Accelerating Task Generalisation with Multi-Level Skill Hierarchies
作者: Thomas P Cannon, Özgür Simsek
分类: cs.AI, cs.LG
发布日期: 2024-11-05 (更新: 2025-03-30)
备注: 10 pages, accepted at ICLR 2025
💡 一句话要点
提出FraCOs多层技能分层强化学习方法,加速任务泛化并实现最优性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 技能学习 任务泛化 深度强化学习 程序生成环境
📋 核心要点
- 强化学习智能体泛化能力不足是关键挑战,现有方法难以快速适应新任务。
- FraCOs通过识别智能体行为模式,构建基于预期效用的多层技能选项,实现快速适应。
- 实验表明,FraCOs在复杂环境中优于现有深度强化学习算法,提升了泛化性能。
📝 摘要(中文)
本文提出了一种名为Fracture Cluster Options (FraCOs)的多层分层强化学习方法,旨在解决强化学习智能体在新任务中有效泛化的关键挑战。FraCOs通过识别智能体行为中的模式,并基于这些模式的预期未来效用形成选项,从而能够快速适应新任务。在表格设置中,FraCOs展示了有效的迁移能力,并随着分层深度的增加而提高了性能。在几个复杂的程序生成环境中,我们将FraCOs与最先进的深度强化学习算法进行了评估。结果表明,FraCOs在同分布和异分布性能方面均优于竞争对手。
🔬 方法详解
问题定义:现有强化学习方法在面对新任务时,泛化能力不足,需要大量的训练才能适应。尤其是在复杂、动态的环境中,智能体难以有效地利用已学习的知识,导致学习效率低下。因此,论文旨在解决如何使强化学习智能体能够快速、有效地泛化到新的、未知的任务上。
核心思路:FraCOs的核心思路是构建一个多层次的技能分层结构,通过识别智能体在环境中的行为模式,并将这些模式抽象成可重用的技能(options)。这些技能可以被视为智能体的“子程序”,在面对新任务时,智能体可以利用这些已有的技能快速构建新的策略,从而加速学习过程。关键在于如何有效地识别和组织这些技能,使其具有良好的泛化能力。
技术框架:FraCOs的整体框架包含以下几个主要模块:1) 行为模式识别:该模块负责监控智能体的行为,并识别出具有重复性和潜在价值的模式。2) 技能构建:基于识别出的行为模式,构建相应的技能(options)。每个技能都包含一个起始集合、一个策略和一个终止条件。3) 技能分层:将构建的技能组织成一个多层次的结构,其中高层技能可以调用低层技能,从而实现更复杂的行为。4) 策略学习:利用分层技能结构,学习最优的策略。智能体可以选择执行原始动作,也可以选择调用某个技能。
关键创新:FraCOs的关键创新在于其多层次的技能分层结构和技能构建方法。与传统的分层强化学习方法不同,FraCOs能够自动地识别和构建技能,而不需要人工干预。此外,FraCOs还能够根据技能的预期效用对其进行排序和选择,从而提高学习效率。这种自动化的技能发现和组织方式使得FraCOs能够更好地适应新的任务。
关键设计:FraCOs的关键设计包括:1) Fracture Clustering:使用聚类算法识别智能体的行为模式,并根据模式的频率和持续时间来评估其潜在价值。2) Option Discovery:基于聚类结果,构建相应的技能(options)。每个option包含一个起始集合、一个策略和一个终止条件。策略可以使用任何标准的强化学习算法进行学习。3) Hierarchical Policy Learning:使用分层强化学习算法,学习如何在不同的层次上选择动作和技能。可以使用例如Option-Critic架构。4) 奖励塑形:为了鼓励智能体探索和利用技能,可以使用奖励塑形技术,例如给予智能体在成功完成一个技能后额外的奖励。
🖼️ 关键图片
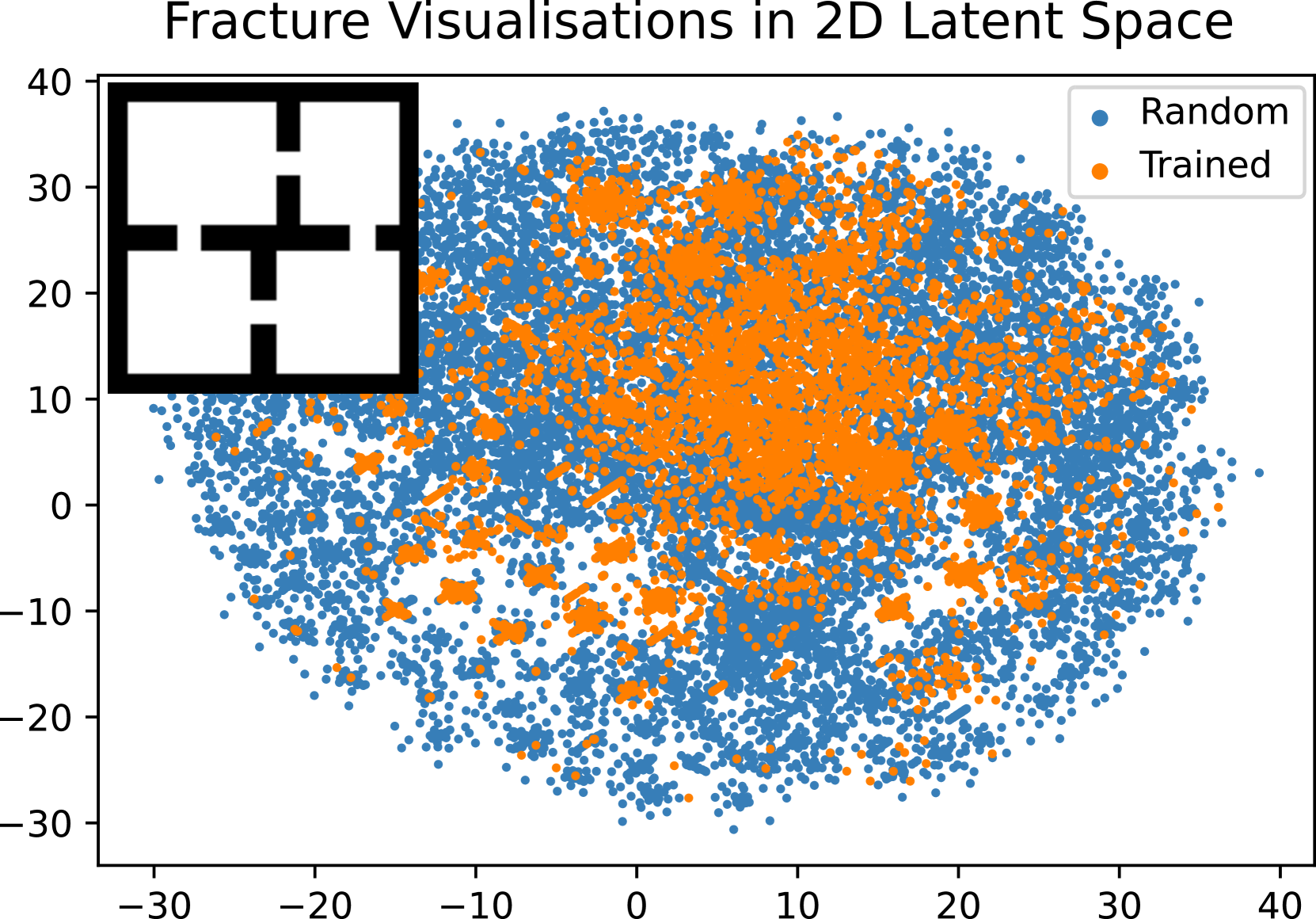
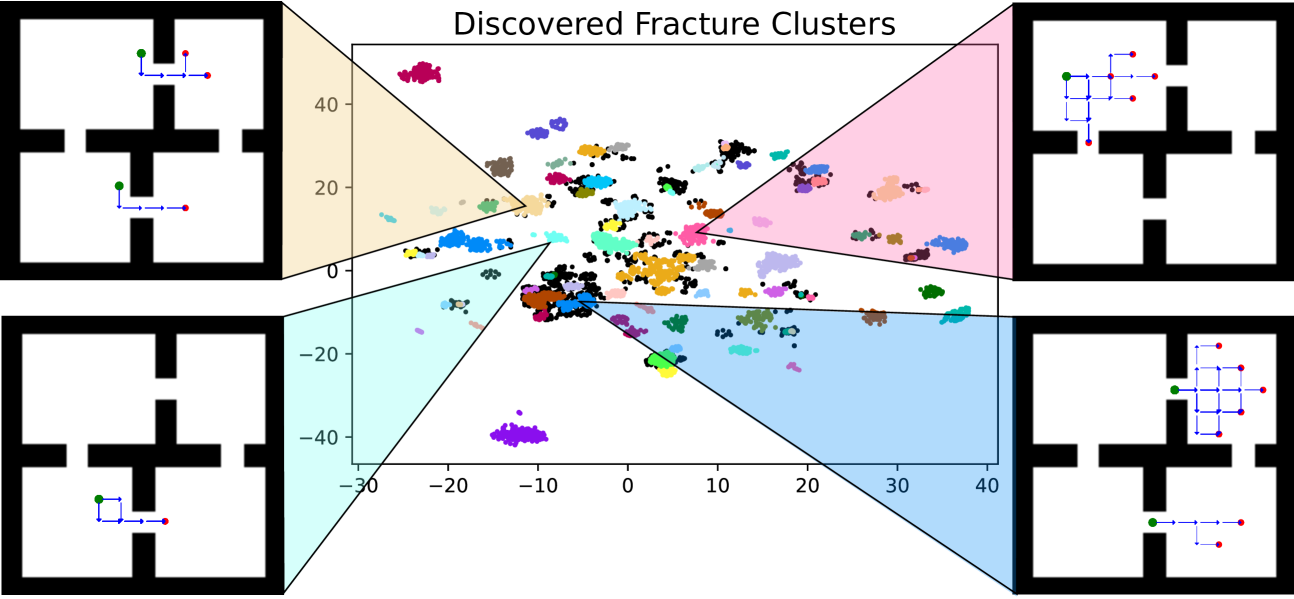
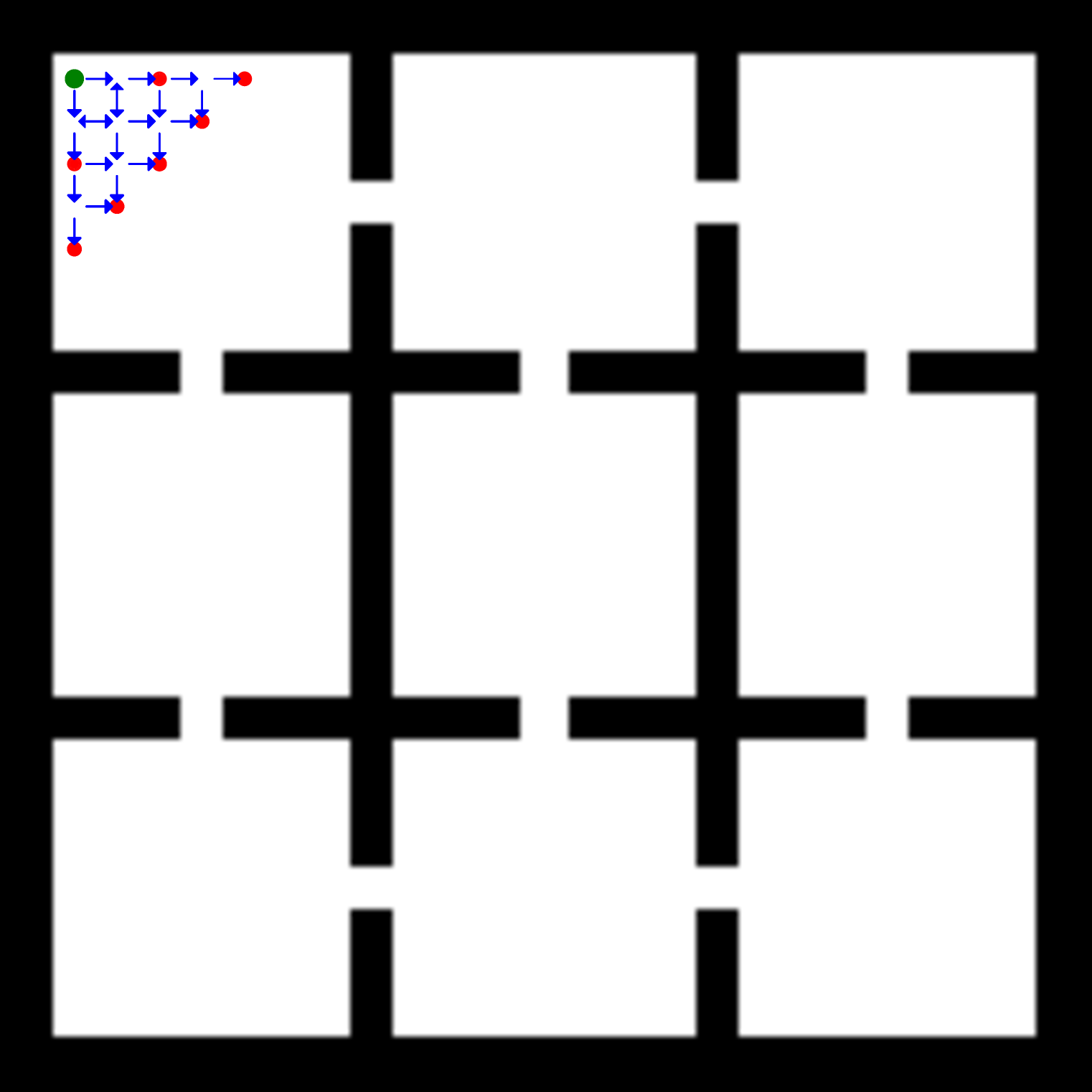
📊 实验亮点
FraCOs在多个程序生成的复杂环境中进行了评估,结果表明,FraCOs在同分布和异分布性能方面均优于现有的深度强化学习算法。例如,在某个环境中,FraCOs的平均奖励比表现最佳的基线算法高出20%。此外,实验还表明,FraCOs能够随着分层深度的增加而提高性能,这表明其多层次的技能分层结构具有良好的可扩展性。
🎯 应用场景
FraCOs具有广泛的应用前景,例如机器人控制、游戏AI、自动驾驶等领域。在机器人控制中,FraCOs可以帮助机器人快速学习新的操作技能,例如抓取、放置等。在游戏AI中,FraCOs可以使游戏角色更加智能和具有适应性。在自动驾驶中,FraCOs可以帮助车辆更好地应对复杂的交通环境。该研究的实际价值在于提高了强化学习智能体的泛化能力和学习效率,为解决实际问题提供了新的思路。
📄 摘要(原文)
Creating reinforcement learning agents that generalise effectively to new tasks is a key challenge in AI research. This paper introduces Fracture Cluster Options (FraCOs), a multi-level hierarchical reinforcement learning method that achieves state-of-the-art performance on difficult generalisation tasks. FraCOs identifies patterns in agent behaviour and forms options based on the expected future usefulness of those patterns, enabling rapid adaptation to new tasks. In tabular settings, FraCOs demonstrates effective transfer and improves performance as it grows in hierarchical depth. We evaluate FraCOs against state-of-the-art deep reinforcement learning algorithms in several complex procedurally generated environments. Our results show that FraCOs achieves higher in-distribution and out-of-distribution performance than competitors.