Can adversarial attacks by large language models be attributed?
作者: Manuel Cebrian, Andres Abeliuk, Jan Arne Telle
分类: cs.AI, cs.CL, cs.CY, cs.FL
发布日期: 2024-11-12 (更新: 2025-07-29)
备注: 22 pages, 5 figures, 2 tables
💡 一句话要点
研究表明,仅凭LLM输出难以归因对抗攻击,模型数量爆炸加剧了归因难度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 对抗攻击 归因分析 形式语言理论 模型识别
📋 核心要点
- 现有方法难以有效归因大语言模型在对抗环境下的输出,尤其是在网络攻击和虚假信息传播等场景中。
- 论文从理论和实证角度出发,利用形式语言理论和数据驱动分析,研究了LLM输出的可归因性问题。
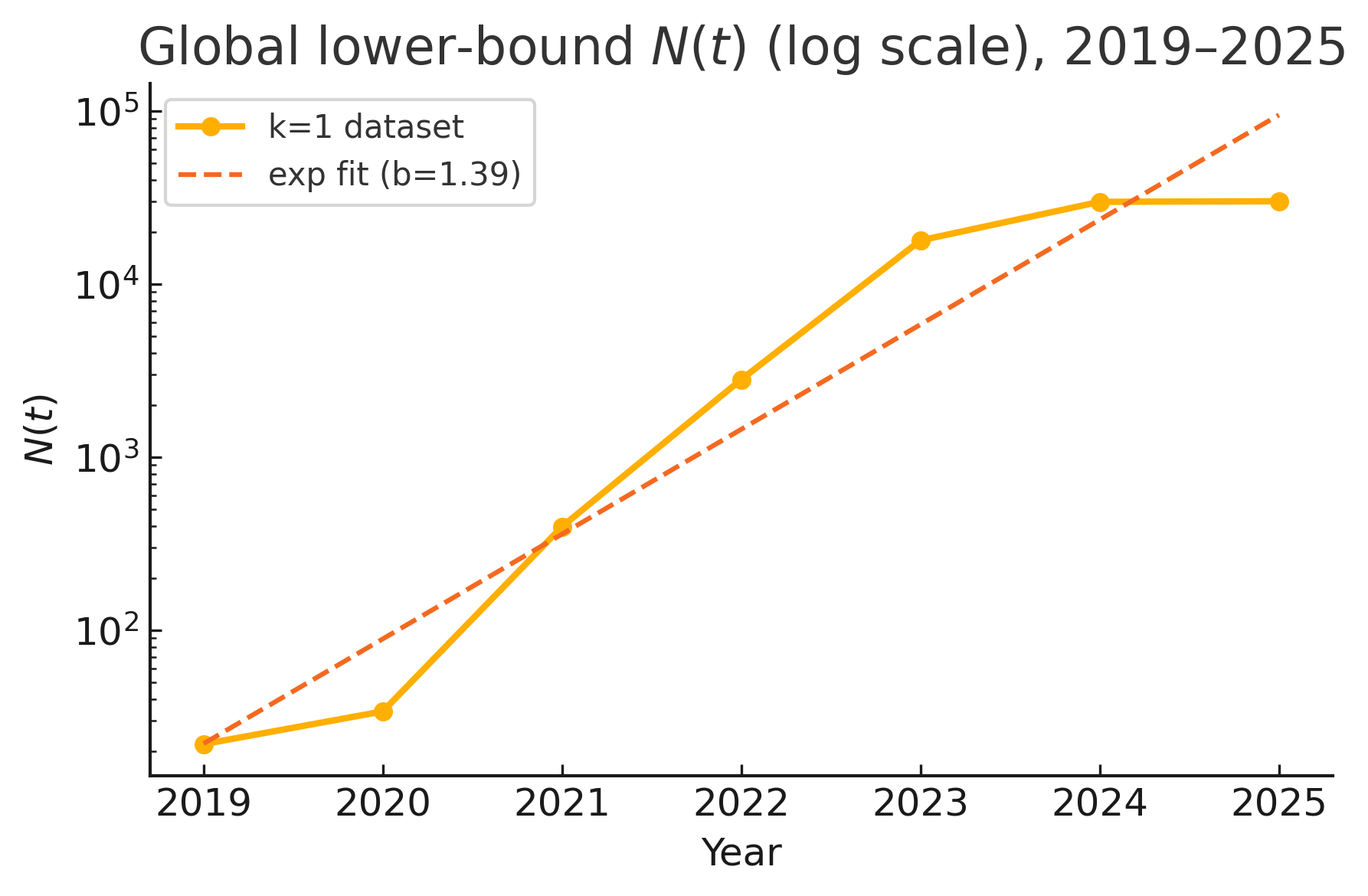
- 研究表明,在模型能力重叠的情况下,仅凭LLM输出难以唯一识别其来源模型,且模型数量的快速增长进一步加剧了归因的难度。
📝 摘要(中文)
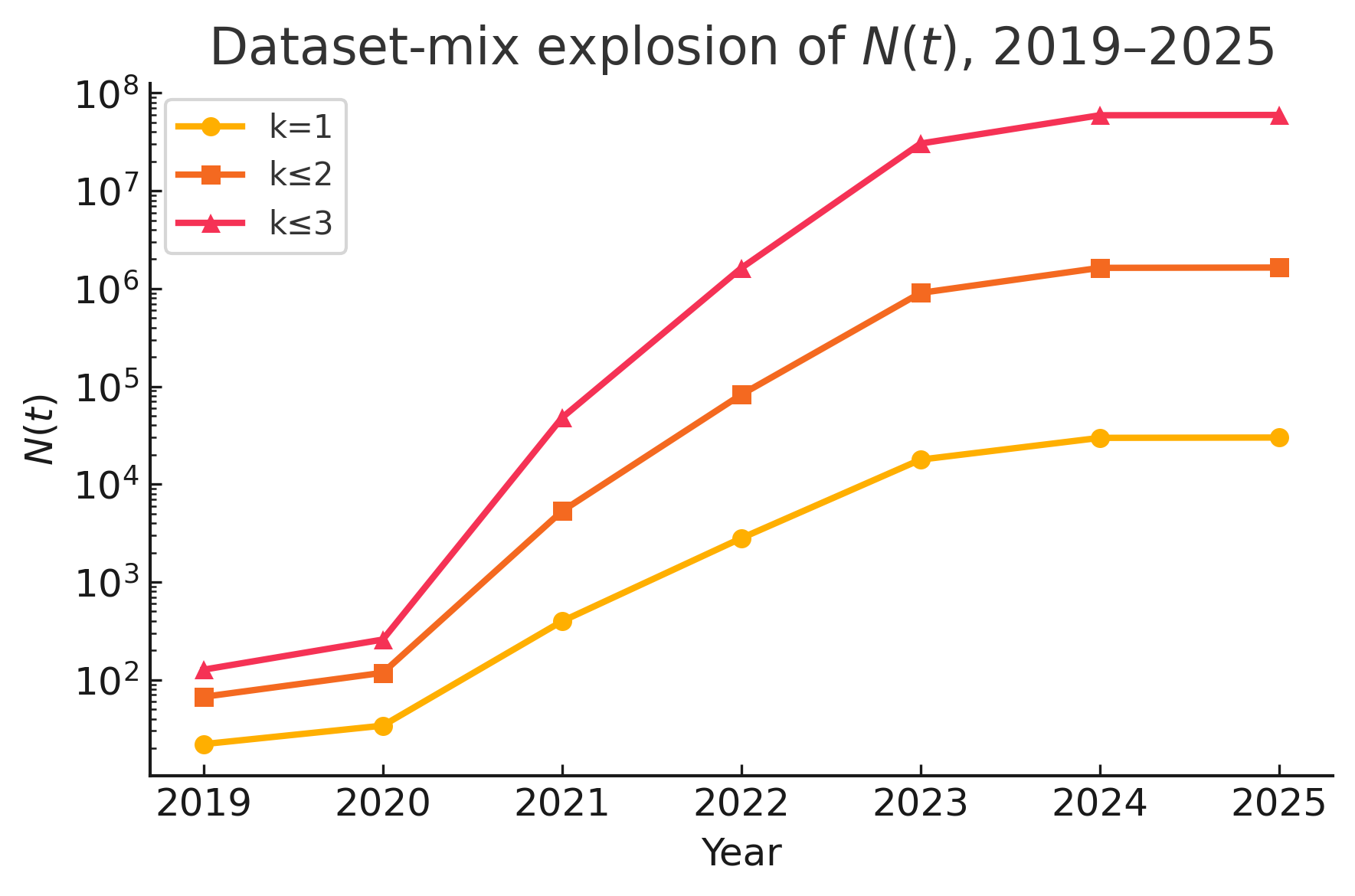
在大语言模型(LLM)对抗环境(如网络攻击和虚假信息传播)中,对其输出进行归因提出了重大挑战,并且这种挑战的重要性可能会日益增加。我们从理论和实证两个角度研究了这个问题,借鉴了形式语言理论(极限识别)和对不断扩展的LLM生态系统的数据驱动分析。通过将LLM可能的输出集合建模为形式语言,我们分析了有限的文本样本是否能唯一地确定其来源模型。结果表明,在模型间能力存在轻微重叠的假设下,某些类型的LLM本质上无法仅从其输出进行识别。我们划分了理论可识别性的四个区域:(1)无限类别的确定性(离散)LLM语言是不可识别的(Gold 1967年的经典结果);(2)无限类别的概率LLM也是不可识别的(确定性案例的扩展);(3)有限类别的确定性LLM是可识别的(与Angluin的tell-tale准则一致);(4)即使是有限类别的概率LLM也可能是不可识别的(我们提供了一个新的反例来证实这一负面结果)。作为对这些理论见解的补充,我们量化了近年来给定输出的合理模型来源(假设空间)数量的爆炸式增长。即使在保守的假设下——每个开源模型最多在一个新数据集上进行微调——不同候选模型的数量大约每0.5年翻一番,而允许多数据集微调组合则导致翻番时间短至0.28年。这种组合增长,以及在所有模型和潜在用户中进行暴力似然归因的巨大计算成本,使得详尽的归因在实践中不可行。
🔬 方法详解
问题定义:论文旨在解决对抗环境下大语言模型(LLM)输出的归因问题。现有方法难以应对LLM数量爆炸式增长以及模型能力重叠的挑战,导致无法准确识别恶意文本的来源模型。这在网络安全和信息安全领域构成了严重威胁。
核心思路:论文的核心思路是将LLM的输出建模为形式语言,并利用形式语言理论中的可识别性概念来分析LLM输出的可归因性。通过理论分析和实证研究,揭示了仅凭LLM输出进行归因的局限性,并量化了模型数量增长对归因难度的影响。
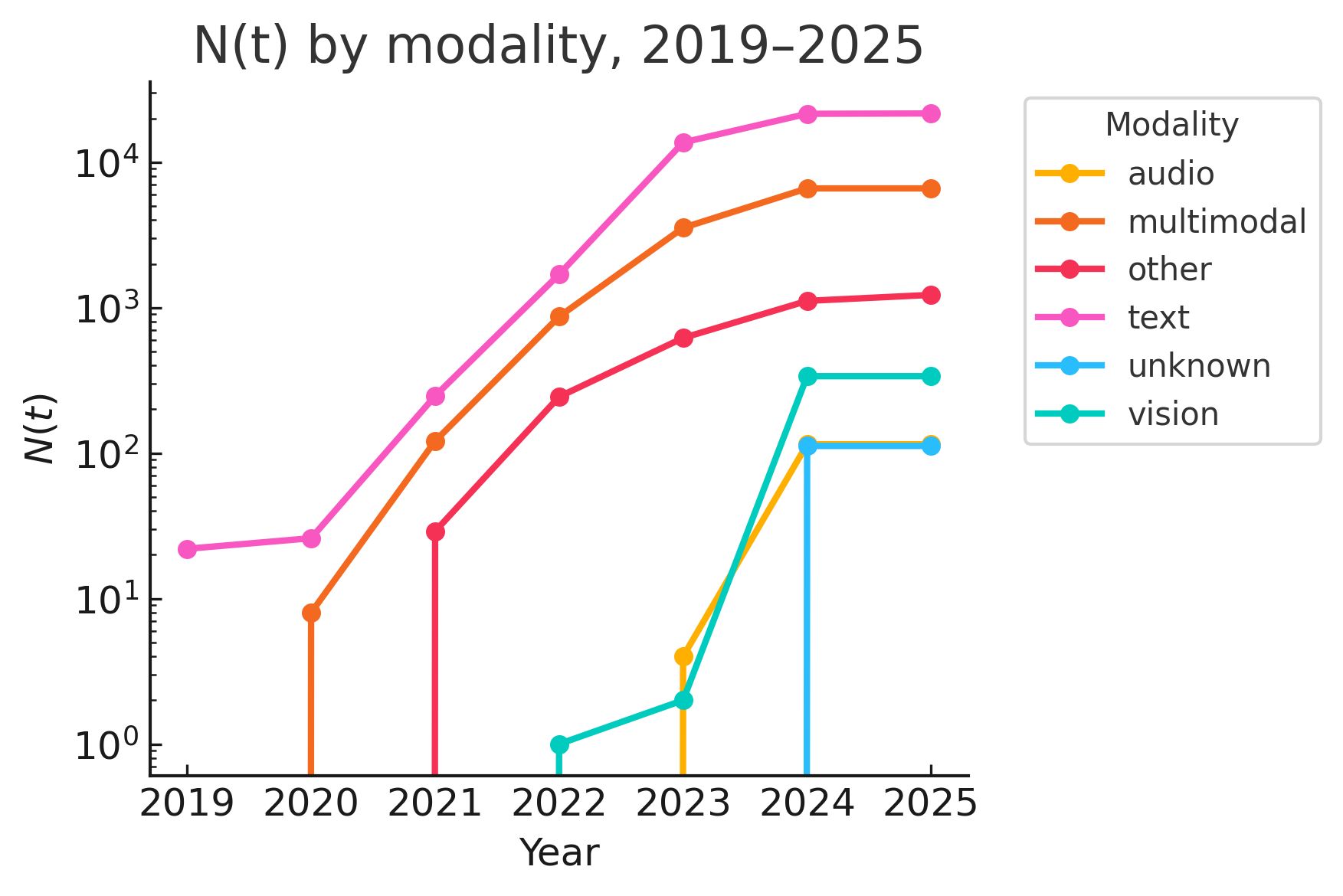
技术框架:论文的技术框架包括两个主要部分:理论分析和实证研究。理论分析部分,首先将LLM的输出建模为形式语言,然后利用形式语言理论中的极限识别概念,分析不同类型的LLM(确定性、概率性、有限、无限)的可识别性。实证研究部分,通过分析开源LLM的微调数据,量化了模型数量的增长速度,并评估了暴力似然归因的计算成本。
关键创新:论文的关键创新在于将形式语言理论应用于LLM输出的归因问题,并从理论上证明了在一定条件下,仅凭LLM输出无法唯一识别其来源模型。此外,论文还量化了模型数量增长对归因难度的影响,为理解LLM对抗攻击的归因问题提供了新的视角。
关键设计:论文在理论分析中,使用了Gold的极限识别理论和Angluin的tell-tale准则来分析LLM的可识别性。在实证研究中,论文分析了开源LLM的微调数据,并使用保守的假设来估计模型数量的增长速度。论文还考虑了单数据集微调和多数据集微调两种情况,并评估了暴力似然归因的计算成本。
🖼️ 关键图片
📊 实验亮点
论文通过理论分析证明,无限类别的确定性和概率性LLM是不可识别的。实证研究表明,即使在保守假设下,候选模型数量大约每0.5年翻一番,多数据集微调甚至缩短至0.28年。这种模型数量的爆炸式增长使得详尽的归因在实践中变得不可行。
🎯 应用场景
该研究成果可应用于网络安全、信息安全和内容溯源等领域。通过理解LLM输出归因的局限性,可以更好地设计防御策略,例如开发更强大的对抗样本检测方法,或改进LLM的训练方式以提高其可追溯性。此外,该研究还可以帮助识别虚假信息传播的源头,从而减少其负面影响。
📄 摘要(原文)
Attributing outputs from Large Language Models (LLMs) in adversarial settings-such as cyberattacks and disinformation campaigns-presents significant challenges that are likely to grow in importance. We approach this attribution problem from both a theoretical and an empirical perspective, drawing on formal language theory (identification in the limit) and data-driven analysis of the expanding LLM ecosystem. By modeling an LLM's set of possible outputs as a formal language, we analyze whether finite samples of text can uniquely pinpoint the originating model. Our results show that, under mild assumptions of overlapping capabilities among models, certain classes of LLMs are fundamentally non-identifiable from their outputs alone. We delineate four regimes of theoretical identifiability: (1) an infinite class of deterministic (discrete) LLM languages is not identifiable (Gold's classical result from 1967); (2) an infinite class of probabilistic LLMs is also not identifiable (by extension of the deterministic case); (3) a finite class of deterministic LLMs is identifiable (consistent with Angluin's tell-tale criterion); and (4) even a finite class of probabilistic LLMs can be non-identifiable (we provide a new counterexample establishing this negative result). Complementing these theoretical insights, we quantify the explosion in the number of plausible model origins (hypothesis space) for a given output in recent years. Even under conservative assumptions-each open-source model fine-tuned on at most one new dataset-the count of distinct candidate models doubles approximately every 0.5 years, and allowing multi-dataset fine-tuning combinations yields doubling times as short as 0.28 years. This combinatorial growth, alongside the extraordinary computational cost of brute-force likelihood attribution across all models and potential users, renders exhaustive attribution infeasible in practice.