Zero-Shot Dense Retrieval with Embeddings from Relevance Feedback
作者: Nour Jedidi, Yung-Sung Chuang, Leslie Shing, James Glass
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2024-10-28
💡 一句话要点
提出ReDE-RF,利用相关性反馈提升零样本稠密检索性能并降低延迟
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本检索 稠密检索 相关性反馈 大型语言模型 低资源学习
📋 核心要点
- 现有零样本稠密检索方法依赖LLM生成假设文档,对LLM的领域知识要求高,且生成大量tokens导致效率低。
- ReDE-RF将假设文档生成转化为相关性估计,利用LLM选择相关文档进行最近邻搜索,降低了对LLM领域知识的要求。
- 实验结果表明,ReDE-RF在低资源数据集上超越了现有零样本方法,并显著降低了查询延迟。
📝 摘要(中文)
在缺乏相关性监督的情况下,构建有效的稠密检索系统仍然具有挑战性。最近的研究尝试利用大型语言模型(LLM)生成假设文档,并以此找到最接近的真实文档来克服这一难题。然而,这种方法完全依赖于LLM具备与查询相关的领域特定知识,这在实践中可能并不现实。此外,生成假设文档效率低下,因为LLM需要为每个查询生成大量tokens。为了解决这些挑战,我们提出了Real Document Embeddings from Relevance Feedback(ReDE-RF)。受相关性反馈的启发,ReDE-RF将假设文档生成重新定义为相关性估计任务,使用LLM来选择哪些文档应该用于最近邻搜索。通过这种重新定义,LLM不再需要领域特定知识,而只需要判断相关性。此外,相关性估计只需要LLM输出单个token,从而提高了搜索延迟。实验表明,ReDE-RF在各种低资源检索数据集上始终优于最先进的零样本稠密检索方法,同时显著提高了每次查询的延迟。
🔬 方法详解
问题定义:论文旨在解决零样本稠密检索中,现有方法依赖LLM生成假设文档,导致对LLM领域知识要求高、计算效率低下的问题。现有方法的痛点在于,LLM需要具备领域特定知识才能生成有效的假设文档,并且生成大量tokens增加了计算负担。
核心思路:论文的核心思路是将假设文档生成任务重新定义为相关性估计任务。不再要求LLM生成完整的假设文档,而是利用LLM判断现有文档与查询的相关性,并选择最相关的文档进行后续的最近邻搜索。这样可以降低对LLM领域知识的要求,并减少LLM需要生成的tokens数量。
技术框架:ReDE-RF的技术框架主要包含以下几个阶段:1) 给定查询,从现有文档集中选择候选文档;2) 利用LLM对候选文档与查询的相关性进行评分,LLM只需要输出一个token表示相关性得分;3) 根据相关性得分选择Top-K个文档;4) 使用这些Top-K文档进行最近邻搜索,得到最终的检索结果。
关键创新:ReDE-RF最重要的技术创新点在于将假设文档生成任务转化为相关性估计任务。与现有方法相比,ReDE-RF不再依赖LLM生成完整的假设文档,而是利用LLM判断现有文档与查询的相关性。这种转变降低了对LLM领域知识的要求,并显著提高了计算效率。
关键设计:ReDE-RF的关键设计包括:1) 使用预训练的LLM作为相关性评分器,并对其进行微调以适应相关性估计任务;2) 设计合适的提示(prompt)来引导LLM进行相关性判断;3) 使用交叉编码器(cross-encoder)对查询和候选文档进行编码,并将编码结果输入到LLM中;4) 使用简单的分类损失函数来训练LLM,目标是预测文档与查询是否相关。
🖼️ 关键图片


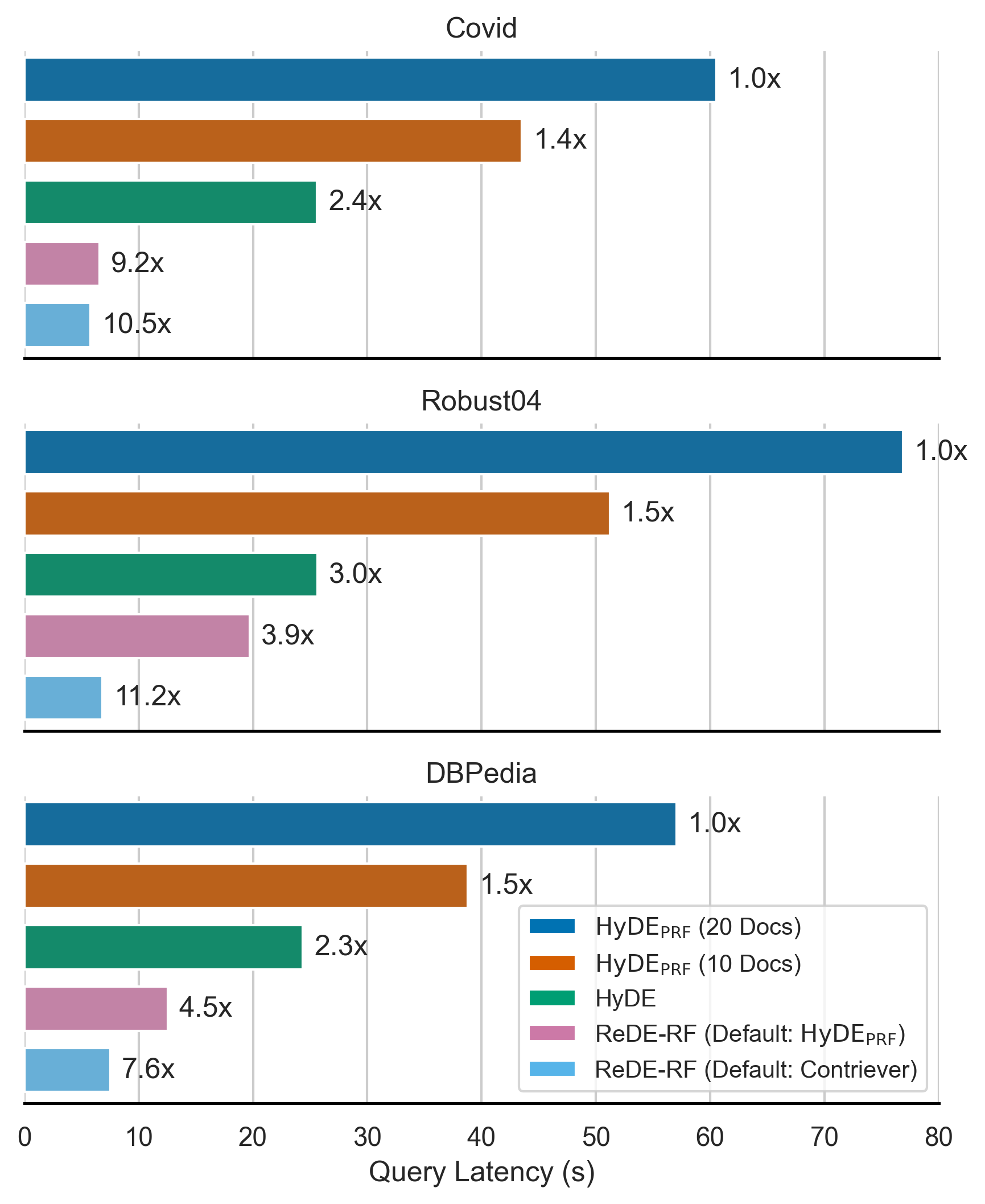
📊 实验亮点
实验结果表明,ReDE-RF在多个低资源检索数据集上显著优于现有的零样本稠密检索方法。例如,在某些数据集上,ReDE-RF的性能提升超过10%。此外,ReDE-RF还显著降低了每次查询的延迟,与现有方法相比,延迟降低了数倍。
🎯 应用场景
ReDE-RF可应用于各种低资源场景下的信息检索任务,例如特定领域的文档搜索、问答系统等。该方法降低了对领域知识的依赖,并提高了检索效率,具有广泛的应用前景。未来,该方法可以进一步扩展到多语言检索、跨模态检索等领域,并与其他检索技术相结合,以提升检索性能。
📄 摘要(原文)
Building effective dense retrieval systems remains difficult when relevance supervision is not available. Recent work has looked to overcome this challenge by using a Large Language Model (LLM) to generate hypothetical documents that can be used to find the closest real document. However, this approach relies solely on the LLM to have domain-specific knowledge relevant to the query, which may not be practical. Furthermore, generating hypothetical documents can be inefficient as it requires the LLM to generate a large number of tokens for each query. To address these challenges, we introduce Real Document Embeddings from Relevance Feedback (ReDE-RF). Inspired by relevance feedback, ReDE-RF proposes to re-frame hypothetical document generation as a relevance estimation task, using an LLM to select which documents should be used for nearest neighbor search. Through this re-framing, the LLM no longer needs domain-specific knowledge but only needs to judge what is relevant. Additionally, relevance estimation only requires the LLM to output a single token, thereby improving search latency. Our experiments show that ReDE-RF consistently surpasses state-of-the-art zero-shot dense retrieval methods across a wide range of low-resource retrieval datasets while also making significant improvements in latency per-query.