AstroM$^3$: A self-supervised multimodal model for astronomy
作者: Mariia Rizhko, Joshua S. Bloom
分类: astro-ph.IM, cs.AI
发布日期: 2024-11-13
💡 一句话要点
AstroM$^3$:面向天文领域的多模态自监督学习模型,提升分类性能并支持多种下游任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 自监督学习 天文数据 时间序列分析 光谱分析 对比学习 天体分类
📋 核心要点
- 现有天文机器学习模型通常仅限于单一数据源(图像或时间序列),或少量元数据,忽略了多模态观测数据的潜力。
- AstroM$^3$通过扩展CLIP模型到三模态,融合时间序列光度数据、光谱和天体物理元数据,实现跨模态的自监督学习。
- 实验表明,AstroM$^3$显著提升了时间序列光度数据的分类准确率,尤其在标记数据稀缺时表现更佳,并支持多种下游任务。
📝 摘要(中文)
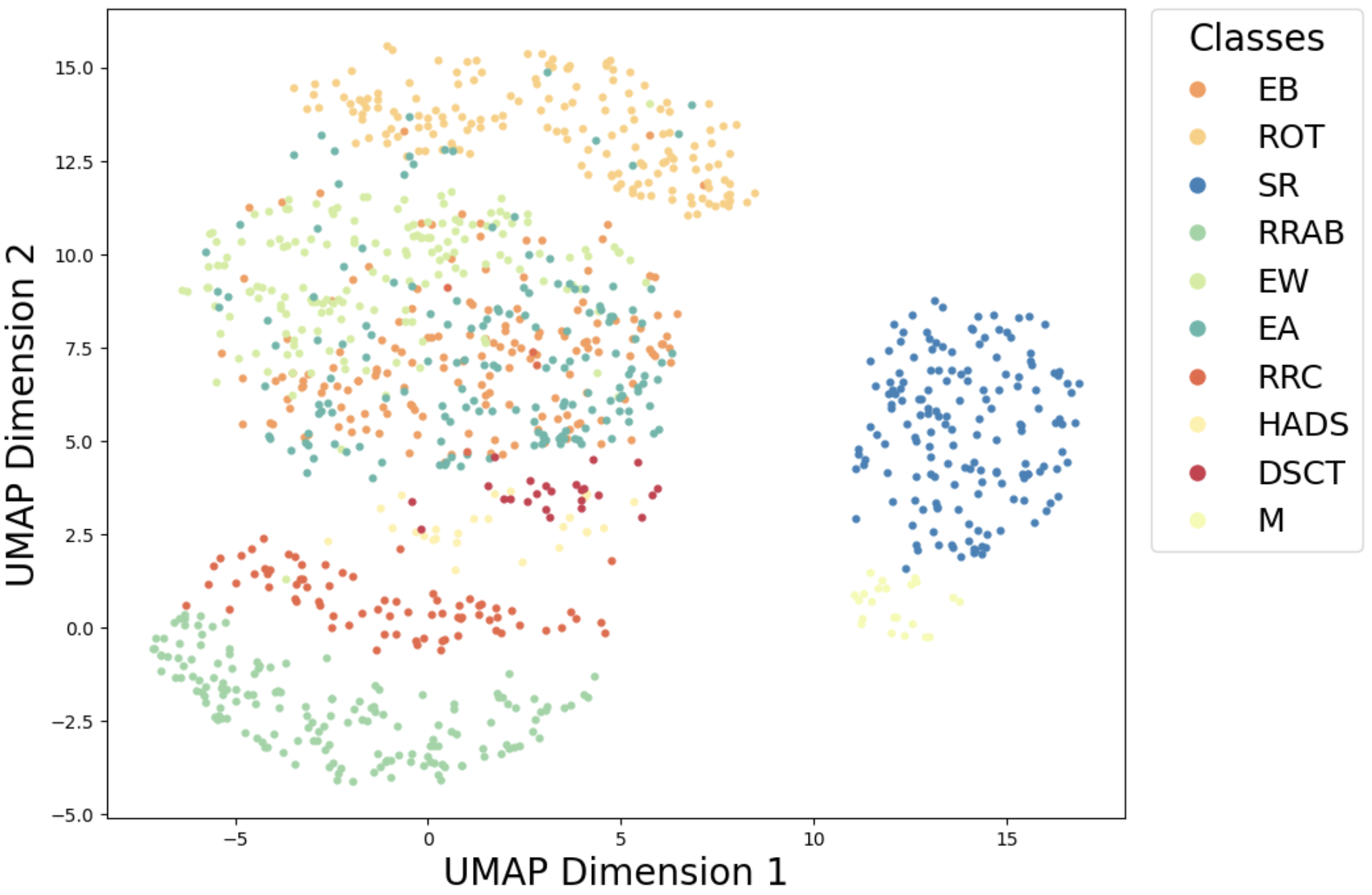
本文构建了一个天文多模态数据集,并提出了AstroM$^3$,一种自监督预训练方法,使模型能够同时从多种模态中学习。具体来说,作者将CLIP(对比语言-图像预训练)模型扩展到三模态设置,从而能够整合时间序列光度数据、光谱和天体物理元数据。在有监督的微调设置中,结果表明CLIP预训练提高了时间序列光度数据的分类性能,准确率从84.6%提高到91.5%。此外,当标记数据的可用性有限时,CLIP将分类准确率提高了高达12.6%,表明了利用更大的未标记语料库的有效性。除了微调分类之外,还可以将训练后的模型用于在构建自监督模型期间未明确考虑的其他下游任务。特别地,作者展示了使用学习到的嵌入进行错误分类识别、相似性搜索和异常检测的有效性。一个令人惊讶的亮点是使用流形学习和降维算法“重新发现”了米拉变星亚型和两个旋转变星亚类。据作者所知,这是天文领域中第一个构建 $n>2$ 模式的模型。这种方法自然可以预期扩展到 $n>3$ 模式。
🔬 方法详解
问题定义:现有天文机器学习方法主要依赖单一模态的数据,例如图像或时间序列,忽略了不同模态数据之间的互补信息。这限制了模型的性能和泛化能力,尤其是在数据标注成本高昂的天文领域,如何有效利用大量未标注的多模态数据是一个挑战。
核心思路:本文的核心思路是将CLIP模型扩展到天文领域的多模态数据,利用自监督学习的方式,让模型能够同时从时间序列光度数据、光谱和天体物理元数据中学习。通过对比学习,模型学习到不同模态数据之间的关联性,从而提升模型的表征能力和泛化性能。
技术框架:AstroM$^3$基于CLIP模型,主要包含三个模态的编码器:时间序列光度数据编码器、光谱编码器和元数据编码器。每个编码器将对应模态的数据映射到共享的嵌入空间。模型使用对比损失函数,鼓励来自同一天体的数据在嵌入空间中更接近,而来自不同天体的数据则更远离。预训练完成后,可以使用学习到的嵌入进行下游任务,如分类、相似性搜索和异常检测。
关键创新:AstroM$^3$的关键创新在于将CLIP模型扩展到天文领域,并成功地融合了三种不同的数据模态。这是天文领域中首次构建 $n>2$ 模式的模型。通过自监督学习,模型能够有效地利用未标注的多模态数据,从而提升模型的性能和泛化能力。
关键设计:时间序列光度数据编码器使用Transformer结构,光谱编码器使用卷积神经网络,元数据编码器使用全连接网络。对比损失函数采用InfoNCE损失,温度参数设置为0.07。在微调阶段,使用交叉熵损失函数进行分类任务的训练。模型使用AdamW优化器进行训练,学习率设置为1e-4,权重衰减设置为0.01。
🖼️ 关键图片


📊 实验亮点
实验结果表明,AstroM$^3$在时间序列光度数据分类任务中,准确率从84.6%提升至91.5%。在标记数据有限的情况下,分类准确率提升高达12.6%。此外,该模型成功地“重新发现”了米拉变星亚型和两个旋转变星亚类,验证了其在天文研究中的有效性。
🎯 应用场景
AstroM$^3$可应用于多种天文研究场景,例如天体分类、变星识别、异常天体探测等。该模型能够有效利用多模态数据,提升分类精度和泛化能力,尤其在标记数据稀缺的情况下。此外,学习到的嵌入可以用于相似性搜索和异常检测,辅助天文学家发现新的天体类型和现象。未来,该方法可以扩展到更多模态的数据,例如图像数据和射电数据,进一步提升天文研究的效率和精度。
📄 摘要(原文)
While machine-learned models are now routinely employed to facilitate astronomical inquiry, model inputs tend to be limited to a primary data source (namely images or time series) and, in the more advanced approaches, some metadata. Yet with the growing use of wide-field, multiplexed observational resources, individual sources of interest often have a broad range of observational modes available. Here we construct an astronomical multimodal dataset and propose AstroM$^3$, a self-supervised pre-training approach that enables a model to learn from multiple modalities simultaneously. Specifically, we extend the CLIP (Contrastive Language-Image Pretraining) model to a trimodal setting, allowing the integration of time-series photometry data, spectra, and astrophysical metadata. In a fine-tuning supervised setting, our results demonstrate that CLIP pre-training improves classification performance for time-series photometry, where accuracy increases from 84.6% to 91.5%. Furthermore, CLIP boosts classification accuracy by up to 12.6% when the availability of labeled data is limited, showing the effectiveness of leveraging larger corpora of unlabeled data. In addition to fine-tuned classification, we can use the trained model in other downstream tasks that are not explicitly contemplated during the construction of the self-supervised model. In particular we show the efficacy of using the learned embeddings for misclassifications identification, similarity search, and anomaly detection. One surprising highlight is the "rediscovery" of Mira subtypes and two Rotational variable subclasses using manifold learning and dimension reduction algorithm. To our knowledge this is the first construction of an $n>2$ mode model in astronomy. Extensions to $n>3$ modes is naturally anticipated with this approach.