Ontology Population using LLMs
作者: Sanaz Saki Norouzi, Adrita Barua, Antrea Christou, Nikita Gautam, Andrew Eells, Pascal Hitzler, Cogan Shimizu
分类: cs.AI, cs.CL
发布日期: 2024-11-03
💡 一句话要点
利用大型语言模型进行本体填充,提升知识图谱构建效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 本体填充 大型语言模型 自然语言处理 提示工程
📋 核心要点
- 知识图谱构建面临从非结构化文本中提取信息的挑战,现有方法成本高昂且易受歧义影响。
- 该论文探索利用大型语言模型进行知识图谱填充,通过提示工程和微调来提升数据提取的准确性。
- 实验结果表明,在模块化本体的指导下,大型语言模型能够提取约90%的正确三元组,验证了其有效性。
📝 摘要(中文)
知识图谱(KGs)越来越多地被用于数据集成、表示和可视化。KG填充至关重要,但成本通常很高,尤其是在必须从自然语言的非结构化文本中提取数据时,这带来了歧义和复杂解释等挑战。大型语言模型(LLMs)为此类任务提供了有希望的能力,擅长自然语言理解和内容生成。然而,它们“幻觉”的倾向会产生不准确的输出。尽管存在这些限制,LLMs提供了对自然语言数据的快速和可扩展的处理,通过提示工程和微调,它们可以近似人类水平的性能,以提取和构建KG的数据。本研究调查了LLM在KG填充方面的有效性,重点关注Enslaved.org Hub Ontology。在本文中,我们报告说,与真实情况相比,当在提示中提供模块化本体作为指导时,LLM可以提取约90%的三元组。
🔬 方法详解
问题定义:知识图谱的构建依赖于从各种来源(特别是自然语言文本)提取信息。现有的知识图谱填充方法,尤其是从非结构化文本中提取信息时,面临着高成本、低效率以及易受歧义和复杂解释影响等问题。这些问题阻碍了知识图谱的快速构建和更新。
核心思路:该论文的核心思路是利用大型语言模型(LLMs)在自然语言理解和生成方面的强大能力,自动化知识图谱的填充过程。通过精心设计的提示工程和微调,引导LLMs从文本中提取结构化信息,并将其转化为知识图谱中的三元组。这种方法旨在降低人工成本,提高填充效率,并减少歧义带来的错误。
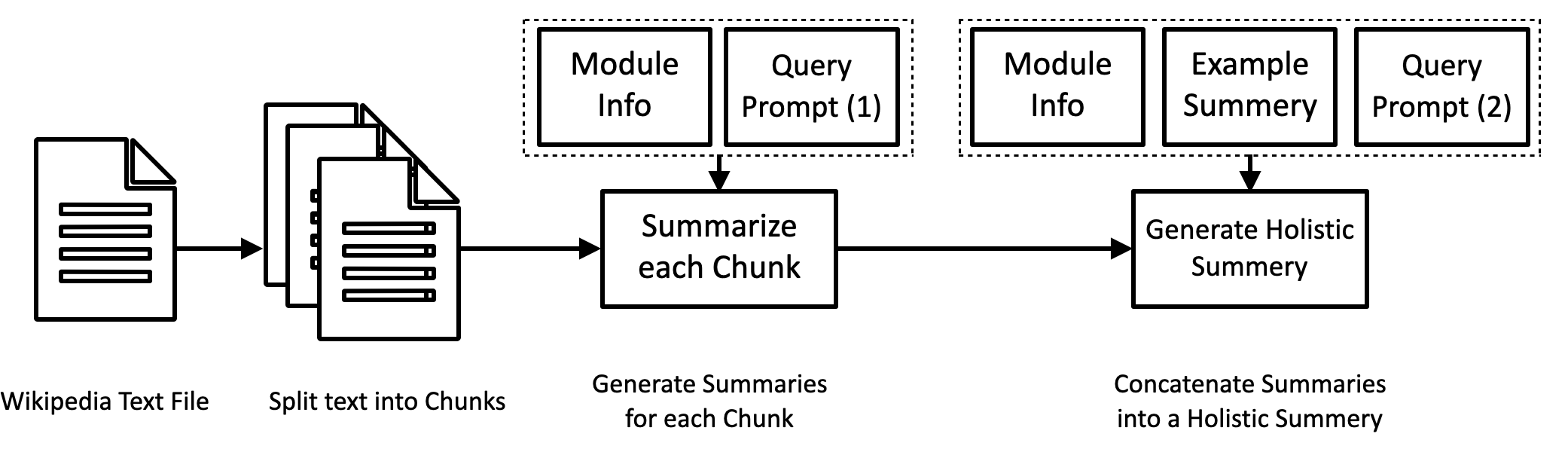
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择目标本体(Enslaved.org Hub Ontology);2) 设计提示模板,将本体信息融入提示中,引导LLM提取特定类型的三元组;3) 使用LLM处理文本数据,生成候选三元组;4) 将LLM的输出与真实数据进行比较,评估LLM的性能。该框架的核心在于提示工程,通过模块化的本体信息指导LLM进行知识抽取。
关键创新:该论文的关键创新在于将模块化的本体信息融入到LLM的提示中,从而有效地指导LLM进行知识图谱填充。这种方法利用了LLM的自然语言理解能力,同时通过本体的约束减少了LLM产生“幻觉”的可能性,提高了提取的准确性。与传统的知识抽取方法相比,该方法无需大量的人工标注数据,具有更高的效率和可扩展性。
关键设计:该研究的关键设计包括:1) 模块化本体的设计,将本体分解为多个模块,每个模块对应特定类型的关系或实体;2) 提示模板的设计,确保提示清晰、简洁,并包含足够的上下文信息,以便LLM能够准确理解任务;3) 评估指标的选择,使用准确率、召回率等指标来评估LLM的性能,并与真实数据进行比较。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在模块化本体的指导下,大型语言模型能够提取约90%的正确三元组。这一结果显著高于传统方法,验证了该方法在知识图谱填充方面的有效性。该研究为利用大型语言模型构建知识图谱提供了一种新的思路和方法。
🎯 应用场景
该研究成果可应用于多种场景,例如:自动构建特定领域的知识图谱,提升搜索引擎的语义理解能力,辅助智能问答系统进行知识推理,以及在历史研究等领域中进行数据挖掘和分析。通过自动化知识图谱填充,可以加速知识的积累和应用,为各行各业提供更智能化的服务。
📄 摘要(原文)
Knowledge graphs (KGs) are increasingly utilized for data integration, representation, and visualization. While KG population is critical, it is often costly, especially when data must be extracted from unstructured text in natural language, which presents challenges, such as ambiguity and complex interpretations. Large Language Models (LLMs) offer promising capabilities for such tasks, excelling in natural language understanding and content generation. However, their tendency to ``hallucinate'' can produce inaccurate outputs. Despite these limitations, LLMs offer rapid and scalable processing of natural language data, and with prompt engineering and fine-tuning, they can approximate human-level performance in extracting and structuring data for KGs. This study investigates LLM effectiveness for the KG population, focusing on the Enslaved.org Hub Ontology. In this paper, we report that compared to the ground truth, LLM's can extract ~90% of triples, when provided a modular ontology as guidance in the prompts.