What Features in Prompts Jailbreak LLMs? Investigating the Mechanisms Behind Attacks
作者: Nathalie Kirch, Constantin Weisser, Severin Field, Helen Yannakoudakis, Stephen Casper
分类: cs.CR, cs.AI, cs.CL
发布日期: 2024-11-02 (更新: 2025-11-01)
💡 一句话要点
通过探究Prompt中的特征,揭示LLM越狱攻击的内在机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 安全性 非线性特征 因果干预
📋 核心要点
- 现有方法主要依赖线性模型检测越狱攻击,忽略了Prompt中可能存在的非线性特征,导致对攻击机制理解不足。
- 本文提出一种基于线性和非线性探针的方法,分析Prompt中的特征与越狱成功之间的关系,并进行因果干预验证。
- 实验表明,越狱攻击的成功与Prompt中的非线性特征密切相关,且不同攻击方式依赖于不同的内部机制。
📝 摘要(中文)
越狱攻击一直是大型语言模型(LLM)安全性和可靠性研究的核心。然而,这些攻击背后的机制仍然知之甚少。与以往主要依赖线性方法检测越狱尝试和建模拒绝的研究不同,本文采用不同的方法,检查提示中导致成功越狱的线性和非线性特征。首先,本文引入了一个包含10800个越狱尝试的新数据集,涵盖35种不同的攻击方法。利用该数据集,本文在开放权重LLM的隐藏状态上训练线性和非线性探针,以预测越狱成功。探针实现了强大的同分布准确率,但迁移能力是攻击族特定的,这表明不同的越狱攻击由不同的内部机制支持,而不是单一的通用方向。为了建立因果关系,本文构建了探针引导的潜在干预,系统地改变预测方向的合规性。来自非线性探针的干预比来自线性探针的干预产生更大且更可靠的效果,表明与越狱成功相关的特征以非线性方式编码在提示表示中。总的来说,结果揭示了越狱机制中异构的非线性结构,并提供了一种提示侧方法,用于恢复和测试驱动越狱结果的特征。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)容易受到越狱攻击,即通过精心设计的Prompt绕过模型的安全限制,使其产生有害或不当的输出。以往的研究主要集中在线性方法检测越狱尝试,但忽略了Prompt中可能存在的非线性特征,导致对越狱攻击内在机制的理解不足。因此,如何理解Prompt中的哪些特征导致了越狱攻击的成功,以及这些特征是如何影响LLM的行为,是本文要解决的核心问题。
核心思路:本文的核心思路是通过训练探针来预测越狱攻击的成功,并分析这些探针所关注的Prompt特征。具体来说,本文首先构建了一个包含大量越狱尝试的数据集,然后利用这些数据训练线性和非线性探针,以预测给定Prompt是否能够成功越狱LLM。通过分析探针的权重和激活模式,可以识别出与越狱攻击相关的Prompt特征。此外,本文还通过因果干预实验,验证这些特征与越狱攻击之间的因果关系。
技术框架:本文的技术框架主要包括以下几个步骤:1) 构建越狱攻击数据集:收集各种越狱攻击方法生成的Prompt,并标注其是否成功越狱LLM。2) 训练线性和非线性探针:利用越狱攻击数据集,在LLM的隐藏状态上训练线性和非线性探针,以预测越狱攻击的成功。3) 分析探针的权重和激活模式:分析探针的权重和激活模式,识别与越狱攻击相关的Prompt特征。4) 进行因果干预实验:通过修改Prompt中的相关特征,观察LLM的输出是否发生变化,从而验证这些特征与越狱攻击之间的因果关系。
关键创新:本文最重要的技术创新点在于,它首次系统地研究了Prompt中的线性和非线性特征与越狱攻击之间的关系。与以往主要关注线性方法的研究不同,本文发现越狱攻击的成功与Prompt中的非线性特征密切相关。此外,本文还通过因果干预实验,验证了这些特征与越狱攻击之间的因果关系。
关键设计:在探针的设计方面,本文使用了线性和非线性两种探针。线性探针是一个简单的线性分类器,而非线性探针则是一个多层感知机。在训练探针时,本文使用了交叉熵损失函数,并采用Adam优化器进行优化。在因果干预实验中,本文通过修改Prompt中的相关特征,例如添加或删除某些关键词,来观察LLM的输出是否发生变化。
🖼️ 关键图片
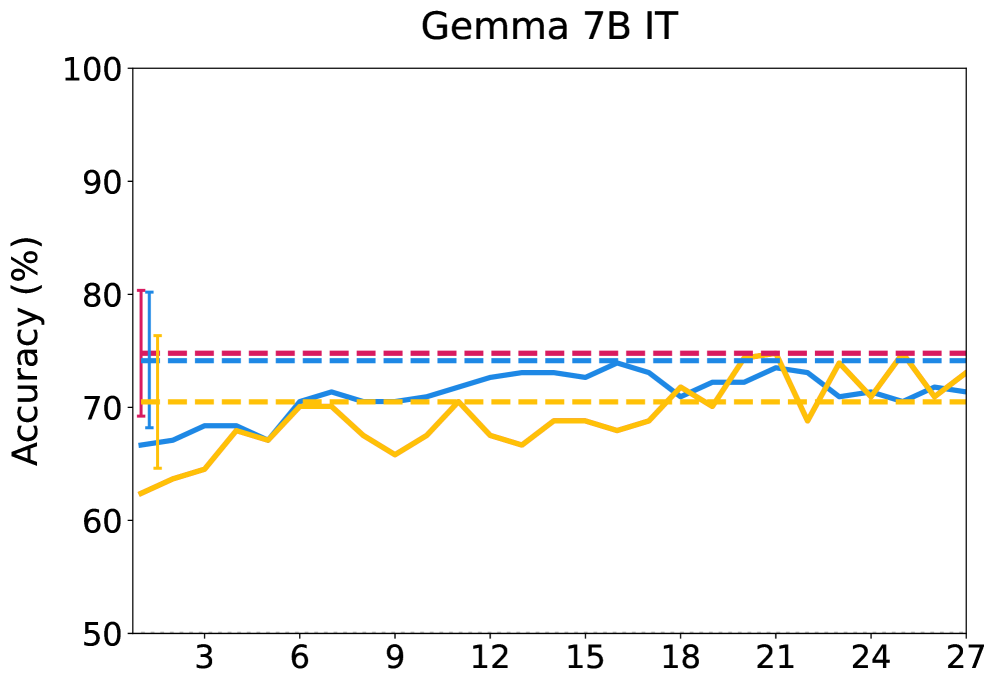
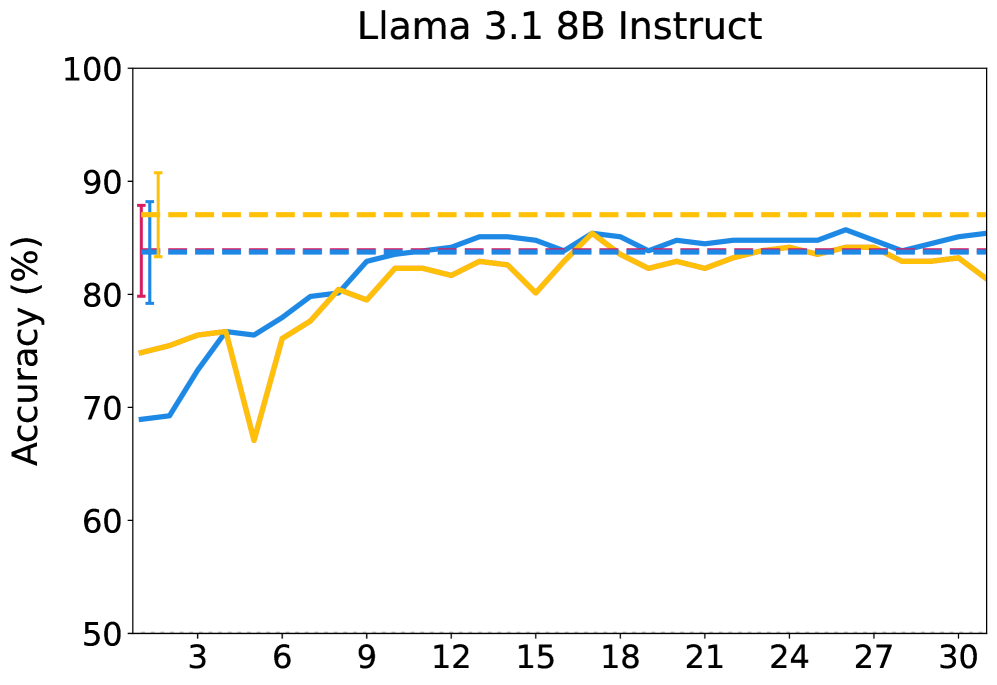
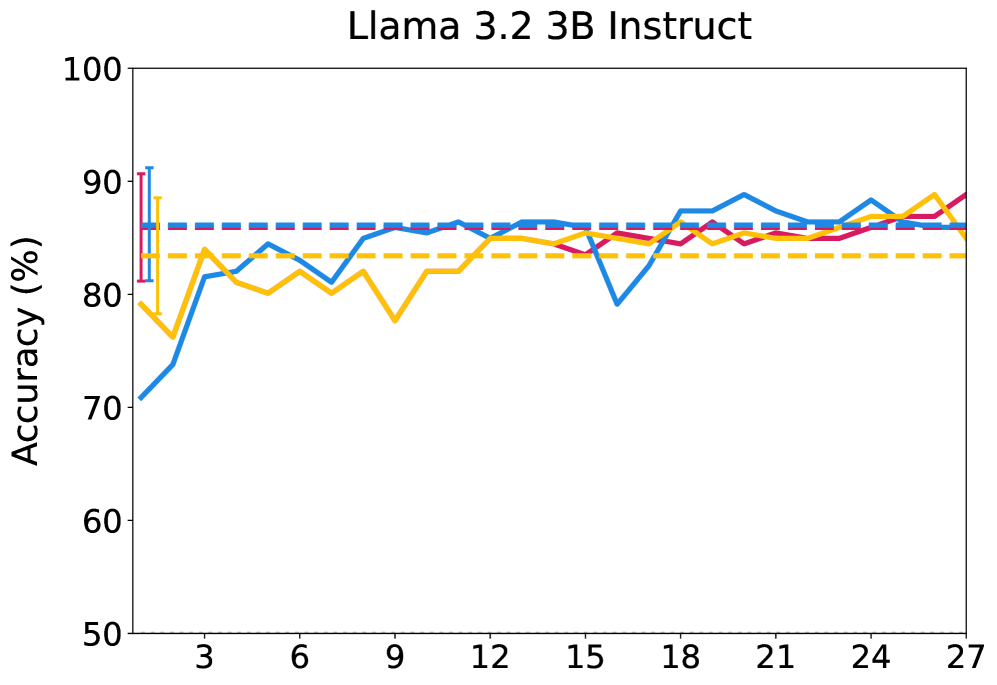
📊 实验亮点
本文构建了一个包含10800个越狱尝试的数据集,涵盖35种不同的攻击方法。实验结果表明,非线性探针在预测越狱攻击成功率方面优于线性探针,并且不同攻击族依赖于不同的内部机制。通过探针引导的潜在干预,非线性探针比线性探针产生更大且更可靠的效果。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性,通过识别和消除Prompt中易受攻击的特征,提高模型抵御越狱攻击的能力。此外,该研究还可以帮助开发更有效的越狱攻击检测方法,从而更好地保护LLM免受恶意利用。未来,该研究可以扩展到其他类型的安全漏洞,例如对抗性攻击和数据泄露。
📄 摘要(原文)
Jailbreaks have been a central focus of research regarding the safety and reliability of large language models (LLMs), yet the mechanisms underlying these attacks remain poorly understood. While previous studies have predominantly relied on linear methods to detect jailbreak attempts and model refusals, we take a different approach by examining both linear and non-linear features in prompts that lead to successful jailbreaks. First, we introduce a novel dataset comprising 10,800 jailbreak attempts spanning 35 diverse attack methods. Leveraging this dataset, we train linear and non-linear probes on hidden states of open-weight LLMs to predict jailbreak success. Probes achieve strong in-distribution accuracy but transfer is attack-family-specific, revealing that different jailbreaks are supported by distinct internal mechanisms rather than a single universal direction. To establish causal relevance, we construct probe-guided latent interventions that systematically shift compliance in the predicted direction. Interventions derived from non-linear probes produce larger and more reliable effects than those from linear probes, indicating that features linked to jailbreak success are encoded non-linearly in prompt representations. Overall, the results surface heterogeneous, non-linear structure in jailbreak mechanisms and provide a prompt-side methodology for recovering and testing the features that drive jailbreak outcomes.