TurtleBench: A Visual Programming Benchmark in Turtle Geometry
作者: Sina Rismanchian, Yasaman Razeghi, Sameer Singh, Shayan Doroudi
分类: cs.AI, cs.CV
发布日期: 2024-10-31 (更新: 2025-04-11)
🔗 代码/项目: GITHUB
💡 一句话要点
提出TurtleBench:一个基于Turtle几何的视觉编程评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉编程 多模态学习 几何推理 代码生成 基准测试
📋 核心要点
- 现有大型多模态模型在理解图像和场景中的几何模式方面存在不足,缺乏有效的评估方法来衡量这些能力。
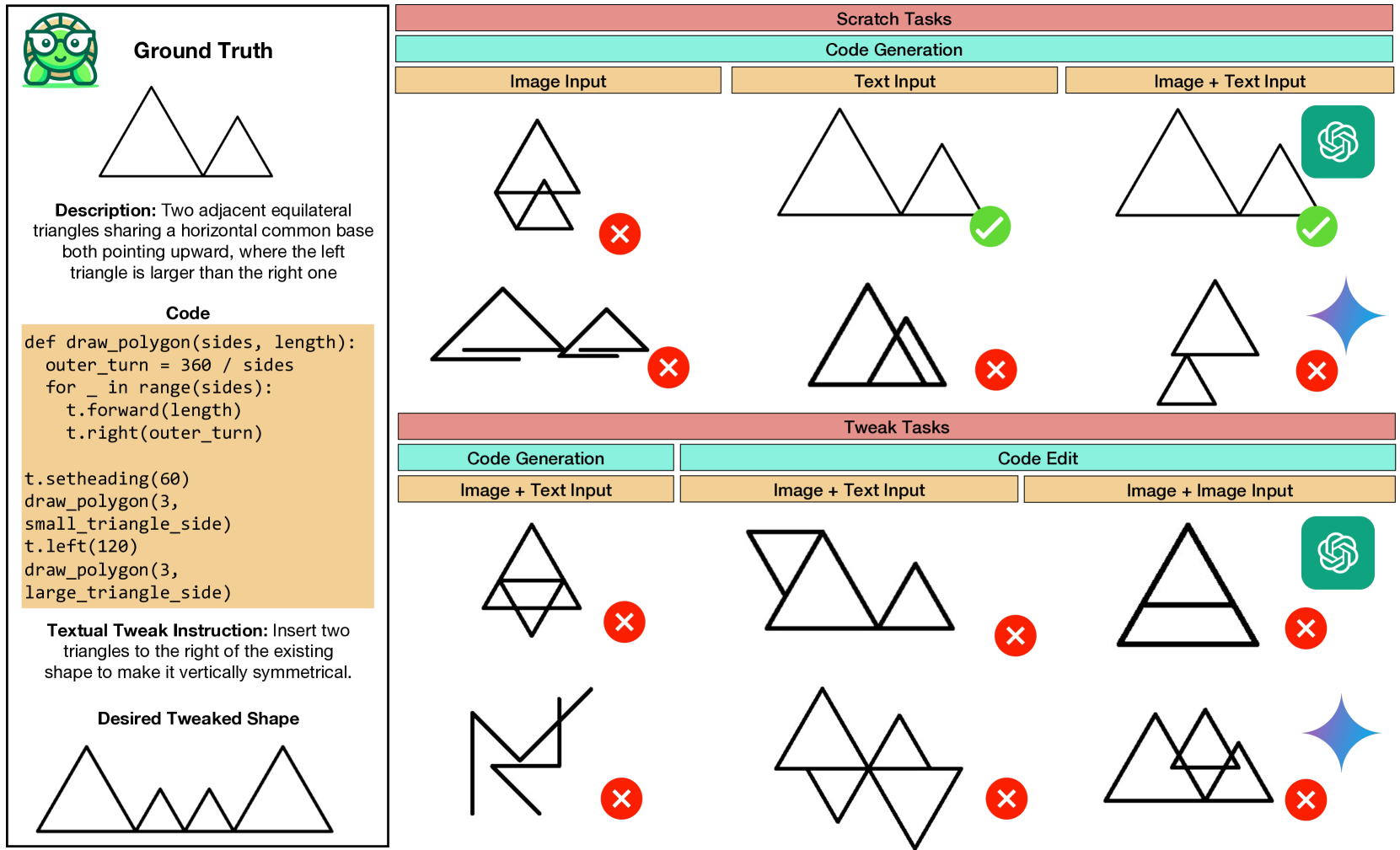
- TurtleBench基准通过模仿儿童学习几何概念的turtle几何,设计了一系列具有算法逻辑的图案形状任务。
- 实验结果表明,即使是GPT-4o等领先模型在TurtleBench上表现不佳,表明AI在几何理解方面与人类存在显著差距。
📝 摘要(中文)
本文介绍了一个名为TurtleBench的基准测试,旨在评估大型多模态模型(LMMs)解释几何模式的能力。该基准受到turtle几何的启发,包含具有潜在算法逻辑的图案形状任务,通过视觉示例、文本指令或两者结合的方式,要求模型生成精确的代码输出。评估结果表明,当前领先的LMMs在这些任务上表现不佳,即使是GPT-4o在最简单的任务上也仅达到19%的准确率,少样本提示仅略微提升性能(<2%)。TurtleBench突显了人类和AI在直观和视觉几何理解方面的差距,为该领域的未来研究奠定了基础。TurtleBench是为数不多的评估LMMs中视觉理解和代码生成能力集成的基准之一。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在理解和推理视觉几何模式方面的不足。现有方法难以有效评估LMMs的几何推理能力,缺乏一个专门用于测试视觉理解和代码生成相结合的基准。
核心思路:论文的核心思路是利用turtle几何的概念,创建一个包含一系列具有潜在算法逻辑的图案形状任务的基准。通过要求模型根据视觉示例和/或文本指令生成相应的代码,来评估其几何推理能力。
技术框架:TurtleBench基准包含一系列任务,每个任务都涉及生成特定几何图案的代码。模型接收视觉输入(例如,图案的图像)和/或文本指令(例如,描述图案的文本),并生成相应的代码作为输出。评估指标是生成的代码是否能够准确地绘制出目标图案。
关键创新:TurtleBench的关键创新在于其任务设计的灵感来源——turtle几何。这种几何方法强调通过一系列指令来控制一个“turtle”在平面上移动和绘制线条,从而生成复杂的图案。这种方法非常适合评估模型理解和生成算法逻辑的能力,而不仅仅是识别图像中的物体。
关键设计:TurtleBench的任务设计考虑了不同难度级别,从简单的基本形状到更复杂的图案。数据集包含视觉示例、文本指令和相应的代码解决方案。评估过程侧重于代码的准确性和效率,以及模型对不同输入模态的理解和整合能力。具体参数设置和网络结构取决于所评估的LMMs,但评估指标保持一致,以确保公平比较。
🖼️ 关键图片


📊 实验亮点
实验结果显示,即使是GPT-4o在TurtleBench的最简单任务上也仅达到19%的准确率,少样本提示仅带来微小的性能提升(<2%)。这些结果表明,当前领先的LMMs在视觉几何理解方面与人类存在显著差距,凸显了TurtleBench作为评估和推动该领域研究的重要价值。
🎯 应用场景
TurtleBench可用于评估和改进大型多模态模型在视觉几何理解和代码生成方面的能力。潜在应用包括机器人导航、计算机辅助设计、教育软件开发等领域,有助于提升AI在处理涉及空间推理和算法逻辑任务时的性能和可靠性。该基准的发布将促进相关领域的研究进展。
📄 摘要(原文)
Humans have the ability to reason about geometric patterns in images and scenes from a young age. However, developing large multimodal models (LMMs) capable of similar reasoning remains a challenge, highlighting the need for robust evaluation methods to assess these capabilities. We introduce \Turtle, a benchmark designed to evaluate LMMs' capacity to interpret geometric patterns -- given visual examples, textual instructions, or both -- and generate precise code outputs. Inspired by turtle geometry, a notion used to teach children foundational coding and geometric concepts, TurtleBench features tasks with patterned shapes that have underlying algorithmic logic. Our evaluation reveals that leading LMMs struggle significantly with these tasks, with GPT-4o achieving only 19\% accuracy on the simplest tasks and few-shot prompting only marginally improves their performance ($<2\%$). \Turtle highlights the gap between human and AI performance in intuitive and visual geometrical understanding, setting the stage for future research in this area. \Turtle stands as one of the few benchmarks to evaluate the integration of visual understanding and code generation capabilities in LMMs, setting the stage for future research. Code and Dataset for this paper is provided here: \href{https://github.com/sinaris76/TurtleBench}{https://github.com/sinaris76/TurtleBench}