LLMs as Method Actors: A Model for Prompt Engineering and Architecture
作者: Colin Doyle
分类: cs.AI, cs.CL
发布日期: 2024-11-08 (更新: 2024-11-11)
💡 一句话要点
提出“方法演员”模型,显著提升LLM在Connections谜题中的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM 提示工程 推理能力 方法演员 Connections谜题
📋 核心要点
- 现有方法在解决复杂推理任务(如Connections谜题)时,LLM的性能仍有提升空间。
- 论文提出“方法演员”模型,将LLM视为演员,提示词为剧本,通过精心设计的提示架构提升LLM的推理能力。
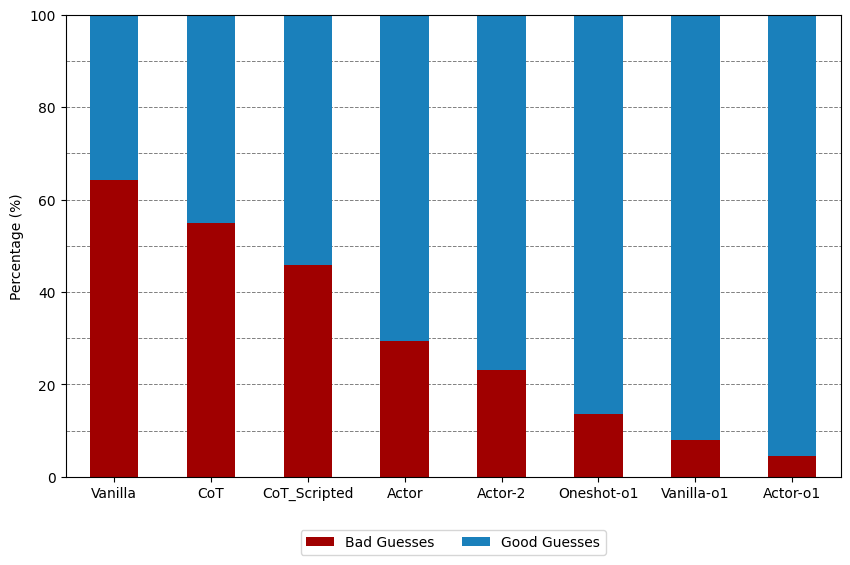
- 实验表明,“方法演员”模型在GPT-4o和o1-preview上均能显著提升Connections谜题的解决率,最高提升至86%和100%。
📝 摘要(中文)
本文提出了一种名为“方法演员”的思维模型,用于指导LLM的提示工程和提示架构。在该模型下,LLM被视为演员,提示被视为剧本和提示,LLM的响应被视为表演。我们将此模型应用于提高LLM在Connections游戏中的表现,这是一个纽约时报的文字谜题游戏,之前的研究认为它是评估LLM推理能力的具有挑战性的基准。我们使用GPT-4o的实验表明,“方法演员”方法可以显著提高LLM的性能,优于原始方法和“思维链”方法。原始方法解决了我们数据集中27%的Connections谜题,“思维链”方法解决了41%的谜题,而我们最强的“方法演员”方法解决了86%的谜题。我们还测试了OpenAI专门为复杂推理任务设计的新模型o1-preview。当要求一次性解决一个谜题时,o1-preview解决了我们数据集中79%的Connections谜题,当允许通过多次API调用逐步构建谜题解决方案时,o1-preview解决了100%的谜题。结合“方法演员”提示架构将o1-preview完美解决的谜题百分比从76%提高到87%。
🔬 方法详解
问题定义:论文旨在提升LLM在复杂推理任务中的表现,具体选择纽约时报的文字谜题游戏Connections作为测试基准。现有方法,如原始提示和思维链提示,在解决这类问题时仍存在不足,无法充分发挥LLM的推理潜力。
核心思路:核心在于将LLM视为一个“方法演员”,通过精心设计的提示(剧本)来引导LLM的行为。这种思路强调了提示工程的重要性,并将其提升到架构设计的层面,从而更好地控制LLM的推理过程。
技术框架:整体框架包含以下几个关键部分:1) 定义“方法演员”的角色和目标;2) 设计提示词,作为“剧本”指导LLM的推理步骤;3) 通过迭代优化提示词,提升LLM的性能;4) 评估不同提示架构在Connections谜题上的表现。对于o1-preview模型,还探索了单次API调用和多次API调用逐步构建解决方案两种方式。
关键创新:最重要的创新在于“方法演员”这一概念模型,它将LLM的提示工程从简单的指令调整提升到架构设计的层面。这种模型强调了提示词的结构化和角色扮演,从而更好地控制LLM的推理过程,使其更接近人类解决问题的模式。与传统的思维链方法相比,“方法演员”模型更加强调对LLM行为的引导和控制。
关键设计:论文中没有详细描述具体的参数设置或损失函数,而是侧重于提示词的设计。关键设计在于如何将Connections谜题的解决过程分解为一系列可执行的步骤,并将其转化为LLM可以理解和执行的“剧本”。例如,可以设计提示词引导LLM先识别可能的类别,然后逐步验证每个类别中的词语是否符合要求。
🖼️ 关键图片
📊 实验亮点
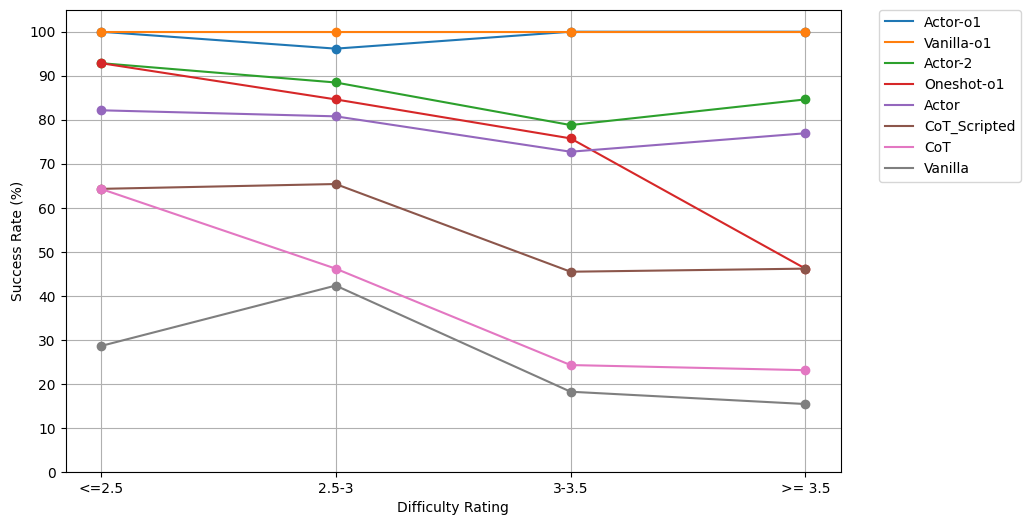
实验结果表明,“方法演员”模型在GPT-4o上的表现显著优于原始方法和思维链方法,Connections谜题的解决率从27%和41%分别提升至86%。对于OpenAI的o1-preview模型,结合“方法演员”提示架构将完美解决的谜题百分比从76%提高到87%,并且在多次API调用下,o1-preview解决了100%的谜题。
🎯 应用场景
该研究成果可应用于各种需要复杂推理和问题解决的领域,例如智能客服、自动化报告生成、代码生成和调试等。通过将LLM视为“方法演员”,可以更好地控制其行为,使其在特定任务中表现出更高的智能水平。未来,该模型可以扩展到更广泛的任务类型和LLM模型。
📄 摘要(原文)
We introduce "Method Actors" as a mental model for guiding LLM prompt engineering and prompt architecture. Under this mental model, LLMs should be thought of as actors; prompts as scripts and cues; and LLM responses as performances. We apply this mental model to the task of improving LLM performance at playing Connections, a New York Times word puzzle game that prior research identified as a challenging benchmark for evaluating LLM reasoning. Our experiments with GPT-4o show that a "Method Actors" approach can significantly improve LLM performance over both a vanilla and "Chain of Thoughts" approach. A vanilla approach solves 27% of Connections puzzles in our dataset and a "Chain of Thoughts" approach solves 41% of puzzles, whereas our strongest "Method Actor" approach solves 86% of puzzles. We also test OpenAI's newest model designed specifically for complex reasoning tasks, o1-preview. When asked to solve a puzzle all at once, o1-preview solves 79% of Connections puzzles in our dataset, and when allowed to build puzzle solutions one guess at a time over multiple API calls, o1-preview solves 100% of the puzzles. Incorporating a "Method Actor" prompt architecture increases the percentage of puzzles that o1-preview solves perfectly from 76% to 87%.