Intellectual Property Protection for Deep Learning Model and Dataset Intelligence
作者: Yongqi Jiang, Yansong Gao, Chunyi Zhou, Hongsheng Hu, Anmin Fu, Willy Susilo
分类: cs.CR, cs.AI, cs.LG
发布日期: 2024-11-07
💡 一句话要点
综述深度学习模型与数据集的知识产权保护方法,涵盖主动防御与被动验证。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识产权保护 深度学习模型 数据集 主动防御 被动验证
📋 核心要点
- 深度学习模型训练成本高昂,知识产权保护日益重要,但现有综述主要关注模型层面,忽略了数据集的价值。
- 该综述从主动预防和被动验证两个角度,全面分析了数据集和模型智能的知识产权保护方法。
- 论文还探讨了分布式训练设置下知识产权保护的独特挑战,并展望了未来研究方向。
📝 摘要(中文)
随着深度学习(DL)应用的日益广泛,特别是ChatGPT和LLaMA等大型语言模型(LLMs)的卓越成就,这些模型的商业价值急剧上升。然而,获得训练良好的模型成本高昂且资源密集,需要大量高质量的数据集、在专用架构设计上的大量投资、昂贵的计算资源以及开发技术专长的努力。因此,保护训练有素的模型的知识产权(IP)正受到越来越多的关注。与现有主要侧重于模型IPP的调查不同,本调查不仅包括对模型级别智能的保护,还包括对有价值的数据集智能的保护。首先,根据有效IPP设计的要求,本文系统地总结了通用和方案特定的性能评估指标。其次,从主动IP侵权预防和被动IP所有权验证的角度,全面调查和分析了现有数据集和模型智能的IPP方法。此外,从训练设置的角度来看,与集中式设置相比,它深入研究了分布式设置对IPP构成的独特挑战。此外,本文还研究了深度IPP技术面临的各种攻击。最后,我们概述了有希望的未来方向的前景,这些前景可以作为创新研究的指南。
🔬 方法详解
问题定义:论文旨在解决深度学习模型和数据集的知识产权保护问题。现有方法主要集中于模型层面的保护,忽略了数据集的价值。此外,现有方法在分布式训练环境下的适用性也存在挑战。
核心思路:论文的核心思路是从主动预防和被动验证两个角度,全面分析深度学习模型和数据集的知识产权保护方法。主动预防旨在防止未经授权的模型复制和分发,被动验证则用于在发生侵权时证明模型的所有权。
技术框架:论文首先总结了知识产权保护的性能评估指标,包括通用指标和方案特定指标。然后,从主动预防和被动验证两个角度,分别对数据集和模型的知识产权保护方法进行了综述。对于每种方法,论文都分析了其优缺点和适用场景。此外,论文还讨论了分布式训练环境下的知识产权保护挑战,并提出了相应的解决方案。最后,论文总结了现有方法的局限性,并展望了未来研究方向。
关键创新:论文的主要创新在于其全面性,不仅涵盖了模型层面的知识产权保护,还包括了数据集层面的保护。此外,论文还考虑了分布式训练环境下的知识产权保护问题,并提出了相应的解决方案。
关键设计:论文没有提出新的算法或模型,而是一篇综述性文章,因此没有具体的参数设置、损失函数或网络结构等技术细节。论文的关键在于对现有方法的分类和分析,以及对未来研究方向的展望。
🖼️ 关键图片
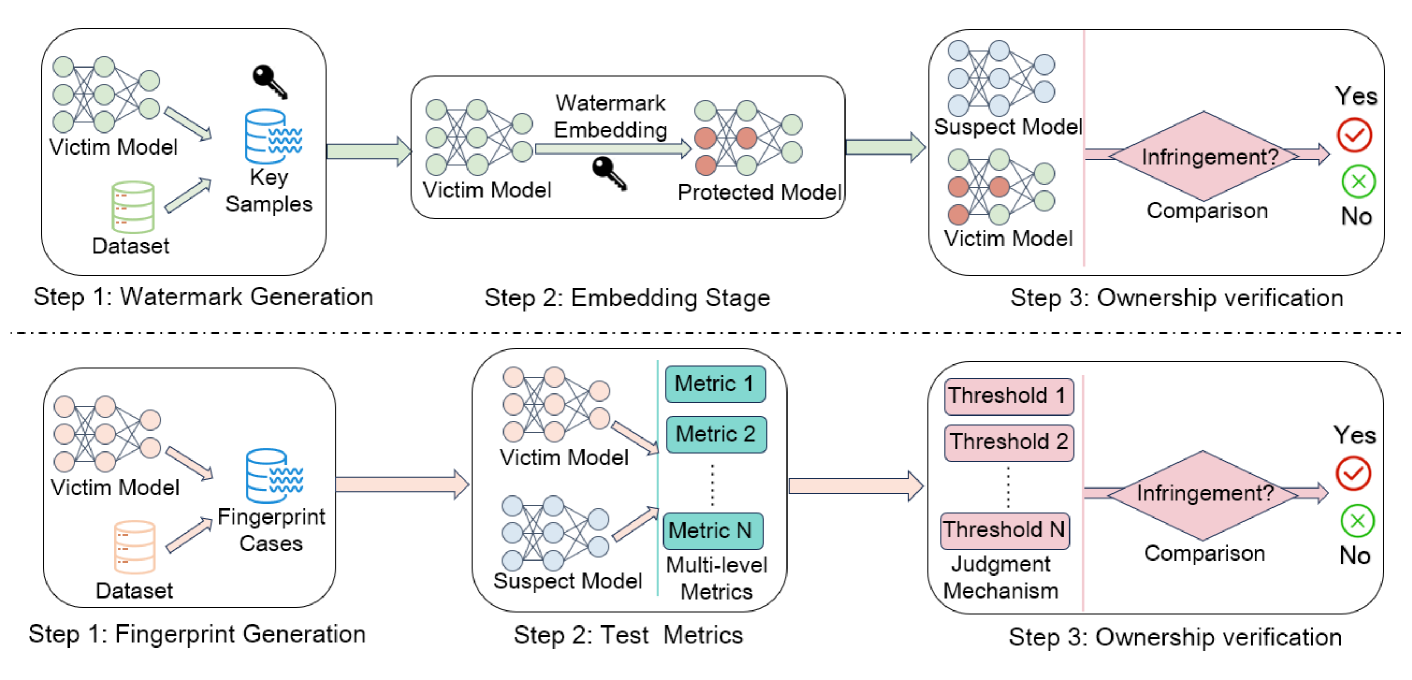


📊 实验亮点
该论文系统地总结了深度学习模型和数据集知识产权保护的现有方法,并从主动防御和被动验证两个角度进行了分类和分析。此外,论文还讨论了分布式训练环境下的知识产权保护挑战,并展望了未来的研究方向,为相关研究人员提供了有价值的参考。
🎯 应用场景
该研究成果可应用于深度学习模型的商业化部署和知识产权保护。通过采用合适的知识产权保护方法,可以防止模型被非法复制和滥用,从而保护模型所有者的利益。此外,该研究还可以促进深度学习技术的健康发展,鼓励创新和投资。
📄 摘要(原文)
With the growing applications of Deep Learning (DL), especially recent spectacular achievements of Large Language Models (LLMs) such as ChatGPT and LLaMA, the commercial significance of these remarkable models has soared. However, acquiring well-trained models is costly and resource-intensive. It requires a considerable high-quality dataset, substantial investment in dedicated architecture design, expensive computational resources, and efforts to develop technical expertise. Consequently, safeguarding the Intellectual Property (IP) of well-trained models is attracting increasing attention. In contrast to existing surveys overwhelmingly focusing on model IPP mainly, this survey not only encompasses the protection on model level intelligence but also valuable dataset intelligence. Firstly, according to the requirements for effective IPP design, this work systematically summarizes the general and scheme-specific performance evaluation metrics. Secondly, from proactive IP infringement prevention and reactive IP ownership verification perspectives, it comprehensively investigates and analyzes the existing IPP methods for both dataset and model intelligence. Additionally, from the standpoint of training settings, it delves into the unique challenges that distributed settings pose to IPP compared to centralized settings. Furthermore, this work examines various attacks faced by deep IPP techniques. Finally, we outline prospects for promising future directions that may act as a guide for innovative research.