Knowledge Distillation for Real-Time Classification of Early Media in Voice Communications
作者: Kemal Altwlkany, Hadžem Hadžić, Amar Kurić, Emanuel Lacic
分类: cs.SD, cs.AI, cs.MM, eess.AS
发布日期: 2024-10-28
DOI: 10.1109/MASCOTS64422.2024.10786538
💡 一句话要点
提出基于梯度提升树和知识蒸馏的早期媒体实时分类方法,提升语音通信效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 早期媒体分类 知识蒸馏 梯度提升树 实时语音通信 音频标记
📋 核心要点
- 现有音频标记模型在早期媒体实时分类中存在局限性,尤其是在资源受限的环境下。
- 提出一种基于梯度提升树的知识蒸馏方法,旨在降低模型复杂度,提升推理速度。
- 实验结果表明,该方法在保证准确率的同时,显著提升了运行时性能,并在实际场景中验证了其有效性。
📝 摘要(中文)
本文研究了语音呼叫初始化阶段中早期媒体的实时分类这一工业场景。我们探索了最先进的音频标记模型的应用,并强调了其在早期媒体分类中的一些局限性。虽然现有方法大多利用卷积神经网络,但我们提出了一种基于梯度提升树的低资源需求的新方法。我们的方法不仅在运行时性能方面表现出显著的改进,而且还具有可比的准确性。我们表明,利用知识蒸馏和类聚合技术来训练更简单、更小的模型可以加速语音呼叫中早期媒体的分类。我们提供了关于专有和公开可用数据集的结果的详细分析,包括准确性和运行时性能。此外,我们还报告了在印度区域数据中心实现的性能改进的案例研究。
🔬 方法详解
问题定义:论文旨在解决语音通信中早期媒体的实时分类问题。现有方法,特别是基于卷积神经网络的方法,计算复杂度高,资源消耗大,难以满足实时性和低资源的需求。因此,需要一种更轻量级、更高效的分类方法。
核心思路:论文的核心思路是利用知识蒸馏技术,将复杂模型的知识迁移到更简单的梯度提升树模型上。通过类聚合,进一步简化模型,提升推理速度。梯度提升树本身具有训练速度快、易于部署的优点,结合知识蒸馏,可以在保证准确率的前提下,大幅降低模型复杂度。
技术框架:整体框架包括以下几个阶段:1) 使用复杂的音频标记模型(如基于CNN的模型)作为教师模型;2) 利用教师模型对早期媒体数据进行预测,生成软标签;3) 使用软标签和原始标签训练梯度提升树模型(学生模型);4) 应用类聚合技术进一步简化学生模型;5) 在实际环境中部署和评估学生模型。
关键创新:该论文的关键创新在于将知识蒸馏和类聚合技术应用于早期媒体分类,并采用梯度提升树作为学生模型。与直接使用复杂的深度学习模型相比,该方法显著降低了计算复杂度,提升了推理速度,更适合资源受限的实时应用场景。
关键设计:论文中使用了XGBoost作为梯度提升树的实现。类聚合的具体方法未知,但其目的是将相似的类别合并,减少模型的输出维度,从而降低模型复杂度。损失函数可能包括交叉熵损失(用于知识蒸馏)和原始标签的损失。具体的参数设置和网络结构细节在论文中可能没有详细描述,需要参考相关文献。
🖼️ 关键图片
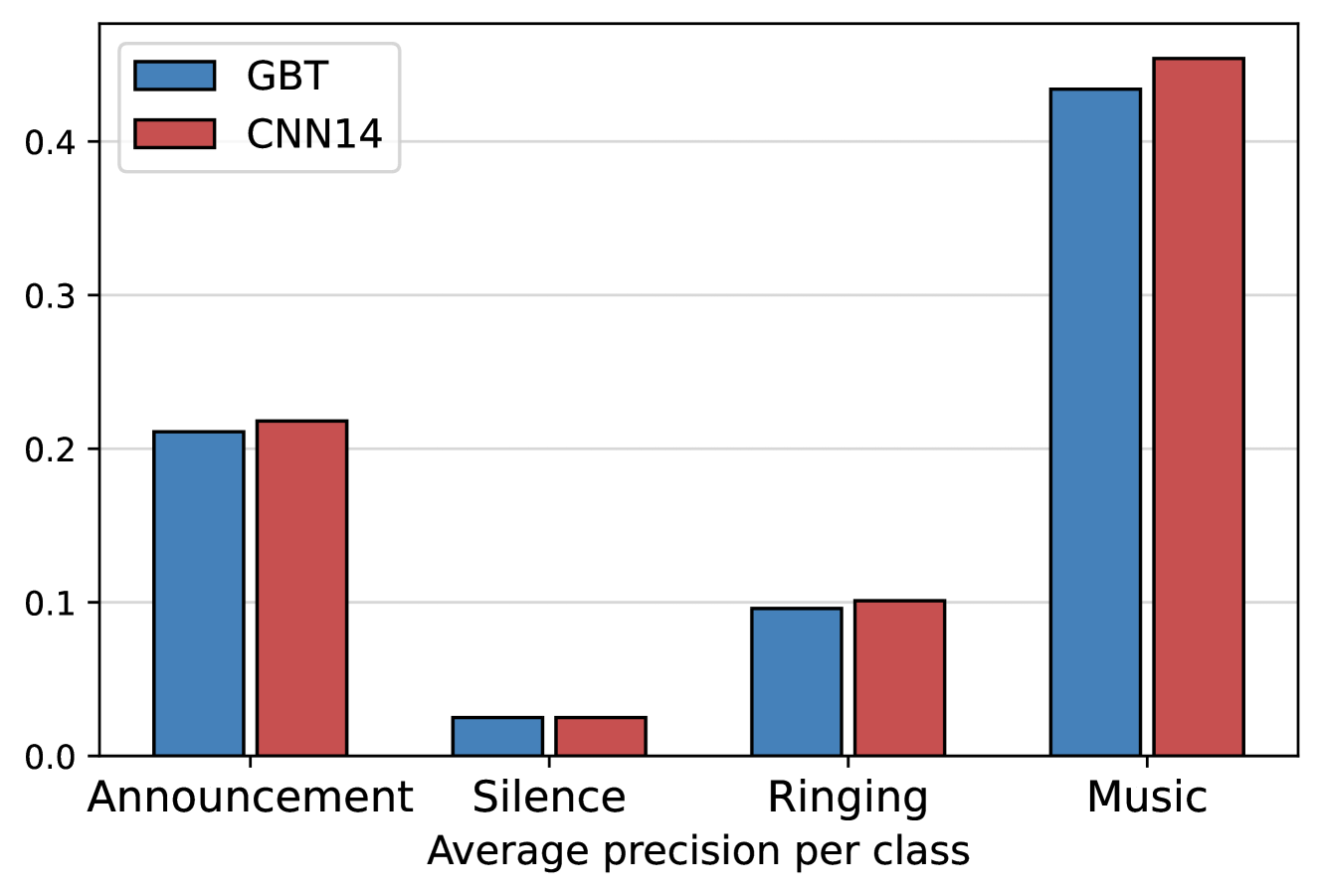
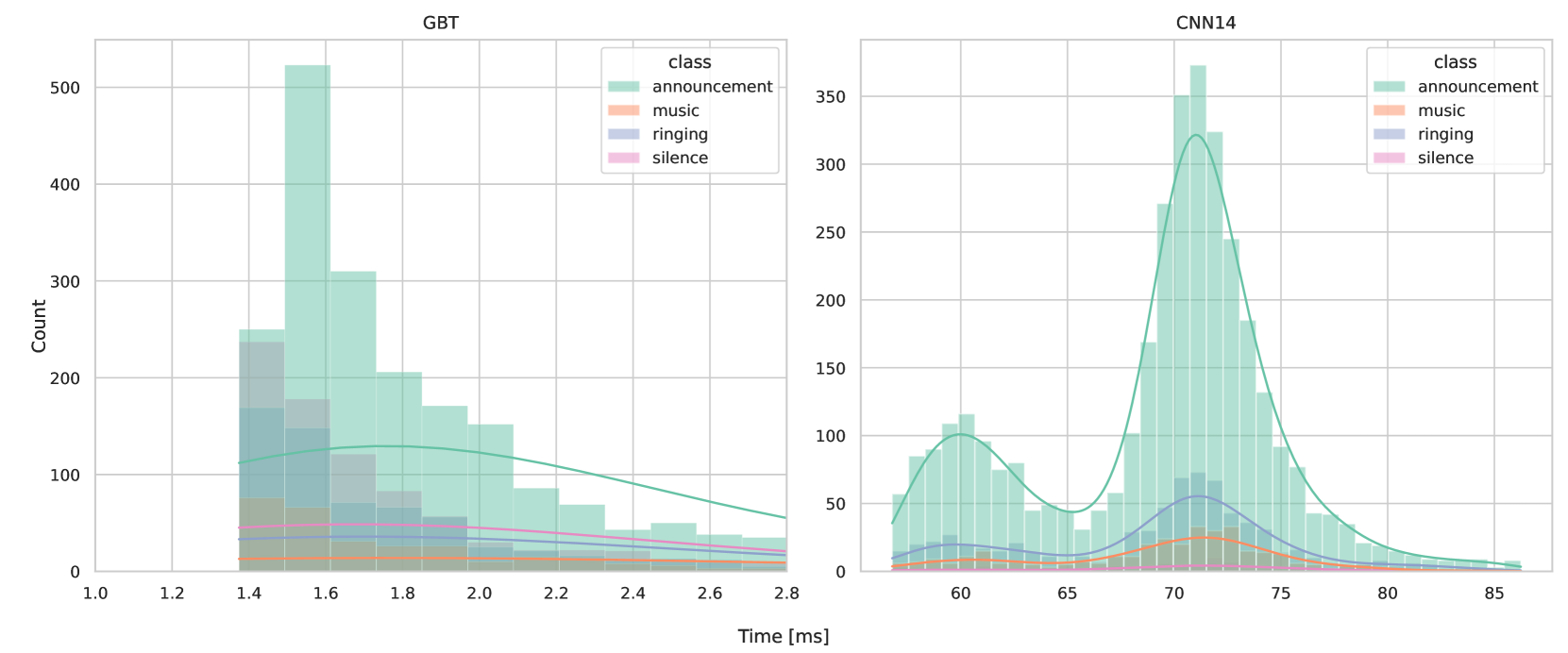
📊 实验亮点
论文在专有数据集和公开数据集上进行了实验,结果表明,基于梯度提升树和知识蒸馏的方法在保证准确率的前提下,显著提升了运行时性能。案例研究表明,在印度区域数据中心,该方法实现了显著的性能改进,具体数据未知,但证明了其在实际工业环境中的有效性。
🎯 应用场景
该研究成果可应用于语音通信服务提供商,用于实时识别呼叫类型(如语音、传真、数据),从而优化资源分配、改善用户体验、增强安全性。此外,该方法还可扩展到其他需要低延迟、低资源消耗的音频分类场景,例如智能家居、物联网设备等。
📄 摘要(原文)
This paper investigates the industrial setting of real-time classification of early media exchanged during the initialization phase of voice calls. We explore the application of state-of-the-art audio tagging models and highlight some limitations when applied to the classification of early media. While most existing approaches leverage convolutional neural networks, we propose a novel approach for low-resource requirements based on gradient-boosted trees. Our approach not only demonstrates a substantial improvement in runtime performance, but also exhibits a comparable accuracy. We show that leveraging knowledge distillation and class aggregation techniques to train a simpler and smaller model accelerates the classification of early media in voice calls. We provide a detailed analysis of the results on a proprietary and publicly available dataset, regarding accuracy and runtime performance. We additionally report a case study of the achieved performance improvements at a regional data center in India.