models are often hidden in the unstructured text. As a result, critical information about how these models are designed, trained, and evaluated is challenging to access and comprehend. To address this issue, in this work, we use five different open-source Large Language Models (LLMs): Llama-3 70B, Llama-3.1 70B, Mixtral-8x22B-Instruct-v0.1, Mixtral 8x7B, and Gemma 2 9B in combination with Retrieval-Augmented Generation (RAG) approach to extract and process DL methodological details from scientific publications automatically. We built a voting classifier from the outputs of five LLMs to accurately report DL methodological information. We tested our approach using biodiversity publications, building upon our previous research. To validate our pipeline, we employed two datasets of DL-related biodiversity publications: a curated set of 100 publications from our prior work and a set of 364 publications from the Ecological Informatics journal. Our results demonstrate that the multi-LLM, RAG-assisted pipeline enhances the retrieval of DL methodological information, achieving an accuracy of 69.5% (417 out of 600 comparisons) based solely on textual content from publications. This performance was assessed against human annotators who had access to code, figures, tables, and other supplementary information. Although demonstrated in biodiversity, our methodology is not limited to this field; it can be applied across other scientific domains where detailed methodological reporting is essential for advancing knowledge and ensuring reproducibility. This study presents a scalable and reliable approach for automating information extraction, facilitating better reproducibility and knowledge transfer across studies.