Transferable & Stealthy Ensemble Attacks: A Black-Box Jailbreaking Framework for Large Language Models
作者: Yiqi Yang, Hongye Fu
分类: cs.CR, cs.AI
发布日期: 2024-10-31 (更新: 2025-11-06)
💡 一句话要点
提出可迁移且隐蔽的集成攻击框架,用于破解大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 黑盒攻击 集成攻击 可迁移性
📋 核心要点
- 现有越狱方法在面对防御性大型语言模型时,迁移性和隐蔽性不足,难以有效攻击。
- 采用集成攻击策略,结合多种攻击方法优势,并优化恶意指令的生成和语义连贯性。
- 在LLM安全竞赛中获得领先排名,验证了所提框架在越狱攻击方面的有效性和优越性。
📝 摘要(中文)
本文提出了一种新颖的黑盒越狱框架,该框架集成了多种“LLM-as-Attacker”策略,以实现高度可迁移和有效的攻击。该框架基于先前越狱研究和实践中的三个关键见解:集成方法在暴露对齐的LLM漏洞方面优于单一方法;恶意指令的越狱难度各不相同,需要定制优化;破坏恶意提示的语义连贯性可以操纵其嵌入,从而提高成功率。我们的解决方案在2024年LLM和Agent安全竞赛中得到验证,并在越狱攻击赛道中名列前茅。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的越狱问题,即如何绕过LLM的安全对齐机制,使其生成有害或不当内容。现有方法,尤其是黑盒攻击方法,通常存在迁移性差、隐蔽性低的问题,难以有效攻击部署了防御机制的LLM。
核心思路:论文的核心思路是利用集成攻击策略,将多个“LLM-as-Attacker”策略结合起来,发挥各自的优势,提高攻击的成功率和迁移性。同时,通过破坏恶意提示的语义连贯性,操纵其嵌入,进一步提升攻击效果。此外,针对不同难度的恶意指令进行定制优化,提高攻击效率。
技术框架:该框架包含多个LLM-as-Attacker模块,每个模块采用不同的攻击策略生成恶意提示。这些提示经过集成后,输入到目标LLM中进行攻击。框架还包括一个优化模块,用于根据恶意指令的难度调整攻击策略,并破坏提示的语义连贯性。整体流程为:(1)多个LLM-as-Attacker生成初始提示;(2)优化模块调整提示,破坏语义连贯性;(3)集成后的提示输入目标LLM;(4)评估攻击效果。
关键创新:该论文的关键创新在于提出了一个可迁移且隐蔽的集成攻击框架,该框架结合了多种攻击策略,并针对恶意指令的难度进行定制优化。通过破坏提示的语义连贯性,进一步提高了攻击的成功率。这种集成攻击策略能够有效应对LLM的防御机制,提高攻击的鲁棒性和泛化能力。
关键设计:具体的技术细节包括:(1)选择合适的LLM-as-Attacker策略,例如Prompt Injection、Goal Hijacking等;(2)设计优化模块,用于调整提示的语义连贯性,例如通过插入无关字符、改变词序等方式;(3)采用合适的集成方法,例如加权平均、投票等;(4)设计评估指标,用于衡量攻击的成功率和隐蔽性。
🖼️ 关键图片
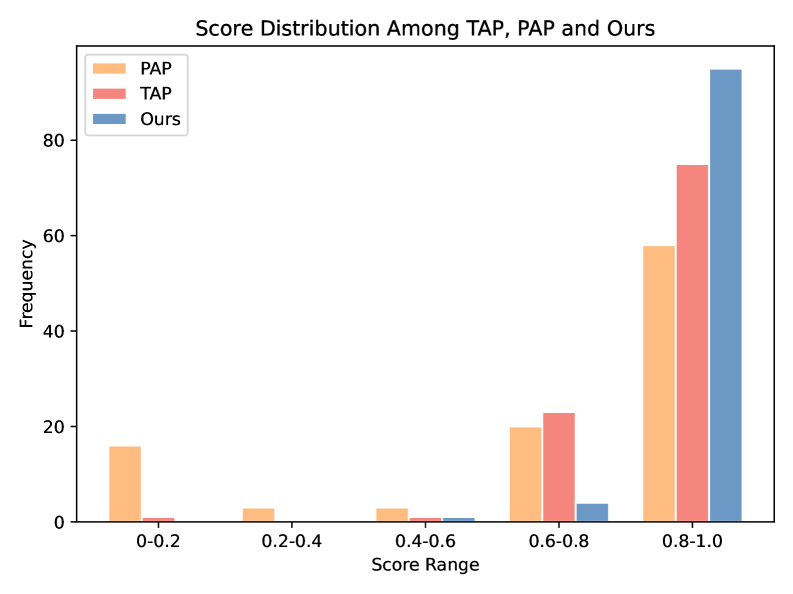
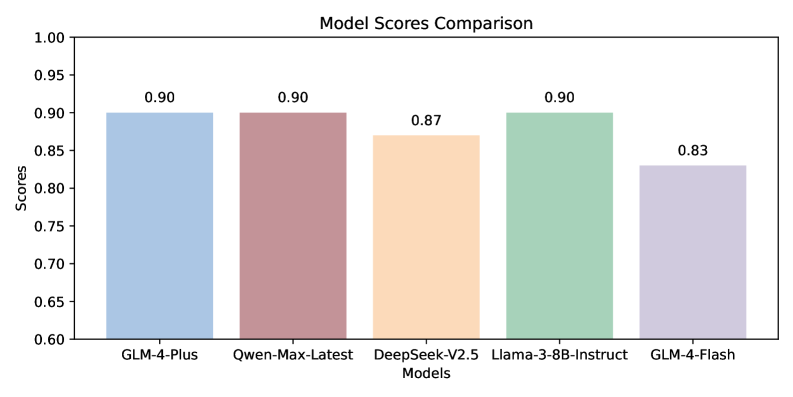
📊 实验亮点
该解决方案在2024年LLM和Agent安全竞赛的越狱攻击赛道中名列前茅,验证了所提框架的有效性。实验结果表明,该框架能够显著提高攻击的成功率和迁移性,有效绕过LLM的安全对齐机制。具体的性能数据和对比基线信息未知,但排名结果表明其优于其他参赛方案。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性。通过模拟各种攻击场景,可以发现LLM的潜在漏洞,并开发相应的防御措施。此外,该框架还可以用于构建更安全的LLM应用,防止恶意用户利用LLM生成有害内容。该研究对于保障LLM的健康发展具有重要意义。
📄 摘要(原文)
We present a novel black-box jailbreaking framework that integrates multiple LLM-as-Attacker strategies to deliver highly transferable and effective attacks. The framework is grounded in three key insights from prior jailbreaking research and practice: ensemble approaches outperform single methods in exposing aligned LLM vulnerabilities, malicious instructions vary in jailbreaking difficulty requiring tailored optimization, and disrupting semantic coherence of malicious prompts can manipulate their embeddings to boost success rates. Validated in the Competition for LLM and Agent Safety 2024, our solution achieved top rankings in the Jailbreaking Attack Track.