Eguard: Defending LLM Embeddings Against Inversion Attacks via Text Mutual Information Optimization
作者: Tiantian Liu, Hongwei Yao, Feng Lin, Tong Wu, Zhan Qin, Kui Ren
分类: cs.CR, cs.AI, cs.CL
发布日期: 2024-11-06 (更新: 2025-11-19)
💡 一句话要点
Eguard:通过文本互信息优化防御LLM嵌入的逆向攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM嵌入 逆向攻击防御 文本互信息优化 Transformer网络 隐私保护 信息安全 自然语言处理
📋 核心要点
- 嵌入向量数据库易受逆向攻击,攻击者可从中提取敏感信息,现有防御机制难以兼顾安全性和下游任务性能。
- Eguard通过Transformer投影网络和文本互信息优化,在保护嵌入的同时,维持LLM的下游任务性能。
- 实验结果表明,Eguard能够保护超过95%的token免受逆向攻击,同时保持下游任务的高性能。
📝 摘要(中文)
嵌入已成为大型语言模型(LLM)功能的基础,因为它们能够将文本数据转换为丰富的、密集的数值表示,从而捕获语义和句法属性。这些嵌入向量数据库充当LLM的长期记忆,能够有效处理各种自然语言处理任务。然而,LLM中嵌入向量数据库的普及也伴随着对隐私泄露的重大担忧。嵌入向量数据库特别容易受到嵌入逆向攻击,攻击者可以利用嵌入来逆向工程并从原始文本数据中提取敏感信息。现有的防御机制存在局限性,通常难以平衡安全性和下游任务的性能。为了应对这些挑战,我们引入了Eguard,一种旨在减轻嵌入逆向攻击的新型防御机制。Eguard采用基于Transformer的投影网络和文本互信息优化来保护嵌入,同时保持LLM的效用。我们的方法显著降低了隐私风险,保护超过95%的token免受逆向攻击,同时在与原始嵌入一致的下游任务中保持高性能。
🔬 方法详解
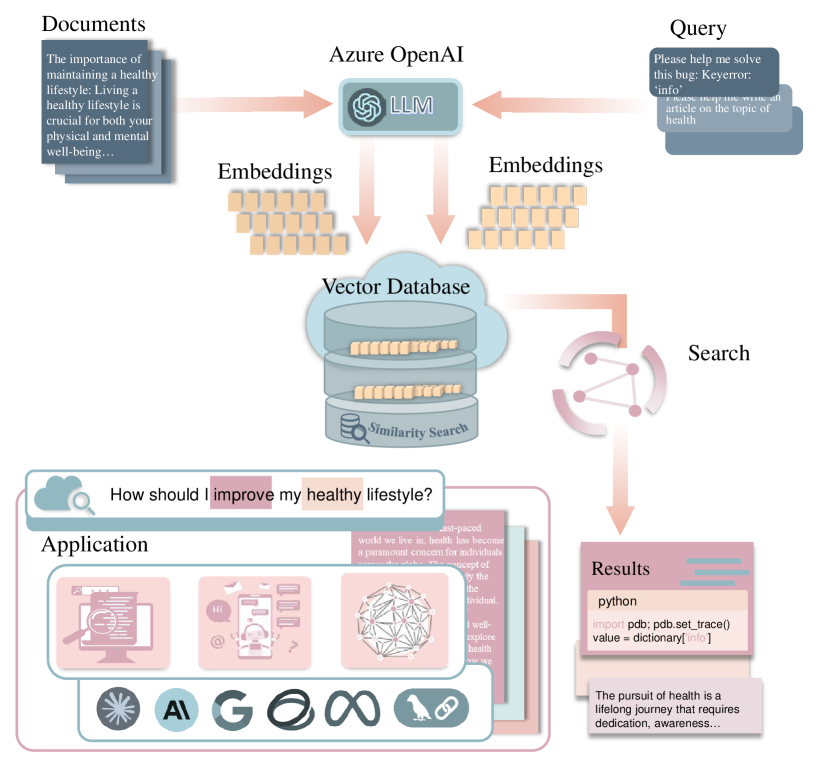
问题定义:论文旨在解决大型语言模型(LLM)中嵌入向量数据库面临的隐私泄露问题,特别是嵌入逆向攻击。现有的防御方法通常无法在保护隐私的同时,维持LLM在下游任务中的性能,导致实用性降低。
核心思路:Eguard的核心思路是通过引入一个投影网络,将原始嵌入映射到一个新的嵌入空间,在这个空间中,逆向攻击的难度大大增加,同时通过文本互信息优化,确保新的嵌入能够尽可能保留原始文本的语义信息,从而保证下游任务的性能。
技术框架:Eguard主要包含两个核心模块:1) 基于Transformer的投影网络:该网络负责将原始嵌入映射到新的嵌入空间。2) 文本互信息优化模块:该模块通过优化文本互信息损失函数,确保新的嵌入能够保留原始文本的语义信息。整体流程是,首先使用投影网络对原始嵌入进行转换,然后使用文本互信息优化模块对投影网络进行训练,最终得到具有抗逆向攻击能力且保持语义信息的嵌入。
关键创新:Eguard的关键创新在于其同时考虑了隐私保护和下游任务性能。传统的防御方法往往只关注隐私保护,而忽略了对下游任务性能的影响。Eguard通过文本互信息优化,能够在保护隐私的同时,尽可能地保留原始文本的语义信息,从而保证下游任务的性能。此外,使用Transformer作为投影网络,能够更好地捕捉文本的上下文信息,提高嵌入的质量。
关键设计:Eguard的关键设计包括:1) 投影网络采用Transformer结构,以更好地捕捉文本的上下文信息。2) 文本互信息损失函数的设计,旨在最大化原始文本和新嵌入之间的互信息,从而保证语义信息的保留。3) 训练过程中,需要平衡隐私保护和下游任务性能之间的关系,通过调整损失函数的权重来实现。
🖼️ 关键图片


📊 实验亮点
Eguard在实验中表现出色,能够保护超过95%的token免受逆向攻击,同时在下游任务中保持与原始嵌入一致的高性能。与现有的防御方法相比,Eguard在隐私保护和性能之间取得了更好的平衡,证明了其有效性和实用性。实验结果表明,Eguard能够显著降低LLM嵌入向量数据库的隐私风险。
🎯 应用场景
Eguard可应用于各种使用LLM嵌入向量数据库的场景,例如问答系统、信息检索、文本分类等。通过部署Eguard,可以有效防止攻击者从嵌入中逆向提取敏感信息,从而保护用户隐私和数据安全。该研究对于推动LLM在安全敏感领域的应用具有重要意义,例如医疗、金融等。
📄 摘要(原文)
Embeddings have become a cornerstone in the functionality of large language models (LLMs) due to their ability to transform text data into rich, dense numerical representations that capture semantic and syntactic properties. These embedding vector databases serve as the long-term memory of LLMs, enabling efficient handling of a wide range of natural language processing tasks. However, the surge in popularity of embedding vector databases in LLMs has been accompanied by significant concerns about privacy leakage. Embedding vector databases are particularly vulnerable to embedding inversion attacks, where adversaries can exploit the embeddings to reverse-engineer and extract sensitive information from the original text data. Existing defense mechanisms have shown limitations, often struggling to balance security with the performance of downstream tasks. To address these challenges, we introduce Eguard, a novel defense mechanism designed to mitigate embedding inversion attacks. Eguard employs a transformer-based projection network and text mutual information optimization to safeguard embeddings while preserving the utility of LLMs. Our approach significantly reduces privacy risks, protecting over 95% of tokens from inversion while maintaining high performance across downstream tasks consistent with original embeddings.