Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding
作者: Haolin Chen, Yihao Feng, Zuxin Liu, Weiran Yao, Akshara Prabhakar, Shelby Heinecke, Ricky Ho, Phil Mui, Silvio Savarese, Caiming Xiong, Huan Wang
分类: cs.AI, cs.CL, cs.LG, stat.ML
发布日期: 2024-11-06 (更新: 2024-11-21)
🔗 代码/项目: GITHUB
💡 一句话要点
提出LaTRO框架以提升大语言模型的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 自我奖励 变分方法 潜在分布 优化框架 复杂任务
📋 核心要点
- 现有方法在训练期间优化大语言模型的推理能力面临挑战,尤其是在复杂推理任务中表现不佳。
- LaTRO框架通过将推理视为潜在分布的采样,利用变分方法进行优化,从而提升模型的推理能力和质量评估能力。
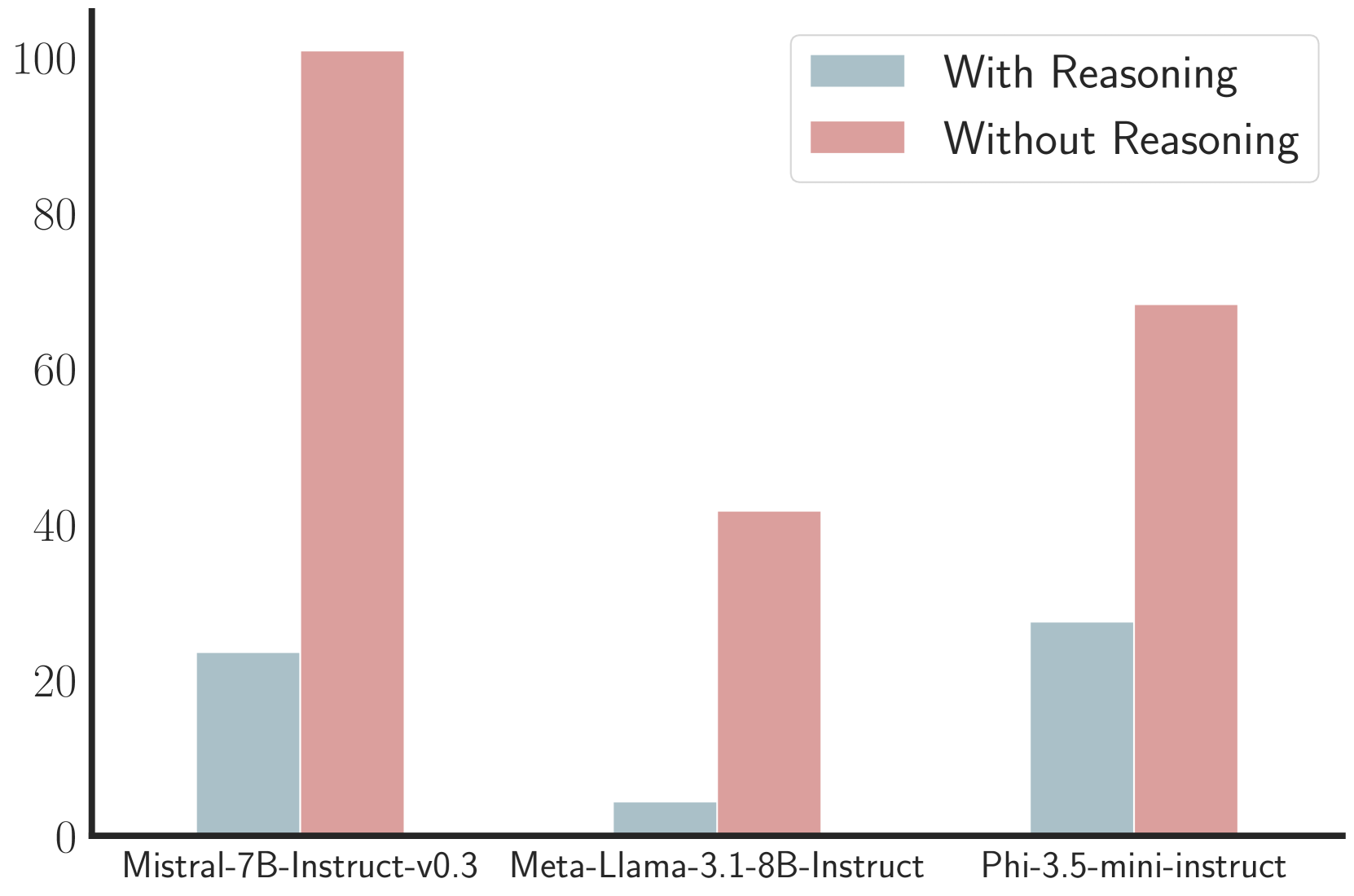
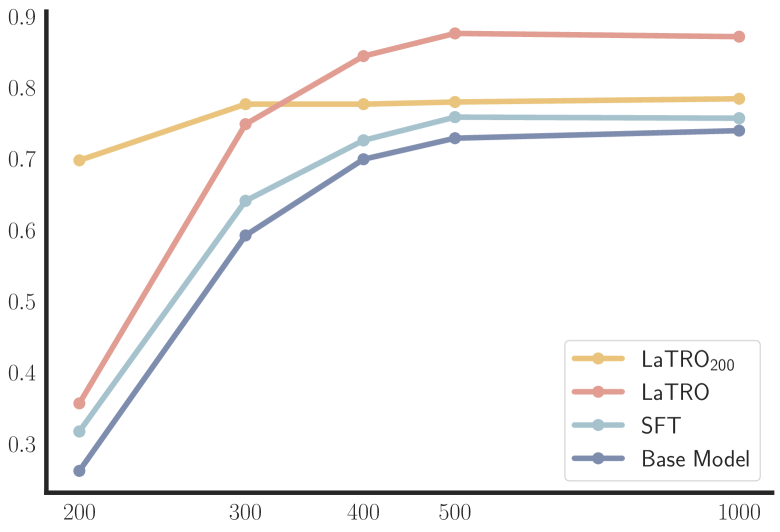
- 在GSM8K数据集上,LaTRO在零-shot准确率上平均提高了12.5%,在监督微调上提高了9.6%,显示出显著的性能提升。
📝 摘要(中文)
大型语言模型(LLMs)展现了令人印象深刻的能力,但在需要多步推理的复杂任务中仍然存在困难。虽然基于提示的方法如链式思维(CoT)可以在推理时改善LLM的推理能力,但在训练期间优化推理能力仍然具有挑战性。本文提出了LaTent Reasoning Optimization(LaTRO),一个将推理视为从潜在分布中采样并通过变分方法进行优化的框架。LaTRO使LLMs能够同时提高推理过程和评估推理质量的能力,而无需外部反馈或奖励模型。通过在GSM8K和ARC-Challenge数据集上的实验验证了LaTRO的有效性。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在复杂推理任务中表现不佳的问题,现有方法如链式思维在推理能力的训练优化上存在局限性。
核心思路:LaTRO框架通过将推理过程视为从潜在分布中进行采样,利用变分方法进行优化,旨在提升模型的推理能力和自我评估能力。
技术框架:LaTRO的整体架构包括潜在分布的建模、变分优化过程以及自我奖励机制,主要模块包括推理过程优化和质量评估能力提升。
关键创新:LaTRO的主要创新在于无需外部反馈或奖励模型,通过自我奖励机制实现推理能力的自我提升,这与传统方法有本质区别。
关键设计:在技术细节上,LaTRO采用了特定的损失函数来优化潜在分布,并设计了适合不同模型架构的参数设置,以确保优化过程的有效性。
🖼️ 关键图片
📊 实验亮点
在实验中,LaTRO在GSM8K数据集上实现了平均12.5%的零-shot准确率提升,相较于基线模型和监督微调均表现出显著的性能改进,验证了其有效性和潜力。
🎯 应用场景
该研究的潜在应用领域包括教育、金融分析和医疗决策等需要复杂推理的场景。通过提升大语言模型的推理能力,LaTRO可以帮助实现更智能的自动化系统,提升决策质量和效率,具有重要的实际价值和未来影响。
📄 摘要(原文)
Large language models (LLMs) have shown impressive capabilities, but still struggle with complex reasoning tasks requiring multiple steps. While prompt-based methods like Chain-of-Thought (CoT) can improve LLM reasoning at inference time, optimizing reasoning capabilities during training remains challenging. We introduce LaTent Reasoning Optimization (LaTRO), a principled framework that formulates reasoning as sampling from a latent distribution and optimizes it via variational approaches. LaTRO enables LLMs to concurrently improve both their reasoning process and ability to evaluate reasoning quality, without requiring external feedback or reward models. We validate LaTRO through experiments on GSM8K and ARC-Challenge datasets using multiple model architectures. On GSM8K, LaTRO improves zero-shot accuracy by an average of 12.5% over base models and 9.6% over supervised fine-tuning across Phi-3.5-mini, Mistral-7B, and Llama-3.1-8B. Our findings suggest that pre-trained LLMs possess latent reasoning capabilities that can be unlocked and enhanced through our proposed optimization approach in a self-improvement manner. The code of LaTRO is available at \url{https://github.com/SalesforceAIResearch/LaTRO}.