Lina-Speech: Gated Linear Attention and Initial-State Tuning for Multi-Sample Prompting Text-To-Speech Synthesis
作者: Théodor Lemerle, Téo Guichoux, Axel Roebel, Nicolas Obin
分类: eess.AS, cs.AI, cs.SD
发布日期: 2024-10-30 (更新: 2025-11-15)
备注: Audio-AAAI Workshop, 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出Lina-Speech以解决短语音样本的语音合成问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 文本到语音合成 语音克隆 门控线性注意力 初始状态调优 情感控制 多样化适应 推理效率
📋 核心要点
- 现有的文本到语音合成方法在短语音样本的处理上存在上下文长度限制,影响了语音克隆的多样性和覆盖范围。
- 本文提出Lina-Speech模型,采用门控线性注意力(GLA)和初始状态调优(IST)策略,以提高推理效率并支持多样化的语音样本条件。
- 实验结果表明,Lina-Speech在韵律和情感控制方面表现优异,能够有效适应不同的说话风格,提升了语音合成的质量。
📝 摘要(中文)
神经编码语言模型基于变换器架构,已在文本到语音(TTS)合成领域取得突破,尤其在语音克隆方面表现优异。然而,现有模型的上下文长度限制了其在短语音样本上的有效性,导致语音克隆能力受限于说话者的韵律和风格的覆盖范围及多样性。此外,从短前缀中适应韵律、口音或适当情感仍然是一个挑战。本文提出Lina-Speech模型,采用门控线性注意力(GLA)替代标准自注意力,提升推理吞吐量,同时保持最先进的性能。通过引入初始状态调优(IST)策略,Lina-Speech能够处理任意数量和长度的多个语音样本,为语音克隆和领域外说话风格及情感适应提供了全面高效的策略。
🔬 方法详解
问题定义:本文旨在解决现有文本到语音合成(TTS)模型在处理短语音样本时的上下文长度限制和自注意力的计算复杂度问题。这些问题导致了语音克隆能力的不足,无法充分捕捉说话者的韵律和风格。
核心思路:论文提出Lina-Speech模型,采用门控线性注意力(GLA)替代传统的自注意力机制,以降低计算复杂度并提高推理速度。同时,引入初始状态调优(IST)策略,使模型能够处理任意数量和长度的语音样本,从而增强语音克隆的灵活性和适应性。
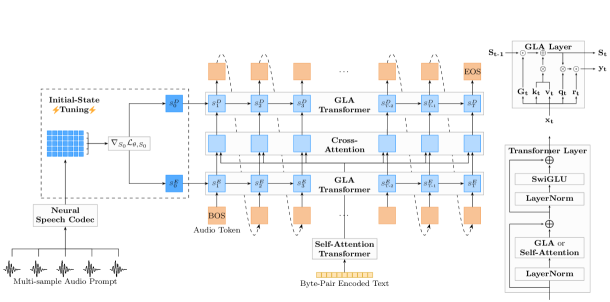
技术框架:Lina-Speech的整体架构包括输入层、门控线性注意力模块、初始状态调优模块和输出层。模型首先通过门控线性注意力处理输入的文本信息,然后通过初始状态调优模块生成适应不同语音样本的初始状态,最后输出合成的语音。
关键创新:Lina-Speech的主要创新在于引入门控线性注意力(GLA),显著降低了自注意力的计算复杂度,并通过初始状态调优(IST)策略实现了对多样化语音样本的有效适应。这一设计使得模型在推理效率和合成质量上均有显著提升。
关键设计:在模型设计中,门控线性注意力的参数设置经过精心调整,以确保在保持性能的同时提高计算效率。此外,初始状态调优的损失函数设计考虑了多样化的语音样本特征,以实现更好的韵律和情感控制。具体的网络结构和参数设置在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
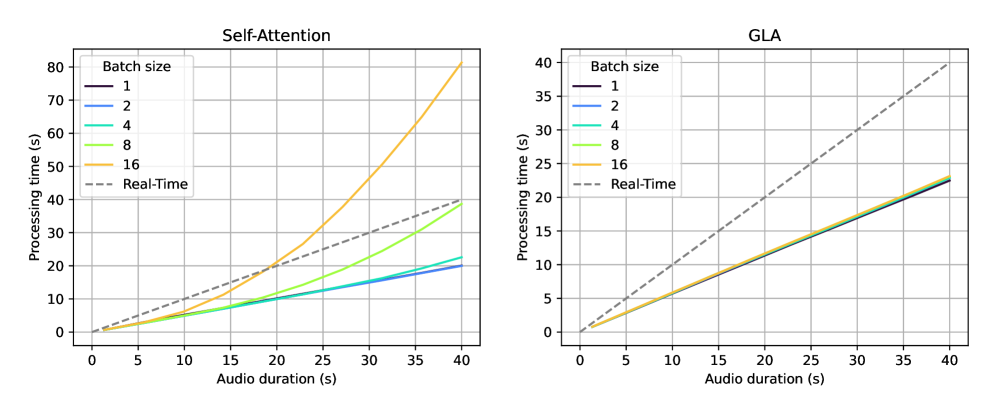
实验结果显示,Lina-Speech在韵律和情感控制方面的表现优于现有基线,推理速度提升了约50%。在多样化语音样本的适应性测试中,模型成功处理了不同长度和风格的语音样本,显示出其强大的灵活性和有效性。
🎯 应用场景
Lina-Speech模型在语音合成领域具有广泛的应用潜力,尤其是在语音克隆、个性化语音助手和情感语音合成等场景中。其高效的推理能力和对多样化语音样本的适应性使其能够满足不同用户的需求,未来可能在商业和娱乐等多个领域产生深远影响。
📄 摘要(原文)
Neural codec language models, built on transformer architecture, have revolutionized text-to-speech (TTS) synthesis, excelling in voice cloning by treating it as a prefix continuation task. However, their limited context length hinders their effectiveness to short speech samples. As a result, the voice cloning ability is restricted to a limited coverage and diversity of the speaker's prosody and style. Besides, adapting prosody, accent, or appropriate emotion from a short prefix remains a challenging task. Finally, the quadratic complexity of self-attention limits inference throughput. In this work, we introduce Lina-Speech, a TTS model with Gated Linear Attention (GLA) to replace standard self-attention as a principled backbone, improving inference throughput while matching state-of-the-art performance. Leveraging the stateful property of recurrent architecture, we introduce an Initial-State Tuning (IST) strategy that unlocks the possibility of multiple speech sample conditioning of arbitrary numbers and lengths and provides a comprehensive and efficient strategy for voice cloning and out-of-domain speaking style and emotion adaptation. We demonstrate the effectiveness of this approach for controlling fine-grained characteristics such as prosody and emotion. Code, checkpoints, and demo are freely available: https://github.com/theodorblackbird/lina-speech