Autonomous Decision Making for UAV Cooperative Pursuit-Evasion Game with Reinforcement Learning
作者: Yang Zhao, Zidong Nie, Kangsheng Dong, Qinghua Huang, Xuelong Li
分类: cs.AI, cs.MA, cs.RO
发布日期: 2024-11-05
备注: 11 pages, 12 figures, 31 conference
💡 一句话要点
提出基于强化学习的多无人机协同追逃自主决策模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无人机 强化学习 协同控制 追逃博弈 深度Q网络
📋 核心要点
- 现有无人机追逃博弈研究较少关注多无人机协同,且在高维状态空间下训练效率低下。
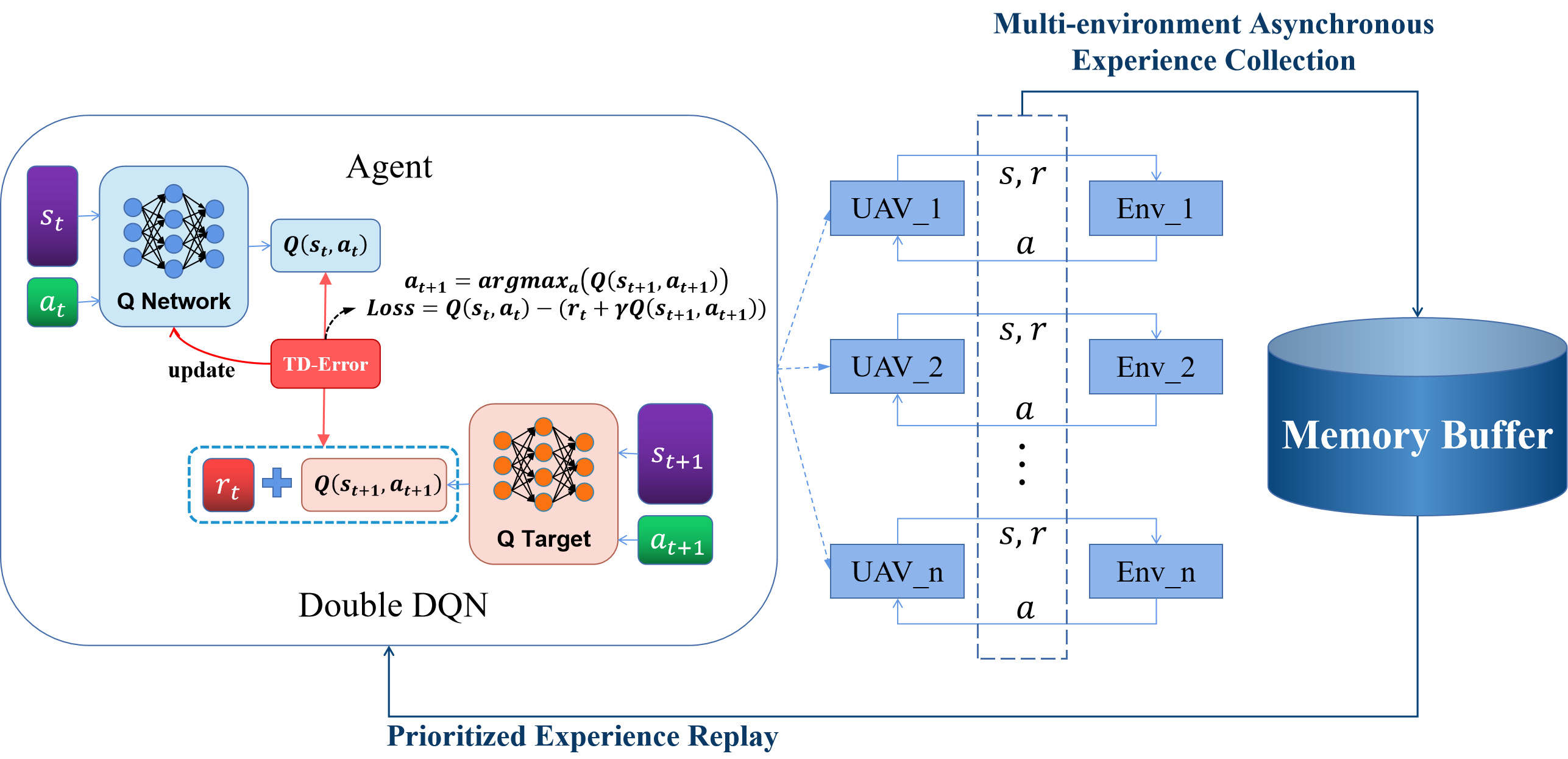
- 提出基于多环境异步双深度Q网络与优先经验回放的强化学习算法,提升训练效率。
- 通过角色和目标分配,构建不同无人机数量下的协同博弈决策模型,提升协同能力。
📝 摘要(中文)
本文提出了一种基于深度强化学习的多角色无人机协同追逃博弈决策模型,旨在解决无人机在复杂博弈环境中自主决策的难题。针对高维状态-动作空间下强化学习算法训练效率低下的问题,提出了一种多环境异步双深度Q网络(Asynchronous Double Deep Q-Network)与优先经验回放算法相结合的方法,以有效训练无人机的博弈策略。此外,为了提高协同能力和任务完成效率,并最小化无人机在追逃博弈中的成本,本文侧重于多无人机环境中的角色和目标分配。通过为不同场景中的无人机分配不同的任务和角色,获得了具有不同数量无人机的协同博弈决策模型。仿真结果表明,该方法能够使无人机在追逃博弈场景中实现自主决策,并表现出显著的协同能力。
🔬 方法详解
问题定义:论文旨在解决多无人机协同追逃博弈中,无人机如何在复杂环境中进行自主决策的问题。现有方法在处理高维状态-动作空间时,强化学习算法的训练效率较低,并且缺乏有效的协同策略,导致任务完成效率不高,成本较高。
核心思路:论文的核心思路是利用深度强化学习,通过训练使无人机能够自主学习在追逃博弈中的最优策略。为了提高训练效率,采用了多环境异步训练和优先经验回放。同时,通过角色和目标分配,实现无人机之间的有效协同,从而提高任务完成效率并降低成本。
技术框架:整体框架包括以下几个主要模块:1) 多环境异步训练:多个环境并行运行,加速数据收集;2) 双深度Q网络(Double Deep Q-Network):解决Q值高估问题;3) 优先经验回放:优先回放更有价值的经验,提高学习效率;4) 角色和目标分配模块:根据场景为无人机分配不同的角色和目标,实现协同。
关键创新:论文的关键创新在于将多环境异步训练、双深度Q网络和优先经验回放相结合,有效地解决了高维状态-动作空间下强化学习训练效率低下的问题。此外,通过角色和目标分配,实现了多无人机之间的有效协同,提高了任务完成效率和降低了成本。
关键设计:论文中,多环境异步训练采用多个独立的训练环境,每个环境都有自己的智能体副本。优先经验回放根据TD误差的大小来确定经验的优先级,TD误差越大,优先级越高。角色和目标分配模块根据无人机的数量和场景的复杂程度,动态地为无人机分配不同的角色(追捕者或逃避者)和目标。
🖼️ 关键图片


📊 实验亮点
仿真结果表明,所提出的方法能够使无人机在追逃博弈场景中实现自主决策,并表现出显著的协同能力。具体性能数据未知,但论文强调了该方法在协同能力方面的提升,以及在复杂环境下的适应性。
🎯 应用场景
该研究成果可应用于无人机集群协同作战、搜索救援、环境监测等领域。通过自主决策和协同配合,无人机能够更高效地完成复杂任务,降低人力成本,提高任务的安全性。未来,该技术有望在智慧城市、智能交通等领域发挥重要作用。
📄 摘要(原文)
The application of intelligent decision-making in unmanned aerial vehicle (UAV) is increasing, and with the development of UAV 1v1 pursuit-evasion game, multi-UAV cooperative game has emerged as a new challenge. This paper proposes a deep reinforcement learning-based model for decision-making in multi-role UAV cooperative pursuit-evasion game, to address the challenge of enabling UAV to autonomously make decisions in complex game environments. In order to enhance the training efficiency of the reinforcement learning algorithm in UAV pursuit-evasion game environment that has high-dimensional state-action space, this paper proposes multi-environment asynchronous double deep Q-network with priority experience replay algorithm to effectively train the UAV's game policy. Furthermore, aiming to improve cooperation ability and task completion efficiency, as well as minimize the cost of UAVs in the pursuit-evasion game, this paper focuses on the allocation of roles and targets within multi-UAV environment. The cooperative game decision model with varying numbers of UAVs are obtained by assigning diverse tasks and roles to the UAVs in different scenarios. The simulation results demonstrate that the proposed method enables autonomous decision-making of the UAVs in pursuit-evasion game scenarios and exhibits significant capabilities in cooperation.