Training Data for Large Language Model
作者: Yiming Ju, Huanhuan Ma
分类: cs.AI
发布日期: 2024-11-12
备注: in Chinese language
💡 一句话要点
综述大规模语言模型训练数据,关注数据规模、类型、处理流程与开源数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 训练数据 预训练 微调 数据集构建 数据处理 开源数据集
📋 核心要点
- 现有大规模语言模型依赖海量数据,但数据质量和标注成本成为瓶颈,限制了模型性能的进一步提升。
- 本文综述了大规模语言模型的训练数据,从数据规模、收集方法到处理流程,提供全面的视角。
- 论文整理了可用的开源数据集,为研究者提供了便利,加速了相关领域的研究进展。
📝 摘要(中文)
2022年,随着ChatGPT的发布,大规模语言模型受到了广泛关注。ChatGPT不仅在参数和预训练语料库的规模上超越了以往的模型,而且通过对大量高质量、人工标注的数据进行微调,实现了革命性的性能提升。这一进展使企业和研究机构认识到,构建更智能、更强大的模型依赖于丰富和高质量的数据集。因此,数据集的构建和优化已成为人工智能领域的一个关键焦点。本文总结了当前用于训练大规模语言模型的预训练和微调数据,涵盖了数据规模、收集方法、数据类型和特征、处理工作流程等方面,并概述了可用的开源数据集。
🔬 方法详解
问题定义:大规模语言模型(LLM)的训练依赖于海量数据,但高质量、多样化的数据获取和处理面临挑战。现有方法在数据选择、清洗、标注等方面存在不足,影响了模型的泛化能力和性能表现。如何高效构建高质量的训练数据集是当前LLM研究的关键问题。
核心思路:本文的核心思路是对现有LLM的训练数据进行系统性的梳理和总结,分析不同类型数据的特点和适用场景,并探讨数据处理流程中的关键环节。通过对现有方法的分析,为未来数据集的构建和优化提供指导。
技术框架:本文主要采用综述的形式,对现有文献进行整理和归纳。其框架主要包括:1) 数据规模的分析,探讨不同规模数据对模型性能的影响;2) 数据收集方法的总结,包括网络爬取、人工标注等;3) 数据类型和特征的分析,例如文本、图像、代码等;4) 数据处理流程的梳理,包括数据清洗、去重、标注等;5) 开源数据集的介绍,为研究者提供参考。
关键创新:本文的创新之处在于对LLM训练数据的全面总结和分析,为研究者提供了一个系统的参考框架。它没有提出新的算法或模型,而是侧重于对现有数据的理解和利用,从而为未来的研究方向提供启示。
关键设计:本文的关键设计在于其综述的全面性和系统性。它不仅关注数据的规模,还深入探讨了数据的类型、特征和处理流程。此外,对开源数据集的整理也为研究者提供了便利。具体的参数设置、损失函数、网络结构等技术细节不在本文的讨论范围之内,因为本文主要关注的是数据层面。
🖼️ 关键图片
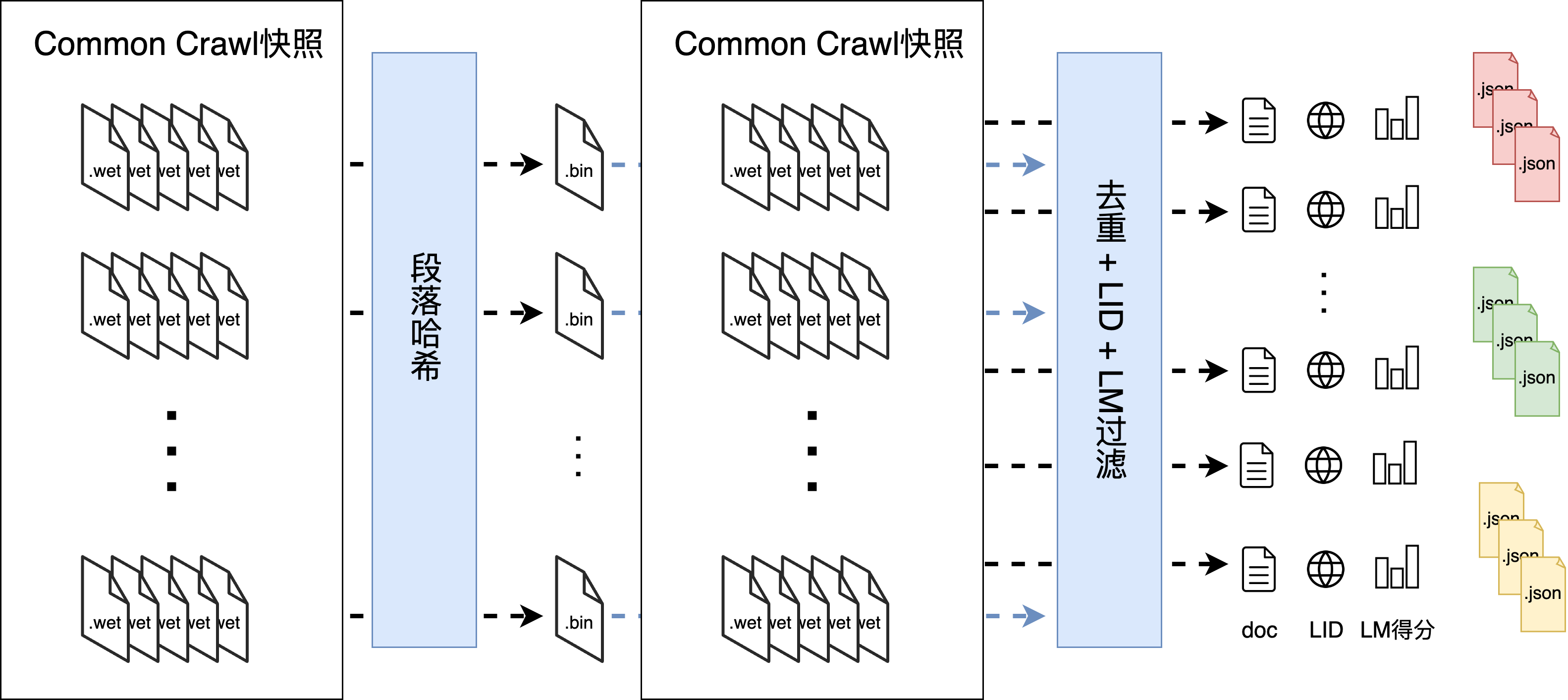
📊 实验亮点
本文重点在于对现有数据的梳理和总结,而非实验结果的展示。其亮点在于对数据规模、收集方法、数据类型和特征、处理工作流程以及开源数据集的全面概述,为后续研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于指导大规模语言模型的训练数据构建,帮助研究人员和企业更有效地收集、处理和利用数据,从而提升模型的性能和泛化能力。高质量的训练数据对于开发各种下游应用,如智能客服、机器翻译、文本生成等至关重要。
📄 摘要(原文)
In 2022, with the release of ChatGPT, large-scale language models gained widespread attention. ChatGPT not only surpassed previous models in terms of parameters and the scale of its pretraining corpus but also achieved revolutionary performance improvements through fine-tuning on a vast amount of high-quality, human-annotated data. This progress has led enterprises and research institutions to recognize that building smarter and more powerful models relies on rich and high-quality datasets. Consequently, the construction and optimization of datasets have become a critical focus in the field of artificial intelligence. This paper summarizes the current state of pretraining and fine-tuning data for training large-scale language models, covering aspects such as data scale, collection methods, data types and characteristics, processing workflows, and provides an overview of available open-source datasets.