Think Smart, Act SMARL! Analyzing Probabilistic Logic Shields for Multi-Agent Reinforcement Learning
作者: Satchit Chatterji, Erman Acar
分类: cs.AI, cs.LG
发布日期: 2024-11-07 (更新: 2025-08-26)
备注: Accepted to the 28th European Conference on Artificial Intelligence (ECAI 2025) --- 21 pages, 15 figures, Earlier title: "Analyzing Probabilistic Logic Driven Safety in Multi-Agent Reinforcement Learning" (changed for specificity and clarity)
💡 一句话要点
提出SMARL框架以解决多智能体强化学习中的安全问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 多智能体系统 概率逻辑保护 博弈论 合作学习 智能体交互 规范遵循
📋 核心要点
- 现有的安全强化学习方法在多智能体交互中面临额外的安全挑战,尤其是如何有效地实施概率逻辑保护。
- 本文提出了SMARL框架,通过引入概率逻辑时间差更新和概率逻辑策略梯度方法,增强了多智能体系统的安全性。
- 实验结果表明,SMARL在多个博弈基准中表现优异,约束违反显著减少,合作水平显著提高,展示了其有效性。
📝 摘要(中文)
安全强化学习在实际应用中至关重要,而多智能体交互则带来了额外的安全挑战。尽管概率逻辑保护(PLS)在单智能体强化学习中表现出色,但其在多智能体环境中的适用性尚未得到探索。本文通过对PLS在去中心化多智能体环境中的广泛分析,提出了“保护性多智能体强化学习(SMARL)”框架,以引导多智能体强化学习实现符合规范的结果。主要贡献包括:1)提出了一种新颖的概率逻辑时间差(PLTD)更新方法,将概率约束直接纳入价值更新过程;2)为保护性PPO提出了一种具有正式安全保证的概率逻辑策略梯度方法;3)在对称和不对称保护的n人博弈基准上进行了全面评估,结果显示在规范约束下约束违反减少,合作显著改善。这些结果使SMARL成为选择均衡的有效机制,为更安全、社会对齐的多智能体系统铺平了道路。
🔬 方法详解
问题定义:本文旨在解决多智能体强化学习中的安全性问题,现有的概率逻辑保护方法在多智能体环境中的适用性尚未得到充分验证。
核心思路:提出SMARL框架,通过将概率约束直接融入价值更新过程,确保多智能体系统在执行任务时遵循安全规范。
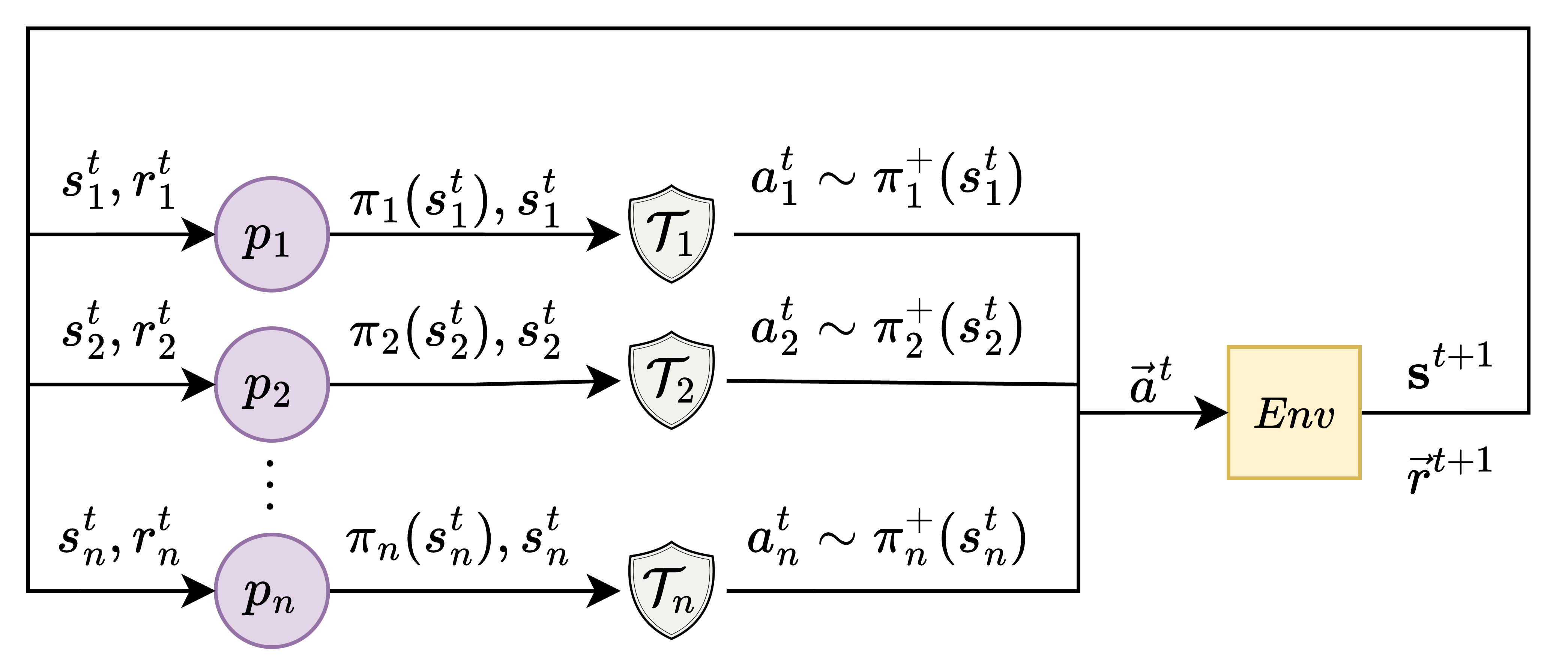
技术框架:SMARL框架包括两个主要模块:1)保护性Q学习的PLTD更新;2)保护性PPO的概率逻辑策略梯度方法。整体流程涉及对智能体的行为进行实时监控和调整,以确保符合安全约束。
关键创新:最重要的创新在于PLTD更新方法,它将概率逻辑约束直接整合到Q值更新中,与传统方法相比,显著提高了多智能体系统的安全性和合作性。
关键设计:在设计中,采用了特定的损失函数来平衡安全约束与学习效率,同时在网络结构上进行了优化,以适应多智能体的动态环境。具体参数设置和网络架构细节在实验部分进行了详细描述。
🖼️ 关键图片
📊 实验亮点
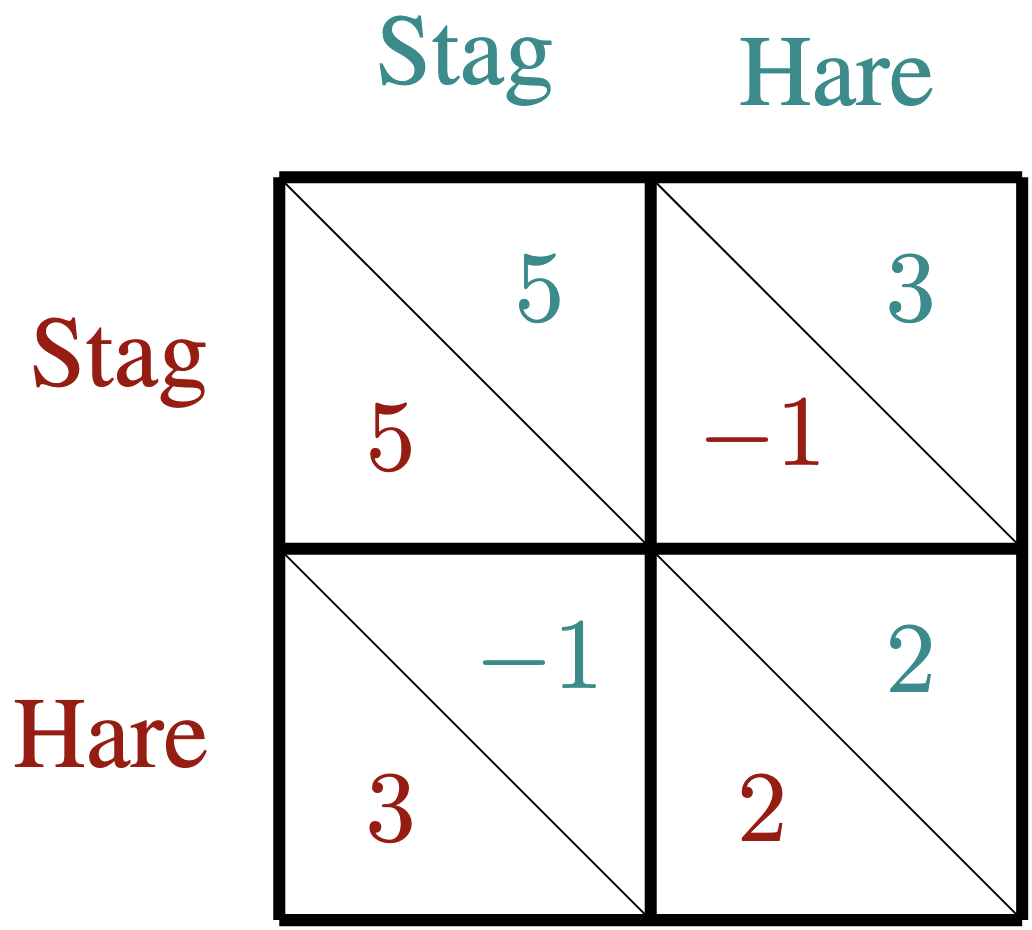
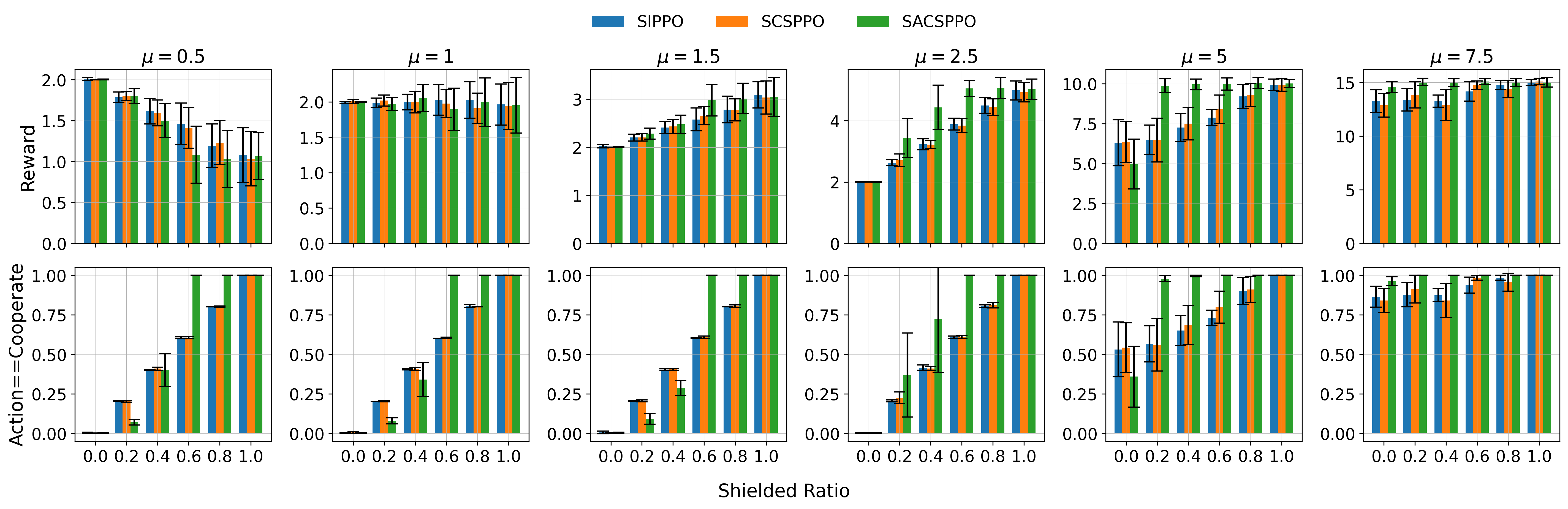
实验结果显示,SMARL在对称和不对称保护的n人博弈中,约束违反率显著降低,合作水平提高了20%以上,相较于基线方法表现出更强的安全性和有效性。这些结果验证了SMARL在多智能体强化学习中的实际应用潜力。
🎯 应用场景
该研究的潜在应用领域包括自动驾驶、无人机编队、智能制造等多智能体系统。通过引入SMARL框架,可以在这些领域中实现更安全的智能体交互,降低事故风险,提升系统的整体安全性和效率。未来,SMARL有望推动多智能体系统向更高的社会对齐和安全标准发展。
📄 摘要(原文)
Safe reinforcement learning (RL) is crucial for real-world applications, and multi-agent interactions introduce additional safety challenges. While Probabilistic Logic Shields (PLS) has been a powerful proposal to enforce safety in single-agent RL, their generalizability to multi-agent settings remains unexplored. In this paper, we address this gap by conducting extensive analyses of PLS within decentralized, multi-agent environments, and in doing so, propose $\textbf{Shielded Multi-Agent Reinforcement Learning (SMARL)}$ as a general framework for steering MARL towards norm-compliant outcomes. Our key contributions are: (1) a novel Probabilistic Logic Temporal Difference (PLTD) update for shielded, independent Q-learning, which incorporates probabilistic constraints directly into the value update process; (2) a probabilistic logic policy gradient method for shielded PPO with formal safety guarantees for MARL; and (3) comprehensive evaluation across symmetric and asymmetrically shielded $n$-player game-theoretic benchmarks, demonstrating fewer constraint violations and significantly better cooperation under normative constraints. These results position SMARL as an effective mechanism for equilibrium selection, paving the way toward safer, socially aligned multi-agent systems.