Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction
作者: Qintong Zhang, Bin Wang, Victor Shea-Jay Huang, Junyuan Zhang, Zhengren Wang, Hao Liang, Conghui He, Wentao Zhang
分类: cs.MM, cs.AI, cs.CL, cs.CV
发布日期: 2024-10-28 (更新: 2025-04-16)
💡 一句话要点
综述文档解析技术,探讨结构化信息提取的挑战与前景。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档解析 结构化信息提取 视觉-语言模型 布局检测 内容提取
📋 核心要点
- 现有文档解析方法在处理复杂布局和高密度文本时面临挑战,模块集成也存在困难。
- 本文综述了文档解析的关键方法,包括模块化流水线和基于视觉-语言模型的端到端模型。
- 强调了开发更大规模、更多样化数据集的重要性,并指出了未来研究方向。
📝 摘要(中文)
文档解析对于将非结构化和半结构化文档(如合同、学术论文和发票)转换为结构化的、机器可读的数据至关重要。文档解析从非结构化输入中提取可靠的结构化数据,为众多应用提供了极大的便利。尤其是在大型语言模型取得最新进展的情况下,文档解析在知识库构建和训练数据生成中都发挥着不可或缺的作用。本综述全面回顾了当前文档解析的现状,涵盖了关键方法,从模块化流水线系统到由大型视觉-语言模型驱动的端到端模型。详细研究了布局检测、内容提取(包括文本、表格和数学表达式)以及多模态数据集成等核心组件。此外,本文还讨论了模块化文档解析系统和视觉-语言模型在处理复杂布局、集成多个模块和识别高密度文本方面面临的挑战。它概述了未来的研究方向,并强调了开发更大、更多样化数据集的重要性。
🔬 方法详解
问题定义:文档解析旨在将非结构化或半结构化的文档转换为结构化数据,以便机器能够理解和处理。现有方法,特别是模块化的流水线系统,在处理复杂文档布局、高密度文本以及多模态数据集成方面存在不足。此外,如何有效利用大型视觉-语言模型进行端到端文档解析也是一个挑战。
核心思路:本文的核心思路是对现有文档解析技术进行全面的回顾和分析,从模块化的流水线系统到基于视觉-语言模型的端到端模型,梳理了各种方法的优缺点。通过分析现有方法的局限性,为未来的研究方向提供指导。
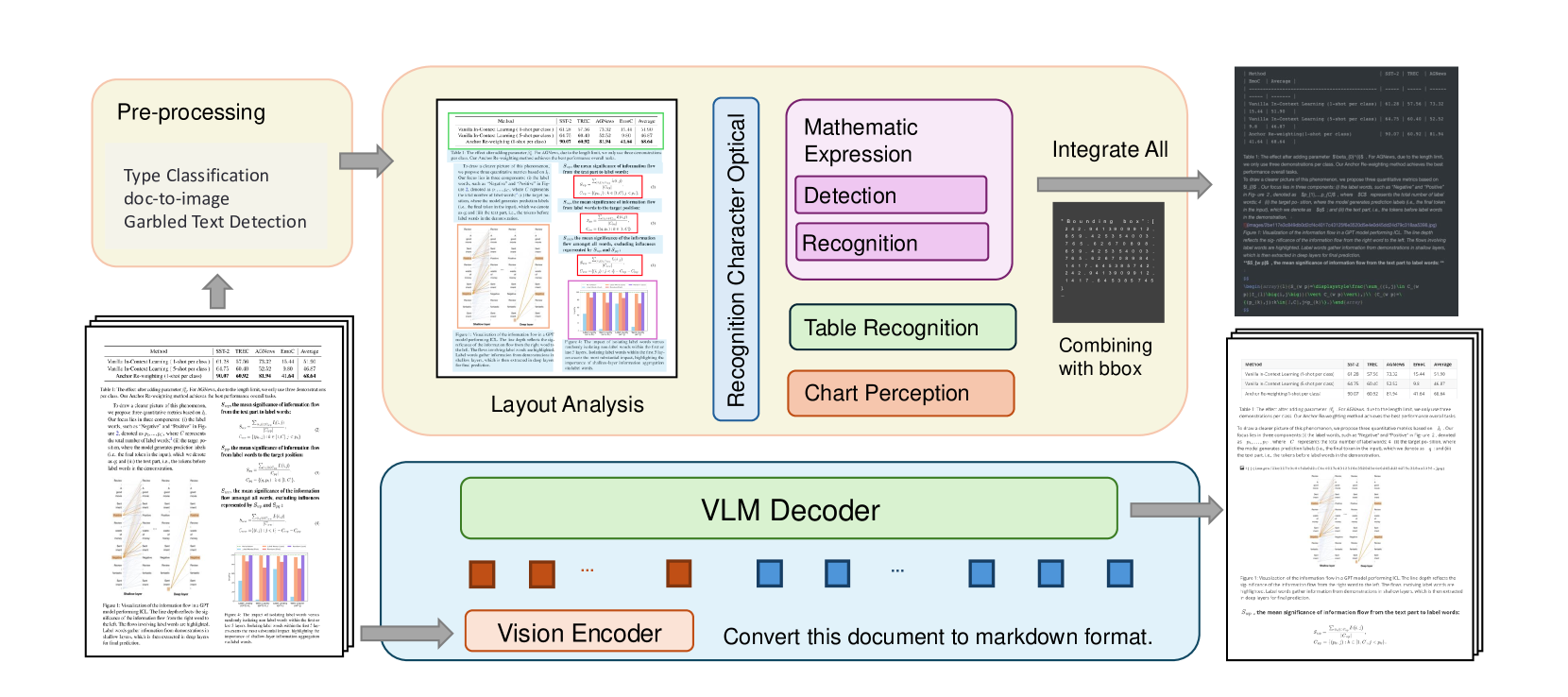
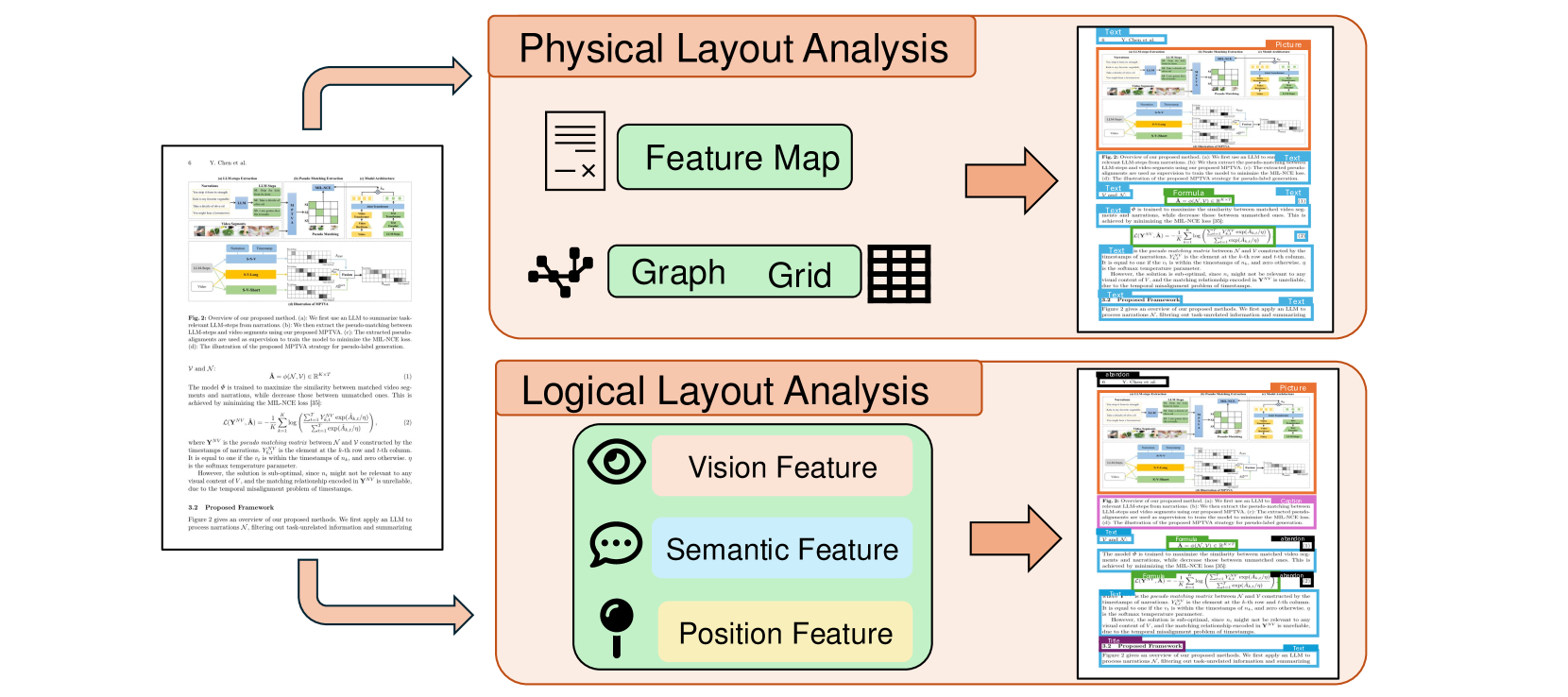
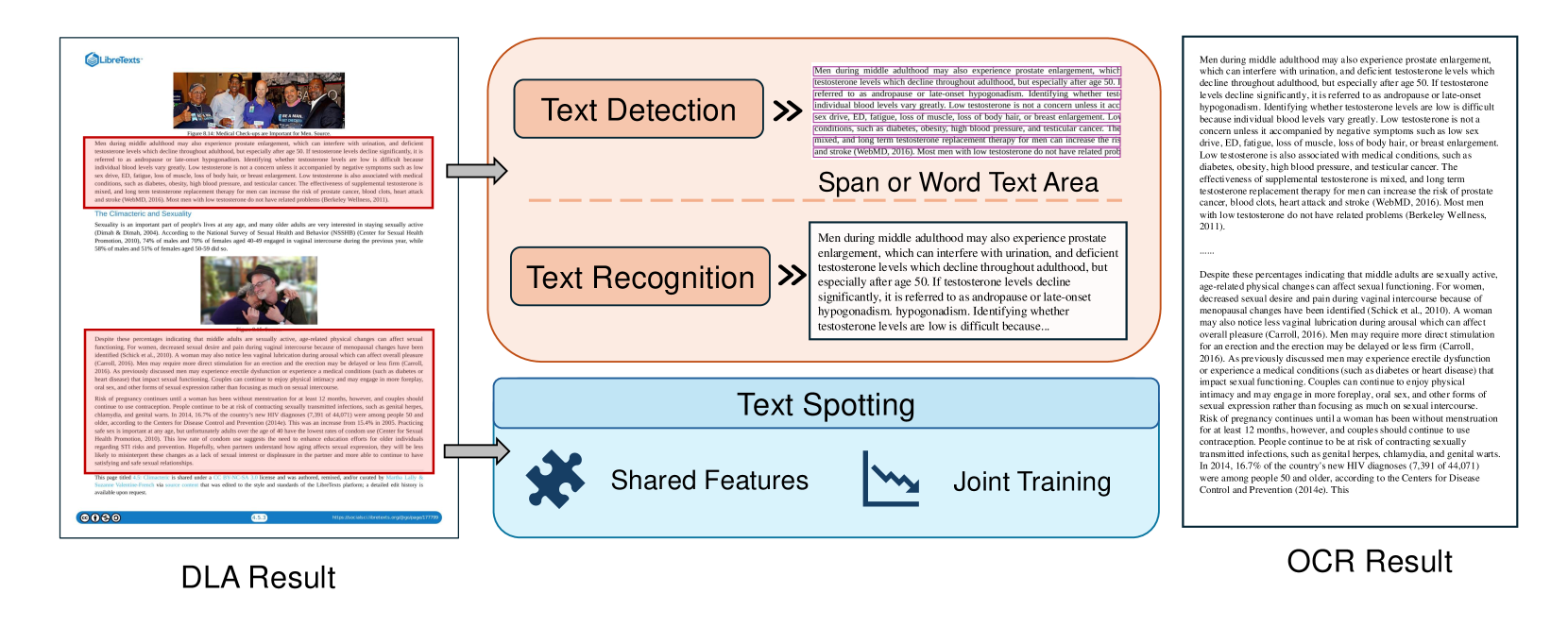
技术框架:文档解析的技术框架通常包括以下几个主要模块/阶段:1) 布局检测:识别文档中的文本块、表格、图像等元素的位置和结构;2) 内容提取:从文档中提取文本、表格数据、数学公式等内容;3) 多模态数据集成:将视觉信息(如布局)和文本信息进行融合,以提高解析的准确性;4) 结构化输出:将提取的信息转换为结构化的数据格式,如JSON或XML。
关键创新:本文的创新之处在于对文档解析领域进行了全面的综述,涵盖了传统方法和基于视觉-语言模型的新兴方法。通过对比分析不同方法的优缺点,为研究人员提供了有价值的参考。此外,本文还指出了当前文档解析面临的挑战和未来的研究方向。
关键设计:论文本身是一篇综述,因此没有具体的参数设置、损失函数或网络结构等技术细节。但是,论文中讨论了各种文档解析方法,例如,基于深度学习的布局检测方法通常使用卷积神经网络(CNN)或Transformer来提取图像特征,并使用目标检测算法(如Faster R-CNN或YOLO)来识别文本块的位置。基于视觉-语言模型的端到端方法通常使用预训练的视觉-语言模型(如LayoutLM或DocFormer)来进行文档解析。
🖼️ 关键图片
📊 实验亮点
本文是一篇综述性文章,没有具体的实验结果。其亮点在于全面回顾了文档解析领域的研究进展,并指出了当前研究的挑战和未来的研究方向。通过对不同方法的对比分析,为研究人员提供了有价值的参考。
🎯 应用场景
文档解析技术在多个领域具有广泛的应用前景,包括合同管理、财务报表分析、学术论文信息提取、发票处理等。通过将非结构化文档转换为结构化数据,可以实现自动化数据处理、知识库构建和智能决策支持,从而提高工作效率和降低成本。未来,随着技术的不断发展,文档解析将在更多领域发挥重要作用。
📄 摘要(原文)
Document parsing is essential for converting unstructured and semi-structured documents such as contracts, academic papers, and invoices into structured, machine-readable data. Document parsing reliable structured data from unstructured inputs, providing huge convenience for numerous applications. Especially with recent achievements in Large Language Models, document parsing plays an indispensable role in both knowledge base construction and training data generation. This survey presents a comprehensive review of the current state of document parsing, covering key methodologies, from modular pipeline systems to end-to-end models driven by large vision-language models. Core components such as layout detection, content extraction (including text, tables, and mathematical expressions), and multi-modal data integration are examined in detail. Additionally, this paper discusses the challenges faced by modular document parsing systems and vision-language models in handling complex layouts, integrating multiple modules, and recognizing high-density text. It outlines future research directions and emphasizes the importance of developing larger and more diverse datasets.