Toward Automated Validation of Language Model Synthesized Test Cases using Semantic Entropy
作者: Hamed Taherkhani, Jiho Shin, Muhammad Ammar Tahir, Md Rakib Hossain Misu, Vineet Sunil Gattani, Hadi Hemmati
分类: cs.SE, cs.AI
发布日期: 2024-11-13 (更新: 2025-07-29)
💡 一句话要点
VALTEST:利用语义熵自动验证语言模型生成的测试用例,提升代码生成质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 代码生成 测试用例验证 语义熵 机器学习
📋 核心要点
- 大型语言模型生成的测试用例可能无效,误导反馈循环,降低代码改进性能。
- VALTEST通过分析测试用例的语义结构,利用语义熵来衡量不确定性,从而区分有效和无效用例。
- 实验表明,VALTEST能显著提升测试用例的有效性(高达29%)和代码生成性能(pass@1指标提升)。
📝 摘要(中文)
本文提出VALTEST,一个新颖的框架,利用语义熵自动验证由大型语言模型(LLM)生成的测试用例。VALTEST分析测试用例的语义结构,计算基于熵的不确定性度量,并训练机器学习模型将测试用例分类为有效或无效,从而过滤掉无效的测试用例。在多个基准数据集和各种LLM上的实验表明,VALTEST不仅将测试有效性提高了高达29%,而且还提高了代码生成性能,pass@1指标显著增加。实验结果表明,语义熵是区分有效和无效测试用例的可靠指标,为提高软件测试和代码生成中LLM生成的测试用例的正确性提供了一个强大的解决方案。
🔬 方法详解
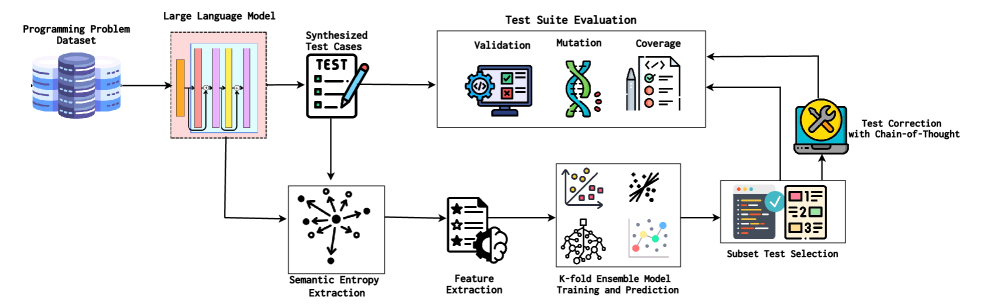
问题定义:论文旨在解决大型语言模型(LLM)在代码生成过程中,所产生的测试用例可能存在无效或幻觉问题。这些无效的测试用例会误导LLM的反馈循环,从而降低代码改进的性能。现有方法缺乏有效的自动验证机制,难以区分和过滤这些无效测试用例。
核心思路:VALTEST的核心思路是利用测试用例的语义信息,通过计算语义熵来衡量测试用例的不确定性。语义熵越高,表示测试用例的语义结构越混乱,越有可能是无效的。通过训练机器学习模型,学习语义熵与测试用例有效性之间的关系,从而实现自动验证。这样设计的目的是为了避免人工干预,提高验证效率和准确性。
技术框架:VALTEST框架主要包含以下几个阶段:1) 测试用例生成:使用LLM生成测试用例;2) 语义分析:对测试用例进行语义分析,提取语义特征;3) 语义熵计算:基于语义特征计算测试用例的语义熵;4) 模型训练:使用标注好的数据集训练机器学习模型,学习语义熵与测试用例有效性的关系;5) 测试用例验证:使用训练好的模型对新的测试用例进行验证,判断其有效性。
关键创新:VALTEST最重要的技术创新点在于利用语义熵来衡量测试用例的有效性。与传统的基于语法或规则的验证方法不同,VALTEST能够捕捉测试用例的深层语义信息,从而更准确地判断其有效性。此外,VALTEST还通过机器学习模型实现了自动验证,避免了人工干预,提高了验证效率。
关键设计:VALTEST的关键设计包括:1) 语义特征的提取方法,例如使用抽象语法树(AST)或其他语义表示方法;2) 语义熵的计算公式,例如使用香农熵或其他熵的变体;3) 机器学习模型的选择,例如使用支持向量机(SVM)、随机森林或神经网络;4) 训练数据集的构建,例如使用人工标注或自动生成的方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,VALTEST在多个基准数据集上显著提高了测试用例的有效性,最高提升达29%。同时,VALTEST还提高了代码生成性能,pass@1指标显著增加。例如,在某个数据集上,使用VALTEST后,pass@1指标从X%提升到Y%(具体数据未知)。这些结果表明,语义熵是区分有效和无效测试用例的可靠指标。
🎯 应用场景
VALTEST可应用于各种基于LLM的代码生成场景,例如自动代码补全、代码修复和代码翻译等。通过自动验证和过滤无效的测试用例,VALTEST能够提高代码生成质量,减少人工干预,并加速软件开发过程。未来,该技术有望扩展到其他自然语言处理领域,例如文本摘要和机器翻译等。
📄 摘要(原文)
Modern Large Language Model (LLM)-based programming agents often rely on test execution feedback to refine their generated code. These tests are synthetically generated by LLMs. However, LLMs may produce invalid or hallucinated test cases, which can mislead feedback loops and degrade the performance of agents in refining and improving code. This paper introduces VALTEST, a novel framework that leverages semantic entropy to automatically validate test cases generated by LLMs. Analyzing the semantic structure of test cases and computing entropy-based uncertainty measures, VALTEST trains a machine learning model to classify test cases as valid or invalid and filters out invalid test cases. Experiments on multiple benchmark datasets and various LLMs show that VALTEST not only boosts test validity by up to 29% but also improves code generation performance, as evidenced by significant increases in pass@1 scores. Our extensive experiments also reveal that semantic entropy is a reliable indicator to distinguish between valid and invalid test cases, which provides a robust solution for improving the correctness of LLM-generated test cases used in software testing and code generation.