LLM App Squatting and Cloning
作者: Yinglin Xie, Xinyi Hou, Yanjie Zhao, Kai Chen, Haoyu Wang
分类: cs.AI, cs.CR
发布日期: 2024-11-12
💡 一句话要点
LLM应用商店中恶意应用泛滥:提出LLMappCrazy工具,大规模分析应用抢注和克隆问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM应用商店 应用抢注 应用克隆 恶意应用检测 文本相似度分析
📋 核心要点
- LLM应用商店面临应用抢注和克隆的威胁,现有检测方法缺乏针对性和大规模分析能力。
- 提出LLMappCrazy工具,结合抢注生成技术、文本相似度计算和语义分析,实现自动化检测。
- 实验表明,LLMappCrazy能有效识别大量抢注和克隆应用,并揭示其中存在的恶意行为。
📝 摘要(中文)
移动应用商店中,应用抢注和克隆等恶意行为长期存在,不法分子利用流行应用的名称和声誉欺骗用户。随着GPT Store和FlowGPT等大型语言模型(LLM)应用商店的快速发展,这些问题也开始浮出水面,威胁着LLM应用生态系统的完整性。本研究首次对LLM应用抢注和克隆进行了大规模分析,使用了我们定制的工具LLMappCrazy。LLMappCrazy涵盖了14种抢注生成技术,并集成了Levenshtein距离和基于BERT的语义分析,通过分析应用功能相似性来检测克隆。使用该工具,我们生成了前1000个应用名称的变体,并在数据集中发现了超过5,000个抢注应用。此外,我们在六个主要平台上观察到3,509个抢注应用和9,575个克隆案例。抽样后,我们发现18.7%的抢注应用和4.9%的克隆应用表现出恶意行为,包括网络钓鱼、恶意软件分发、虚假内容传播和恶意广告注入。
🔬 方法详解
问题定义:论文旨在解决LLM应用商店中日益严重的应用抢注和克隆问题。现有方法在检测此类恶意行为时存在局限性,缺乏大规模、自动化和精准的检测能力。传统的字符串匹配方法难以应对名称变体,而人工审核效率低下且成本高昂。因此,需要一种能够自动生成抢注变体并准确识别克隆应用的方法,以维护LLM应用生态系统的安全。
核心思路:论文的核心思路是构建一个自动化工具LLMappCrazy,该工具能够模拟恶意行为者生成各种抢注应用名称,并利用文本相似度和语义分析技术检测克隆应用。通过大规模分析,揭示LLM应用商店中存在的恶意应用数量和类型,从而为后续的安全防护措施提供数据支持。
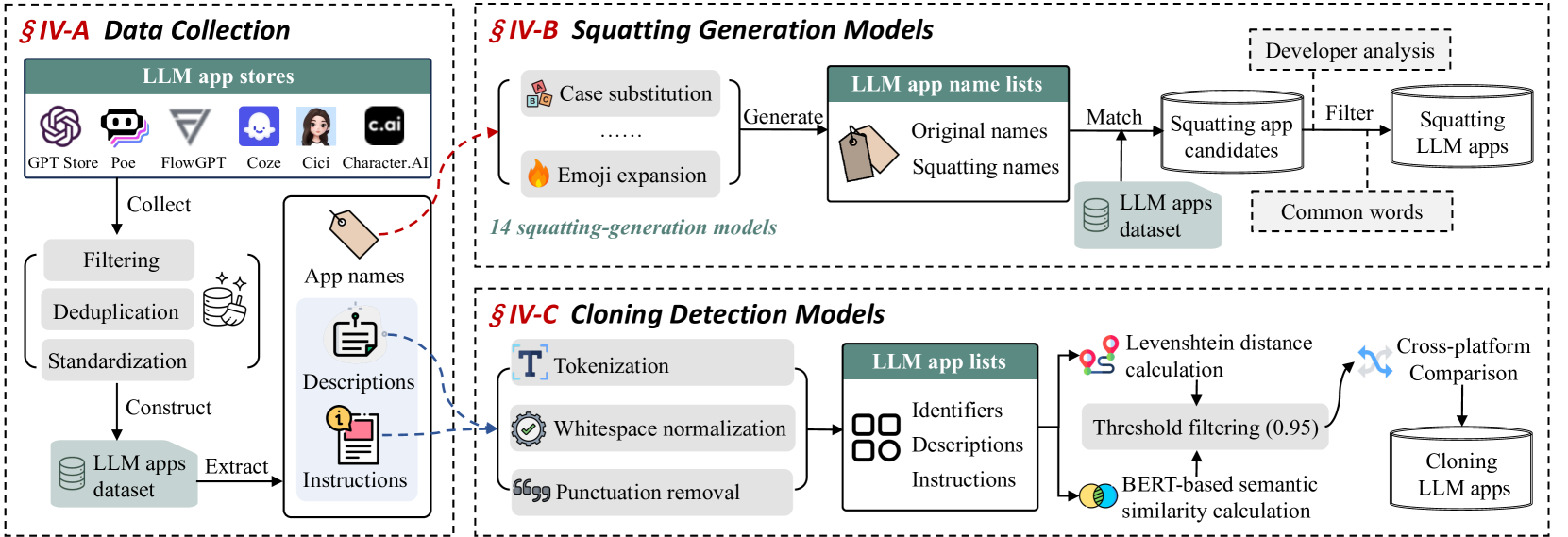
技术框架:LLMappCrazy工具主要包含以下几个模块:1) 抢注生成模块:利用14种不同的抢注生成技术,例如字符替换、插入、删除等,生成目标应用名称的各种变体。2) 克隆检测模块:首先计算应用描述文本之间的Levenshtein距离,初步筛选出相似的应用。然后,使用基于BERT的语义分析模型,进一步判断应用的功能相似性,从而识别克隆应用。3) 恶意行为分析模块:对检测到的抢注和克隆应用进行抽样分析,判断其是否存在恶意行为,例如网络钓鱼、恶意软件分发等。
关键创新:论文的关键创新在于:1) 首次针对LLM应用商店中的应用抢注和克隆问题进行了大规模分析。2) 提出了LLMappCrazy工具,集成了多种抢注生成技术和文本相似度分析方法,实现了自动化检测。3) 揭示了LLM应用商店中存在的恶意应用数量和类型,为后续的安全防护措施提供了数据支持。
关键设计:在抢注生成模块中,论文采用了14种常见的抢注技术,例如字符替换(将“o”替换为“0”)、字符插入(在名称中插入空格或特殊字符)等。在克隆检测模块中,论文使用了预训练的BERT模型,对应用描述文本进行语义编码,然后计算编码向量之间的余弦相似度,作为判断应用功能相似性的依据。此外,论文还设置了Levenshtein距离和余弦相似度的阈值,用于控制检测的精度和召回率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLMappCrazy工具能够有效识别LLM应用商店中的抢注和克隆应用。在六个主要平台上,共检测到3,509个抢注应用和9,575个克隆案例。抽样分析发现,18.7%的抢注应用和4.9%的克隆应用存在恶意行为,证明了LLM应用商店面临着严重的安全威胁。
🎯 应用场景
该研究成果可应用于LLM应用商店的安全防护,帮助平台快速识别和下架恶意应用,维护应用生态系统的健康。同时,该方法也可推广到其他类型的应用商店,提升整体安全性。研究结果有助于开发者了解恶意应用的常见手段,从而提高安全意识,避免被不法分子利用。
📄 摘要(原文)
Impersonation tactics, such as app squatting and app cloning, have posed longstanding challenges in mobile app stores, where malicious actors exploit the names and reputations of popular apps to deceive users. With the rapid growth of Large Language Model (LLM) stores like GPT Store and FlowGPT, these issues have similarly surfaced, threatening the integrity of the LLM app ecosystem. In this study, we present the first large-scale analysis of LLM app squatting and cloning using our custom-built tool, LLMappCrazy. LLMappCrazy covers 14 squatting generation techniques and integrates Levenshtein distance and BERT-based semantic analysis to detect cloning by analyzing app functional similarities. Using this tool, we generated variations of the top 1000 app names and found over 5,000 squatting apps in the dataset. Additionally, we observed 3,509 squatting apps and 9,575 cloning cases across six major platforms. After sampling, we find that 18.7% of the squatting apps and 4.9% of the cloning apps exhibited malicious behavior, including phishing, malware distribution, fake content dissemination, and aggressive ad injection.