Reliable Decision Making via Calibration Oriented Retrieval Augmented Generation
作者: Chaeyun Jang, Deukhwan Cho, Seanie Lee, Hyungi Lee, Juho Lee
分类: cs.IR, cs.AI
发布日期: 2024-10-28 (更新: 2025-10-15)
备注: Accepted by NeurIPS 2025
💡 一句话要点
提出CalibRAG,通过校准检索增强生成提升LLM决策可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 校准 大型语言模型 决策支持 可靠性 置信度 信息检索
📋 核心要点
- 现有检索增强生成(RAG)方法侧重于检索相关文档,但忽略了确保基于RAG的决策具有良好的校准性。
- CalibRAG旨在通过校准检索过程,使LLM在不确定的情况下减少错误信息的生成,从而提升决策的可靠性。
- 实验结果表明,CalibRAG在多个数据集上,相较于其他基线方法,显著提升了校准性能和准确性。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于支持各种决策任务,辅助人类做出明智的决策。然而,当LLMs自信地提供不正确的信息时,可能导致人类做出次优决策。为了防止LLMs在不确定的主题上生成不正确的信息,并提高生成内容的准确性,先前的工作提出了检索增强生成(RAG),通过参考外部文档来生成响应。然而,先前的RAG方法仅侧重于检索与输入查询最相关的文档,而没有专门旨在确保人类用户的决策得到良好的校准。为了解决这个局限性,我们提出了一种新颖的检索方法,称为校准检索增强生成(CalibRAG),它确保由RAG提供信息的决策得到良好的校准。然后,我们通过实验验证了CalibRAG在各种数据集上提高了校准性能以及准确性,与其他基线相比。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在决策任务中,由于过度自信地给出错误信息而导致次优决策的问题。现有的检索增强生成(RAG)方法虽然可以提高生成内容的准确性,但忽略了决策的校准性,即LLM的置信度与其准确性不匹配,导致用户对LLM的建议产生不合理的信任。
核心思路:论文的核心思路是通过校准检索过程,使得检索到的文档不仅与查询相关,而且能够反映LLM对相关信息的置信度。这样,LLM在不确定的情况下,会倾向于检索到更多不确定性的证据,从而降低其过度自信的风险,最终提升决策的可靠性。
技术框架:CalibRAG的整体框架仍然是检索增强生成(RAG)的框架,主要包含以下几个阶段:1)查询编码:将用户查询编码成向量表示;2)校准检索:基于编码后的查询向量,从外部知识库中检索相关文档,该步骤是CalibRAG的核心,通过校准机制选择文档;3)生成:将检索到的文档与原始查询一起输入到LLM中,生成最终的答案或决策建议。
关键创新:CalibRAG最重要的技术创新点在于其校准检索机制。与传统的RAG方法只关注检索相关文档不同,CalibRAG通过引入校准目标,使得检索过程能够反映LLM对相关信息的置信度。具体来说,CalibRAG会根据LLM的置信度调整检索策略,例如,在LLM置信度较低时,倾向于检索更多样化或不确定性的文档。
关键设计:具体的校准检索机制可能涉及以下技术细节:1)置信度估计:使用LLM的输出概率或其他指标来估计LLM对当前查询的置信度;2)检索策略调整:根据置信度调整检索策略,例如,使用不同的相似度度量、调整检索结果的多样性等;3)损失函数设计:设计损失函数来鼓励检索过程产生能够反映LLM置信度的文档,例如,可以使用对比学习或强化学习等方法。
🖼️ 关键图片
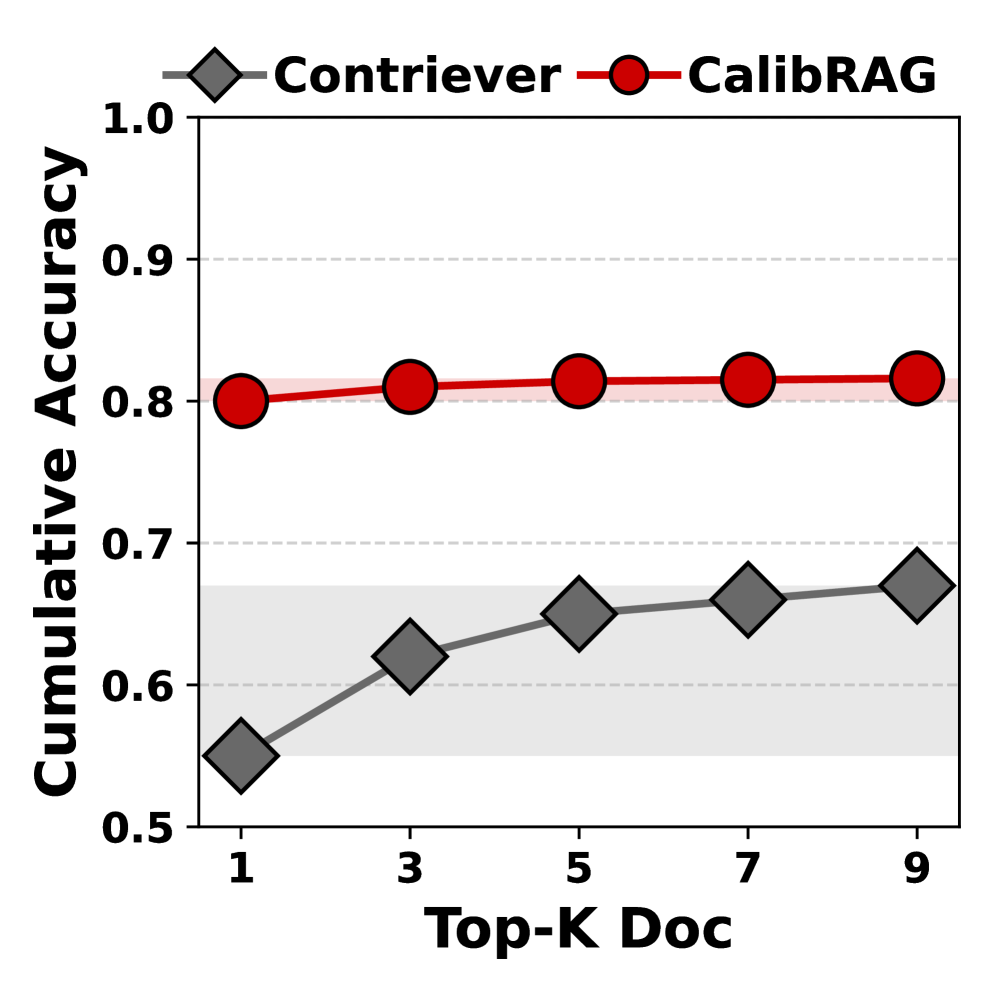
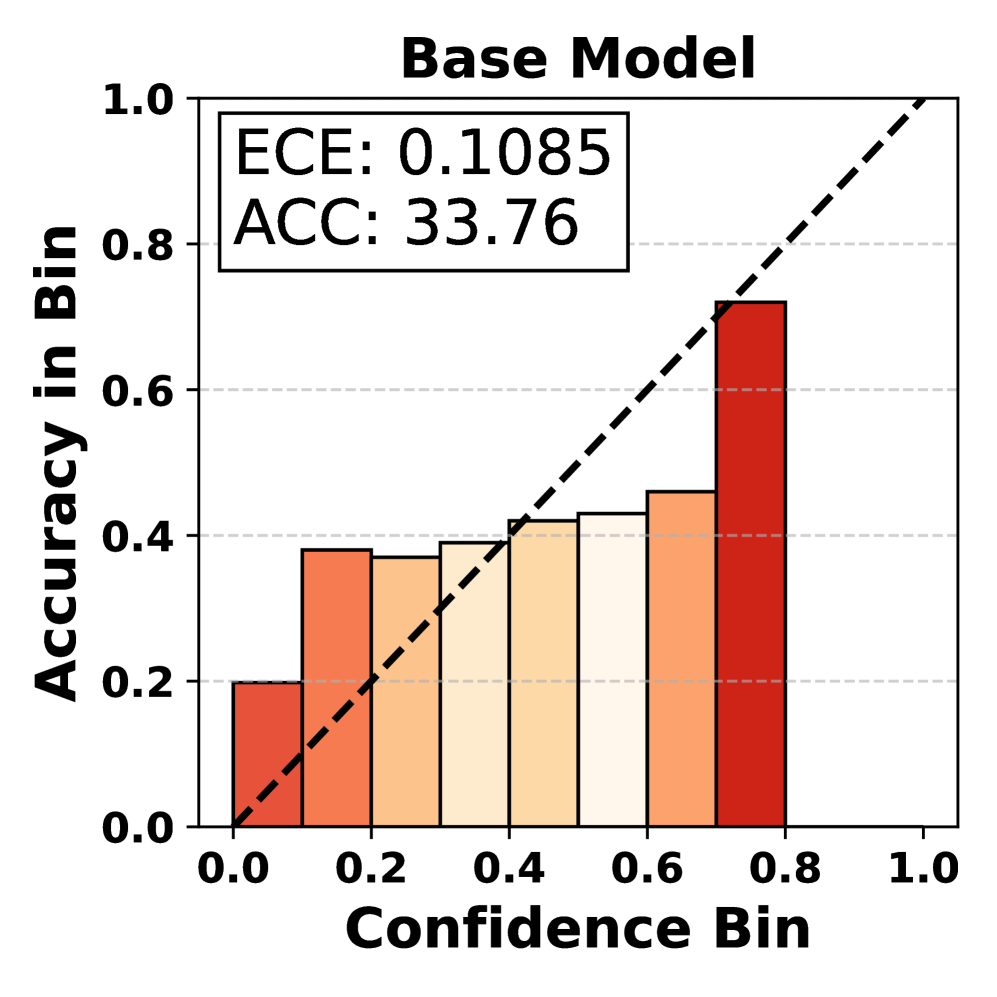
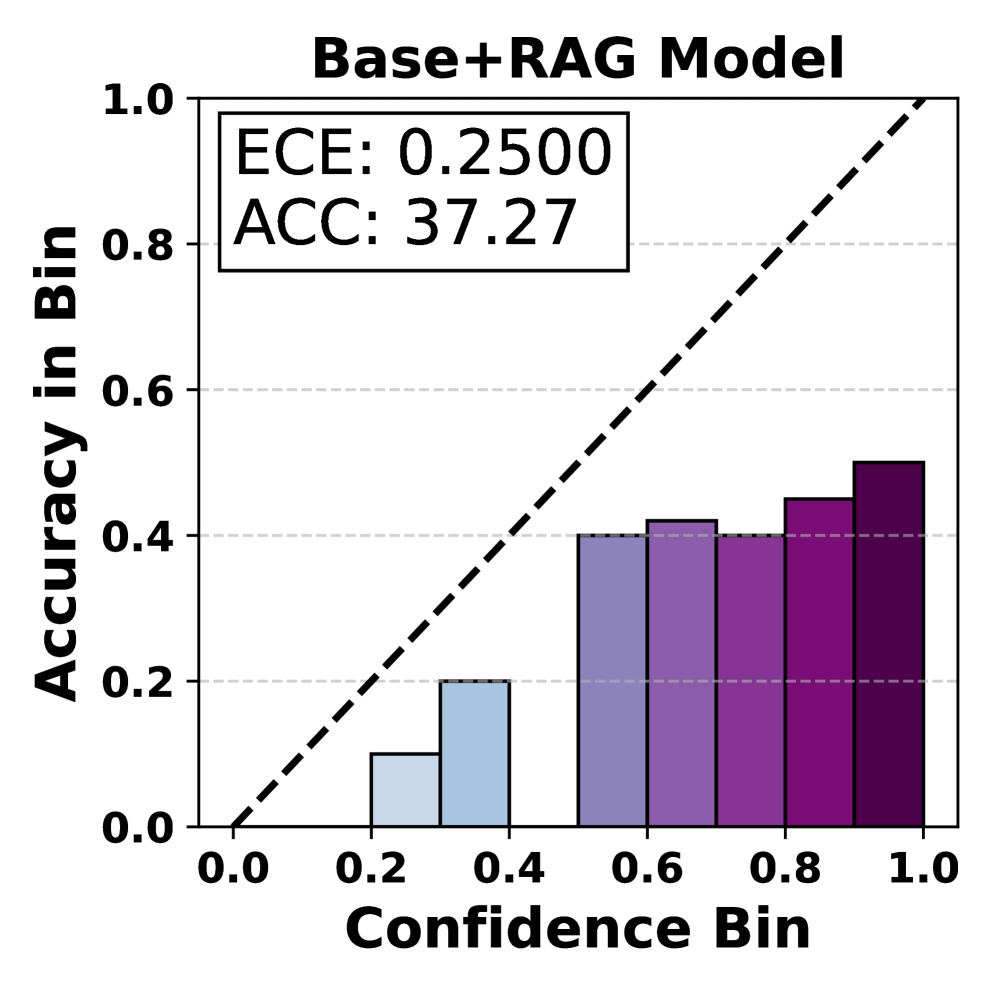
📊 实验亮点
实验结果表明,CalibRAG在多个数据集上显著提升了校准性能和准确性。具体来说,CalibRAG在校准误差(如Expected Calibration Error, ECE)指标上优于其他基线方法,表明CalibRAG能够更好地匹配LLM的置信度与其准确性。同时,CalibRAG在准确率等指标上也取得了提升,表明校准检索过程不仅提高了决策的可靠性,也提高了决策的准确性。
🎯 应用场景
CalibRAG可应用于各种需要LLM辅助决策的场景,例如医疗诊断、金融投资、法律咨询等。通过提高LLM决策的可靠性,CalibRAG可以帮助用户做出更明智的决策,降低因LLM错误信息而导致的风险。未来,CalibRAG可以进一步扩展到更复杂的决策场景,并与其他技术(如可解释性AI)相结合,以提高LLM决策的透明度和可信度。
📄 摘要(原文)
Recently, Large Language Models (LLMs) have been increasingly used to support various decision-making tasks, assisting humans in making informed decisions. However, when LLMs confidently provide incorrect information, it can lead humans to make suboptimal decisions. To prevent LLMs from generating incorrect information on topics they are unsure of and to improve the accuracy of generated content, prior works have proposed Retrieval Augmented Generation (RAG), where external documents are referenced to generate responses. However, previous RAG methods focus only on retrieving documents most relevant to the input query, without specifically aiming to ensure that the human user's decisions are well-calibrated. To address this limitation, we propose a novel retrieval method called Calibrated Retrieval-Augmented Generation (CalibRAG), which ensures that decisions informed by RAG are well-calibrated. Then we empirically validate that CalibRAG improves calibration performance as well as accuracy, compared to other baselines across various datasets.