A little less conversation, a little more action, please: Investigating the physical common-sense of LLMs in a 3D embodied environment
作者: Matteo G. Mecattaf, Ben Slater, Marko Tešić, Jonathan Prunty, Konstantinos Voudouris, Lucy G. Cheke
分类: cs.AI
发布日期: 2024-10-30 (更新: 2025-01-03)
备注: 25 pages, 4 figures; v2: Added AFMR Acknowledgment
💡 一句话要点
在3D具身环境中评估LLM的物理常识推理能力,发现其与儿童存在差距
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 物理常识推理 具身智能 3D环境 Animal-AI
📋 核心要点
- 现有物理常识推理评估主要依赖静态基准,无法捕捉真实物理环境的复杂性和细微差别。
- 本文提出将LLM“具身化”,赋予其在3D环境中控制智能体的能力,从而进行更真实的物理常识推理评估。
- 实验表明,无需微调的多模态LLM可以完成具身物理推理任务,但性能仍低于人类儿童的表现。
📝 摘要(中文)
大型语言模型(LLM)作为通用工具,需要具备对日常物理环境的推理能力。这种能力不仅体现在问答中,也日益体现在作为智能体系统中的推理引擎,用于设计和控制动作序列。现有研究主要依赖静态基准测试,例如基于文本或图像的问题,但这些测试无法捕捉真实物理过程的复杂性。本文提出了一种新的方法:通过赋予LLM对3D环境中智能体的控制权来实现“具身化”。我们首次对LLM的物理常识推理能力进行了具身化和认知意义上的评估。该框架允许将LLM与基于深度强化学习的智能体以及人类和非人类动物进行直接比较。我们使用Animal-AI(AAI)环境,一个模拟的3D虚拟实验室,来研究LLM的物理常识推理能力。具体而言,我们使用AAI Testbed,这是一套复制非人类动物实验室研究的实验,以研究距离估计、追踪视野外物体和工具使用等物理推理能力。结果表明,无需微调的最先进多模态模型可以完成此类任务,并能与2019年Animal-AI奥林匹克竞赛的参赛者和人类儿童进行有意义的比较。实验结果表明,LLM在这些任务上的表现目前不如人类儿童。我们认为,这种方法允许使用直接来自认知科学的生态有效实验来研究物理推理,从而提高LLM的可预测性和可靠性。
🔬 方法详解
问题定义:现有LLM在物理常识推理方面存在不足,尤其是在需要与环境交互的动态场景中。静态基准测试无法充分评估LLM在真实世界中的物理推理能力,例如对物体运动轨迹的预测、对工具使用的理解等。现有方法缺乏生态有效性,难以反映真实世界的复杂性。
核心思路:本文的核心思路是将LLM“具身化”,即赋予LLM在3D虚拟环境中控制智能体的能力。通过让LLM与环境进行交互,可以更全面地评估其物理常识推理能力。这种方法借鉴了认知科学中对动物和人类进行物理推理研究的思路,具有更高的生态有效性。
技术框架:整体框架基于Animal-AI(AAI)环境,这是一个模拟的3D虚拟实验室。LLM通过控制AAI环境中的智能体来完成各种物理推理任务,例如距离估计、追踪视野外物体和工具使用。研究人员设计了一系列实验,这些实验复制了非人类动物的实验室研究。LLM接收环境的视觉输入,并输出智能体的动作指令。通过观察智能体的行为,可以评估LLM的物理常识推理能力。
关键创新:本文的关键创新在于将LLM与具身环境相结合,从而实现对物理常识推理的更真实、更全面的评估。与传统的静态基准测试相比,这种方法更具有生态有效性,能够更好地反映LLM在真实世界中的物理推理能力。此外,该框架允许将LLM与基于深度强化学习的智能体以及人类和非人类动物进行直接比较。
关键设计:实验中使用了AAI Testbed,这是一套预定义的实验任务,用于评估智能体的物理推理能力。研究人员使用了无需微调的最先进多模态模型,例如CLIP,作为LLM的视觉输入编码器。LLM的输出被转换为智能体的动作指令,例如移动、旋转和抓取。实验结果通过与2019年Animal-AI奥林匹克竞赛的参赛者和人类儿童的表现进行比较来评估。
🖼️ 关键图片


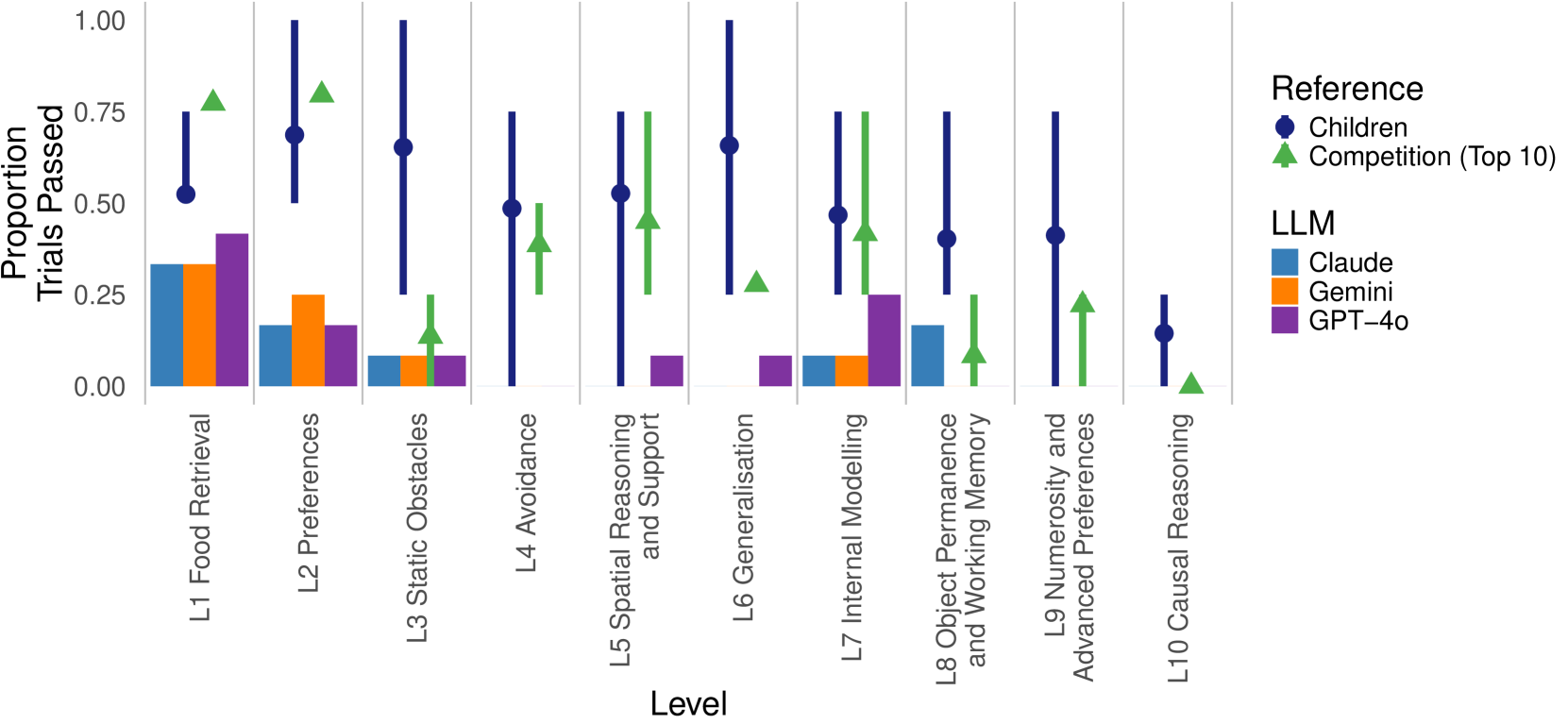
📊 实验亮点
实验结果表明,无需微调的最先进多模态模型可以在AAI环境中完成物理推理任务,例如距离估计、追踪视野外物体和工具使用。然而,LLM在这些任务上的表现目前不如人类儿童。这表明LLM在物理常识推理方面仍有很大的提升空间,需要进一步的研究和改进。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、自动驾驶等领域。通过提高LLM的物理常识推理能力,可以使智能体更好地理解和适应真实物理环境,从而实现更智能、更可靠的自主行为。未来,该方法还可以用于开发更具通用性和适应性的AI系统。
📄 摘要(原文)
As general-purpose tools, Large Language Models (LLMs) must often reason about everyday physical environments. In a question-and-answer capacity, understanding the interactions of physical objects may be necessary to give appropriate responses. Moreover, LLMs are increasingly used as reasoning engines in agentic systems, designing and controlling their action sequences. The vast majority of research has tackled this issue using static benchmarks, comprised of text or image-based questions about the physical world. However, these benchmarks do not capture the complexity and nuance of real-life physical processes. Here we advocate for a second, relatively unexplored, approach: 'embodying' the LLMs by granting them control of an agent within a 3D environment. We present the first embodied and cognitively meaningful evaluation of physical common-sense reasoning in LLMs. Our framework allows direct comparison of LLMs with other embodied agents, such as those based on Deep Reinforcement Learning, and human and non-human animals. We employ the Animal-AI (AAI) environment, a simulated 3D virtual laboratory, to study physical common-sense reasoning in LLMs. For this, we use the AAI Testbed, a suite of experiments that replicate laboratory studies with non-human animals, to study physical reasoning capabilities including distance estimation, tracking out-of-sight objects, and tool use. We demonstrate that state-of-the-art multi-modal models with no finetuning can complete this style of task, allowing meaningful comparison to the entrants of the 2019 Animal-AI Olympics competition and to human children. Our results show that LLMs are currently outperformed by human children on these tasks. We argue that this approach allows the study of physical reasoning using ecologically valid experiments drawn directly from cognitive science, improving the predictability and reliability of LLMs.