Exploring reinforcement learning for incident response in autonomous military vehicles
作者: Henrik Madsen, Gudmund Grov, Federico Mancini, Magnus Baksaas, Åvald Åslaugson Sommervoll
分类: cs.CR, cs.AI, cs.LG, cs.RO
发布日期: 2024-10-28
备注: DIGILIENCE 2024
💡 一句话要点
提出基于强化学习的自主网络防御方法,用于无人军用车辆的事件响应。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 自主网络防御 无人军用车辆 事件响应 网络安全
📋 核心要点
- 无人军用车辆面临严峻的网络安全挑战,需要自主防御能力以应对复杂多变的网络攻击。
- 利用强化学习训练智能体,使其能够在模拟环境中学习网络攻击响应策略,并迁移到真实车辆。
- 通过仿真和实车实验验证了该方法的可行性,为无人军用车辆的自主网络防御提供了一种新思路。
📝 摘要(中文)
本文探索了强化学习在自主军用车辆事件响应中的应用。随着无人车辆在军事行动中扮演越来越重要的角色,其安全风险也日益突出。本文旨在研究如何利用强化学习训练智能体,使其能够自主响应针对无人车辆的网络攻击。研究人员首先开发了一个简单的仿真环境用于快速原型设计和初步评估。随后,将智能体应用到更真实的仿真环境中,并最终部署到实际的无人地面车辆上。研究的关键贡献在于证明了强化学习是一种可行的训练方法,即使在简单的仿真环境中训练,也能在真实的无人地面车辆上实现自主网络防御。
🔬 方法详解
问题定义:无人军用车辆在执行任务时面临各种网络攻击,现有的人工干预方式响应速度慢,难以应对复杂攻击。因此,需要一种能够自主进行网络防御的方法,以保障车辆的安全运行。现有方法的痛点在于无法快速适应新的攻击模式,且依赖人工经验。
核心思路:利用强化学习训练一个智能体,使其能够通过与环境的交互学习最优的防御策略。智能体通过观察车辆状态和网络环境,选择合适的防御动作,并根据动作带来的奖励或惩罚来调整策略。这种方法能够使智能体自主学习,适应不同的攻击场景。
技术框架:整体框架包括三个主要阶段:1) 简单仿真环境:用于快速原型设计和初步评估;2) 更真实的仿真环境:用于更全面的测试和优化;3) 实际无人地面车辆部署:用于验证方法在真实环境中的可行性。智能体通过与环境交互,学习最优策略。环境提供车辆状态、网络环境等信息,智能体输出防御动作,环境根据动作反馈奖励或惩罚。
关键创新:最重要的创新点在于将强化学习应用于无人军用车辆的自主网络防御。与传统的基于规则或专家系统的方法相比,强化学习能够使智能体自主学习,适应不同的攻击场景,并具有更强的鲁棒性。
关键设计:论文中使用了Q-learning算法作为强化学习方法。状态空间包括车辆状态(如速度、位置)和网络环境(如攻击类型、攻击强度)。动作空间包括各种防御动作(如防火墙配置、入侵检测)。奖励函数的设计至关重要,需要平衡防御成功和资源消耗。具体的参数设置和网络结构在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

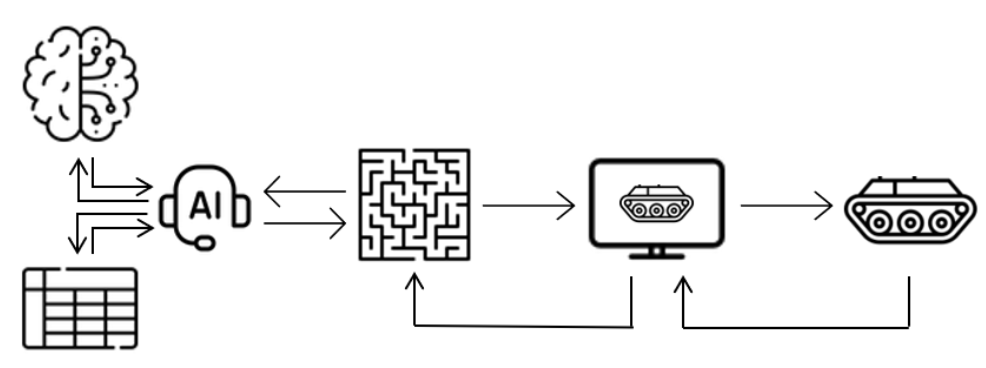
📊 实验亮点
该研究通过仿真和实车实验验证了强化学习在无人军用车辆自主网络防御中的可行性。虽然论文中没有提供具体的性能数据和对比基线,但成功地将智能体部署到实际的无人地面车辆上,并验证了其在真实环境中的有效性。这是一个重要的里程碑,为未来的研究奠定了基础。
🎯 应用场景
该研究成果可应用于各种无人系统,如无人机、无人船等,提高其在复杂环境下的安全性和可靠性。在军事领域,可以提升无人军用车辆的自主作战能力,降低对人工干预的依赖。在民用领域,可以应用于自动驾驶汽车、智能机器人等,增强其网络安全防护能力。
📄 摘要(原文)
Unmanned vehicles able to conduct advanced operations without human intervention are being developed at a fast pace for many purposes. Not surprisingly, they are also expected to significantly change how military operations can be conducted. To leverage the potential of this new technology in a physically and logically contested environment, security risks are to be assessed and managed accordingly. Research on this topic points to autonomous cyber defence as one of the capabilities that may be needed to accelerate the adoption of these vehicles for military purposes. Here, we pursue this line of investigation by exploring reinforcement learning to train an agent that can autonomously respond to cyber attacks on unmanned vehicles in the context of a military operation. We first developed a simple simulation environment to quickly prototype and test some proof-of-concept agents for an initial evaluation. This agent was then applied to a more realistic simulation environment and finally deployed on an actual unmanned ground vehicle for even more realism. A key contribution of our work is demonstrating that reinforcement learning is a viable approach to train an agent that can be used for autonomous cyber defence on a real unmanned ground vehicle, even when trained in a simple simulation environment.