Learning Marmoset Vocal Patterns with a Masked Autoencoder for Robust Call Segmentation, Classification, and Caller Identification
作者: Bin Wu, Shinnosuke Takamichi, Sakriani Sakti, Satoshi Nakamura
分类: cs.SD, cs.AI, eess.AS
发布日期: 2024-10-30 (更新: 2025-08-12)
备注: Accepted by ASRU 2025
💡 一句话要点
利用掩码自编码器预训练Transformer,提升狨猴叫声分割、分类和个体识别的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 狨猴叫声 自监督学习 掩码自编码器 Transformer 声音分割 声音分类 个体识别
📋 核心要点
- 狨猴叫声研究面临数据量小、噪声大、标注成本高等挑战,传统CNN难以捕捉长程依赖关系。
- 采用MAE预训练Transformer,利用大量无标注数据学习叫声表征,提升模型泛化能力和稳定性。
- 实验结果表明,MAE预训练的Transformer在叫声分割、分类和个体识别任务上优于CNN。
📝 摘要(中文)
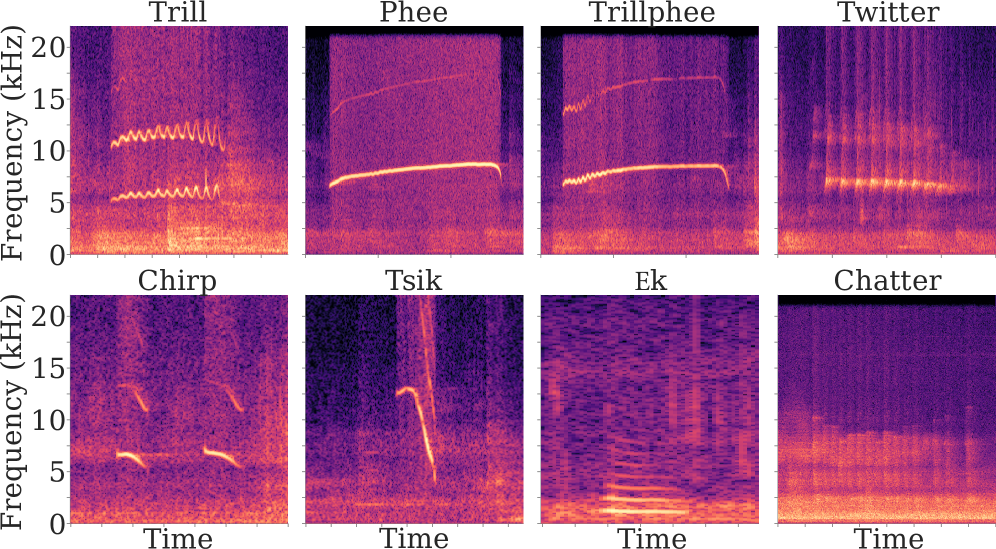
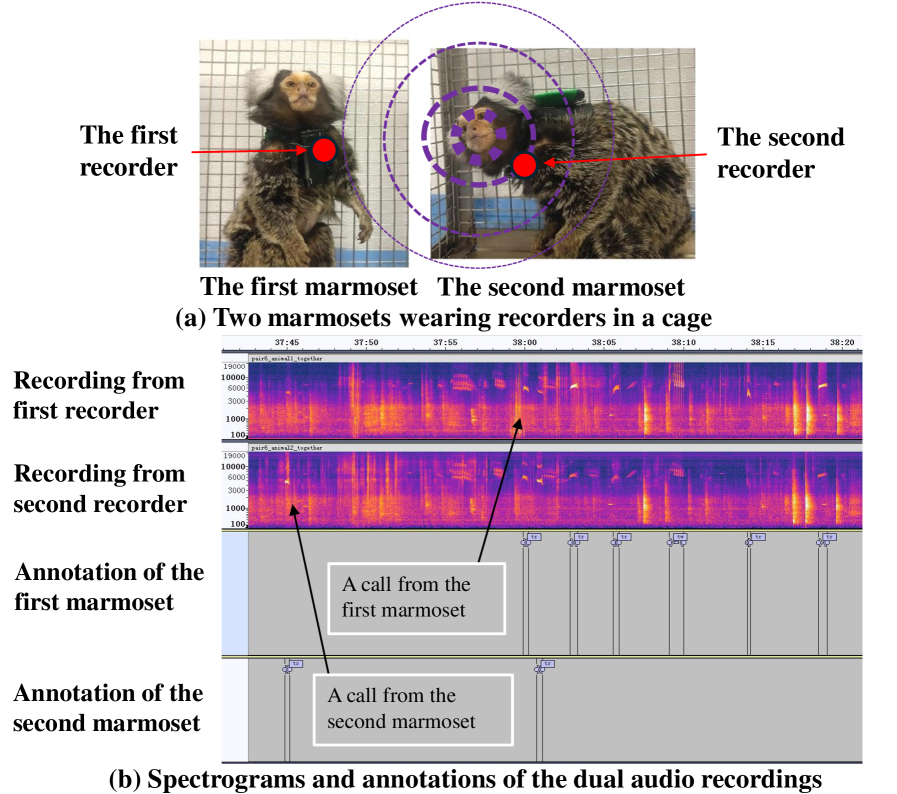
狨猴是一种高度依赖声音交流的灵长类动物,是研究社会交流行为的关键模型。与人类语音不同,狨猴的叫声结构性较差,变异性高,且通常在嘈杂、低资源的环境下记录。学习狨猴的交流方式需要联合进行叫声分割、分类和个体识别,这些都是具有挑战性的领域任务。以往的卷积神经网络(CNN)擅长处理局部模式,但在处理长程时间结构方面存在困难。本文应用Transformer模型,利用自注意力机制捕捉全局依赖关系。然而,Transformer在小型、噪声大的标注数据集上容易过拟合且不稳定。为了解决这个问题,本文使用掩码自编码器(MAE)预训练Transformer,这是一种自监督方法,可以从数百小时的未标注狨猴录音中重建被掩盖的片段。预训练提高了稳定性和泛化能力。结果表明,经过MAE预训练的Transformer优于CNN,证明了现代自监督架构能够有效地建模低资源的非人类声音交流。
🔬 方法详解
问题定义:论文旨在解决在低资源、高噪声环境下,对狨猴叫声进行准确的分割、分类和个体识别的问题。现有方法,特别是基于CNN的方法,虽然能够捕捉局部特征,但在处理狨猴叫声中存在的长程时间依赖关系方面表现不足。此外,直接在小规模标注数据集上训练Transformer容易导致过拟合。
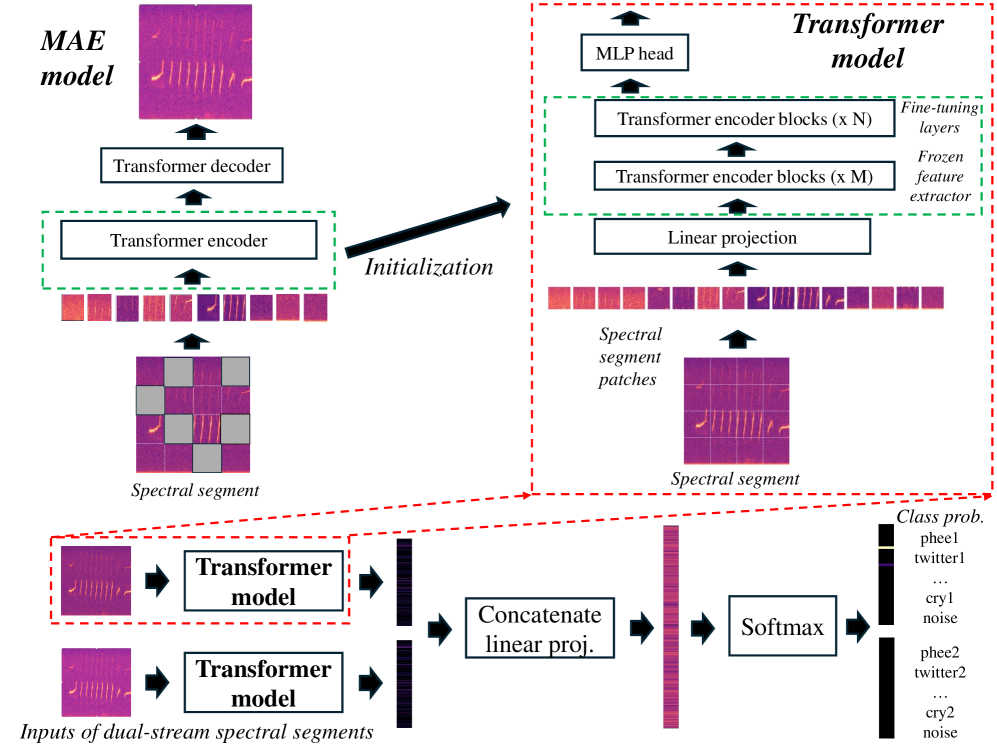
核心思路:论文的核心思路是利用自监督学习方法,即掩码自编码器(MAE),在大规模未标注的狨猴叫声数据上预训练Transformer模型。通过预训练,模型可以学习到更鲁棒、更通用的叫声表征,从而提高在下游任务中的性能。这种方法能够有效利用大量未标注数据,缓解低资源问题。
技术框架:整体框架包括两个主要阶段:预训练阶段和微调阶段。在预训练阶段,使用MAE对Transformer模型进行训练,使其能够从被掩盖的叫声片段中重建原始信号。在微调阶段,将预训练好的Transformer模型应用于叫声分割、分类和个体识别等下游任务,并在小规模标注数据集上进行微调。整个流程旨在利用无监督学习提取特征,再利用有监督学习完成特定任务。
关键创新:论文的关键创新在于将MAE与Transformer结合,用于处理低资源、高噪声的非人类声音交流数据。与传统的监督学习方法相比,这种自监督学习方法能够更有效地利用未标注数据,提高模型的泛化能力和鲁棒性。此外,论文还验证了Transformer在处理非人类声音交流数据方面的潜力。
关键设计:MAE的掩码比例是一个关键参数,论文可能探索了不同的掩码比例对预训练效果的影响。损失函数通常采用均方误差(MSE)或类似的重建损失,用于衡量重建信号与原始信号之间的差异。Transformer的网络结构可能采用了标准的Transformer编码器结构,并根据狨猴叫声的特点进行了调整。微调阶段,针对不同的下游任务,可能采用了不同的损失函数和评估指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过MAE预训练的Transformer模型在狨猴叫声分割、分类和个体识别任务上均优于传统的CNN模型。具体性能提升数据未知,但论文强调了预训练带来的稳定性和泛化能力提升,证明了自监督学习在低资源非人类声音交流建模中的有效性。
🎯 应用场景
该研究成果可应用于动物行为学研究,例如自动监测和分析动物的交流行为,了解动物的社会结构和行为模式。此外,该方法还可以推广到其他低资源、高噪声的语音识别任务,例如方言语音识别、环境声音识别等,具有广泛的应用前景。
📄 摘要(原文)
The marmoset, a highly vocal primate, is a key model for studying social-communicative behavior. Unlike human speech, marmoset vocalizations are less structured, highly variable, and recorded in noisy, low-resource conditions. Learning marmoset communication requires joint call segmentation, classification, and caller identification -- challenging domain tasks. Previous CNNs handle local patterns but struggle with long-range temporal structure. We applied Transformers using self-attention for global dependencies. However, Transformers show overfitting and instability on small, noisy annotated datasets. To address this, we pretrain Transformers with MAE -- a self-supervised method reconstructing masked segments from hundreds of hours of unannotated marmoset recordings. The pretraining improved stability and generalization. Results show MAE-pretrained Transformers outperform CNNs, demonstrating modern self-supervised architectures effectively model low-resource non-human vocal communication.