Enhancing ID-based Recommendation with Large Language Models
作者: Lei Chen, Chen Gao, Xiaoyi Du, Hengliang Luo, Depeng Jin, Yong Li, Meng Wang
分类: cs.IR, cs.AI
发布日期: 2024-11-04
💡 一句话要点
提出LLM4IDRec,利用大语言模型增强ID信息,提升ID-based推荐性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: ID-based推荐 大语言模型 数据增强 推荐系统 用户建模
📋 核心要点
- 现有研究主要利用LLM处理推荐系统中的文本数据,而忽略了ID-based推荐中仅有ID数据的情况,LLM在ID数据上的潜力未被充分挖掘。
- LLM4IDRec的核心思想是利用LLM增强ID数据,通过观察增强后的ID数据是否能提升推荐性能,来验证LLM解释ID数据的能力。
- 实验结果表明,LLM4IDRec在三个数据集上均优于现有ID-based推荐方法,证明了LLM在ID数据增强方面的有效性。
📝 摘要(中文)
本文提出了一种名为“LLM for ID-based Recommendation (LLM4IDRec)”的创新方法,旨在探索大语言模型(LLMs)在ID-based推荐系统中的潜力。与以往利用LLMs处理文本数据的研究不同,LLM4IDRec专注于仅使用ID数据来增强推荐性能。其核心思想是:如果通过LLM增强ID数据能够提升推荐效果,则证明LLM具备有效解释ID数据的能力,从而为LLM在ID-based推荐中的集成开辟新途径。在三个广泛使用的数据集上的实验结果表明,LLM4IDRec能够显著提升推荐性能,始终优于现有的ID-based推荐方法,且仅通过增强输入数据即可实现。
🔬 方法详解
问题定义:论文旨在解决ID-based推荐系统中,如何有效利用大语言模型(LLMs)提升推荐性能的问题。现有方法主要集中于利用LLMs处理文本数据,而忽略了ID-based推荐中仅有ID数据的情况,导致LLMs在ID数据上的潜力未被充分挖掘。
核心思路:论文的核心思路是利用LLMs来增强ID数据。如果通过LLM增强ID数据后,推荐性能得到提升,则表明LLM能够有效地解释和利用ID数据中的潜在信息。这种方法探索了一种将LLMs集成到ID-based推荐系统中的新途径。
技术框架:LLM4IDRec的整体框架包含以下几个主要阶段:1) ID数据输入:将原始ID数据输入到LLM中;2) LLM增强:利用LLM对ID数据进行增强,生成新的ID表示;3) 推荐模型:将增强后的ID表示输入到推荐模型中进行训练和预测;4) 性能评估:评估推荐模型的性能,验证LLM增强ID数据的有效性。
关键创新:该论文最重要的技术创新点在于,它首次探索了利用LLMs直接增强ID数据以提升ID-based推荐性能的方法。与现有方法不同,LLM4IDRec不依赖于任何文本信息,而是直接利用LLMs的强大表征能力来挖掘ID数据中的潜在信息。
关键设计:论文中关于LLM的具体使用方式(例如prompt设计、微调策略等)以及推荐模型的选择(例如,基于矩阵分解的模型或深度学习模型)的具体技术细节未知。损失函数和网络结构等细节也未在摘要中提及,需要查阅论文全文才能得知。
🖼️ 关键图片

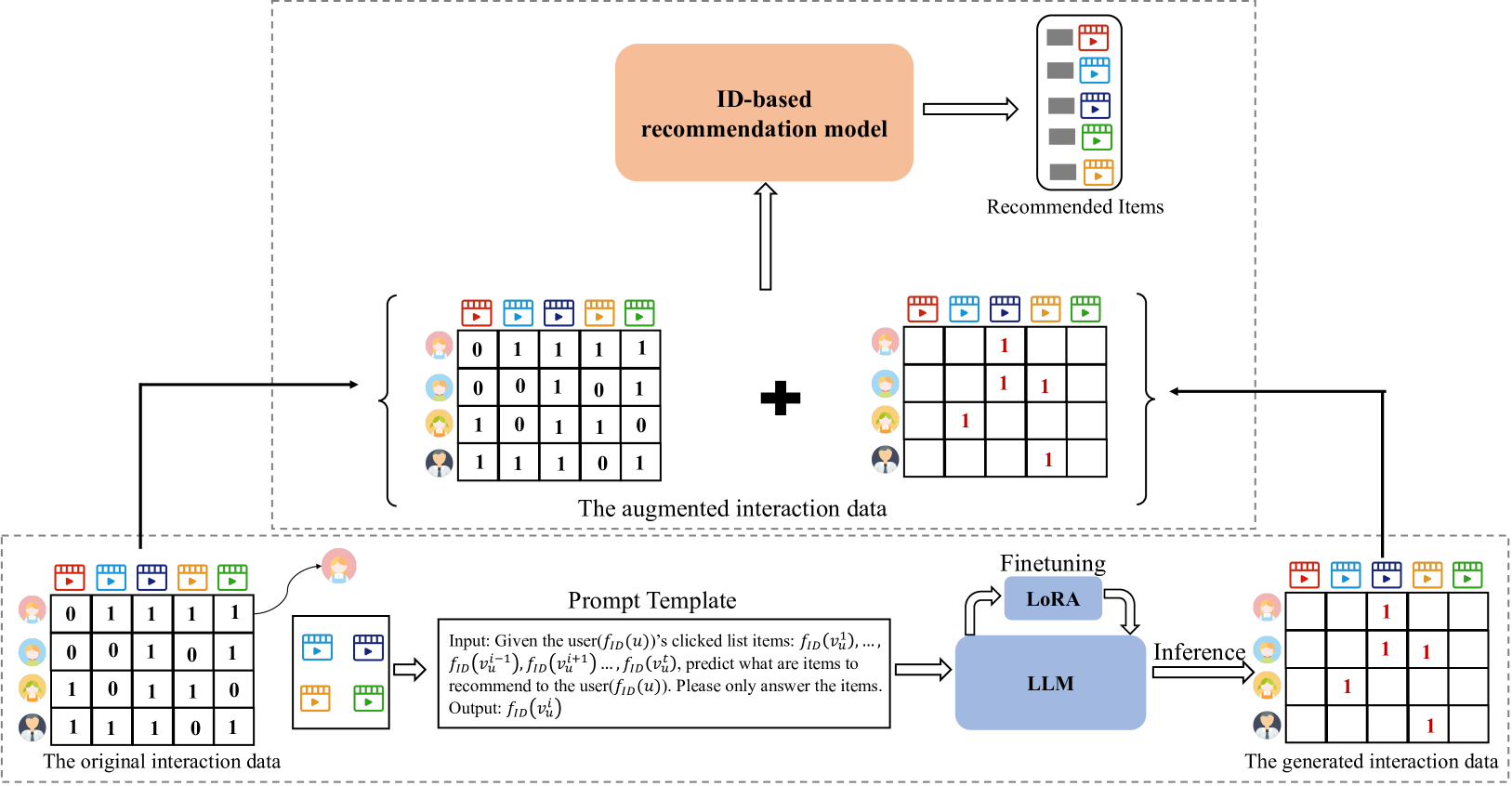

📊 实验亮点
实验结果表明,LLM4IDRec在三个广泛使用的数据集上均取得了显著的性能提升,始终优于现有的ID-based推荐方法。具体的性能数据和提升幅度未知,需要在论文全文中查找。该结果证明了LLM在ID数据增强方面的有效性,为LLM在ID-based推荐中的应用提供了有力支持。
🎯 应用场景
LLM4IDRec具有广泛的应用前景,可应用于电商推荐、音乐推荐、电影推荐等各种ID-based推荐场景。通过利用LLM增强ID数据,可以提升推荐系统的准确性和个性化程度,从而改善用户体验,提高平台收益。该研究为未来LLM在ID-based推荐领域的应用提供了新的思路和方向。
📄 摘要(原文)
Large Language Models (LLMs) have recently garnered significant attention in various domains, including recommendation systems. Recent research leverages the capabilities of LLMs to improve the performance and user modeling aspects of recommender systems. These studies primarily focus on utilizing LLMs to interpret textual data in recommendation tasks. However, it's worth noting that in ID-based recommendations, textual data is absent, and only ID data is available. The untapped potential of LLMs for ID data within the ID-based recommendation paradigm remains relatively unexplored. To this end, we introduce a pioneering approach called "LLM for ID-based Recommendation" (LLM4IDRec). This innovative approach integrates the capabilities of LLMs while exclusively relying on ID data, thus diverging from the previous reliance on textual data. The basic idea of LLM4IDRec is that by employing LLM to augment ID data, if augmented ID data can improve recommendation performance, it demonstrates the ability of LLM to interpret ID data effectively, exploring an innovative way for the integration of LLM in ID-based recommendation. We evaluate the effectiveness of our LLM4IDRec approach using three widely-used datasets. Our results demonstrate a notable improvement in recommendation performance, with our approach consistently outperforming existing methods in ID-based recommendation by solely augmenting input data.