Towards Unifying Evaluation of Counterfactual Explanations: Leveraging Large Language Models for Human-Centric Assessments
作者: Marharyta Domnich, Julius Välja, Rasmus Moorits Veski, Giacomo Magnifico, Kadi Tulver, Eduard Barbu, Raul Vicente
分类: cs.AI, cs.CL
发布日期: 2024-10-28 (更新: 2025-04-22)
备注: This paper extends the AAAI-2025 version by including the Appendix
期刊: Proceedings of the AAAI Conference on Artificial Intelligence, 39(15), 16308-16316, 2025
DOI: 10.1609/aaai.v39i15.33791
💡 一句话要点
利用大语言模型进行以人为本的反事实解释评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 反事实解释 可解释人工智能 大语言模型 人类评估 模型评估
📋 核心要点
- 现有反事实解释的评估缺乏用户研究基础,指标分散且难以捕捉人类视角。
- 利用大语言模型预测人类对反事实解释的评价,实现更可比和可扩展的评估。
- 通过微调,LLM在预测人类评分方面取得了显著的准确率提升,最高达85%。
📝 摘要(中文)
随着机器学习模型的发展,保持透明性需要更以人为本的可解释人工智能技术。反事实解释源于人类推理,它识别获得给定输出所需的最小输入更改,因此对于支持决策至关重要。尽管它们很重要,但这些解释的评估通常缺乏用户研究的基础,并且仍然是分散的,现有的指标不能完全捕捉人类的观点。为了解决这个挑战,我们开发了一套包含30个反事实场景的多样化数据集,并从206名受访者那里收集了8个评估指标的评分。随后,我们对不同的大语言模型(LLM)进行了微调,以预测这些指标上的平均或个体人类判断。我们的方法使LLM在零样本评估中达到了高达63%的准确率,在所有指标上通过微调达到了85%(超过3类预测)。微调后的模型预测人类评分,在评估不同的反事实解释框架时,提供了更好的可比性和可扩展性。
🔬 方法详解
问题定义:论文旨在解决反事实解释评估中缺乏以人为本的视角的问题。现有的评估指标往往不能很好地反映人类对解释质量的判断,导致评估结果与实际应用效果脱节。此外,不同的反事实解释框架缺乏统一的评估标准,难以进行有效比较。
核心思路:论文的核心思路是利用大语言模型(LLM)学习人类对反事实解释的偏好,从而实现更贴近人类直觉的评估。通过收集大量人类对不同反事实解释的评分数据,并对LLM进行微调,使其能够预测人类的判断,从而为反事实解释的评估提供一个可扩展和可比较的框架。
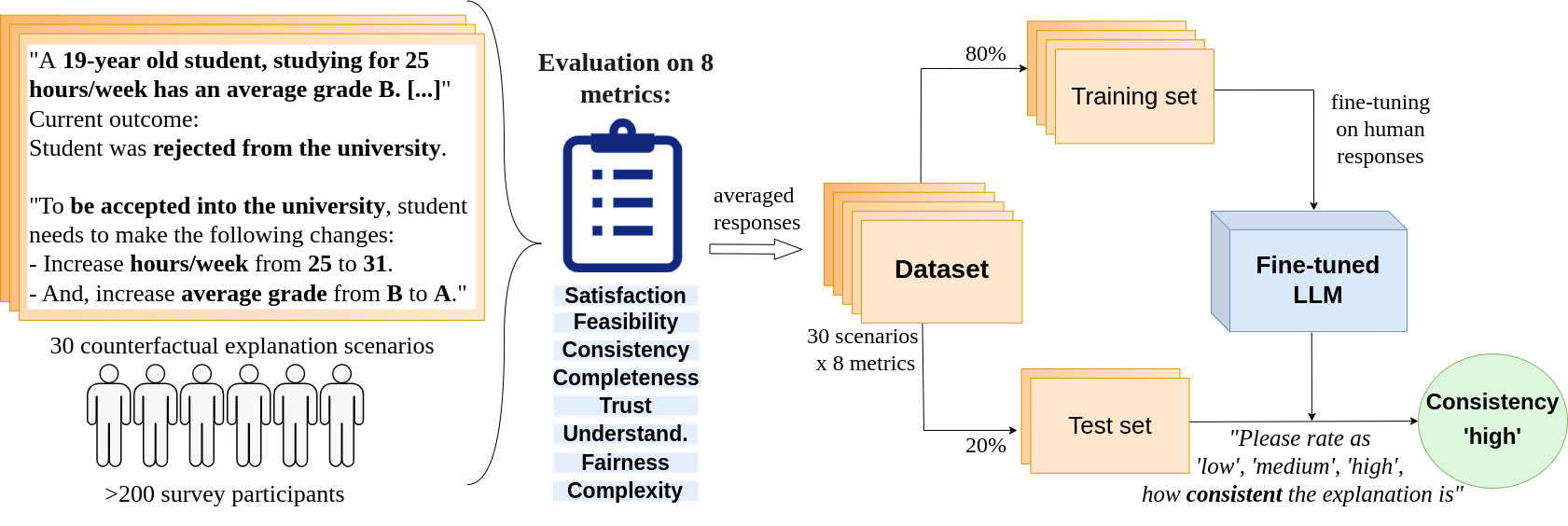
技术框架:整体框架包括以下几个主要阶段:1) 构建包含多样化反事实场景的数据集,并收集人类对这些场景下不同反事实解释的评分;2) 选择合适的大语言模型作为基础模型;3) 使用收集到的人类评分数据对LLM进行微调,使其能够预测人类对反事实解释的判断;4) 使用微调后的LLM对新的反事实解释进行评估,并与现有评估指标进行比较。
关键创新:论文的关键创新在于将大语言模型应用于反事实解释的评估,并利用人类评分数据进行微调,从而实现了以人为本的评估方法。这种方法能够更好地捕捉人类对解释质量的判断,并为不同反事实解释框架的比较提供了一个统一的标准。
关键设计:论文的关键设计包括:1) 构建包含30个反事实场景的多样化数据集,并收集206名受访者对8个评估指标的评分;2) 使用不同的大语言模型(具体模型未知)作为基础模型,并进行微调;3) 将预测任务转化为3分类问题,并使用交叉熵损失函数进行训练;4) 采用零样本评估和微调评估两种方式,评估LLM的性能。
🖼️ 关键图片
📊 实验亮点
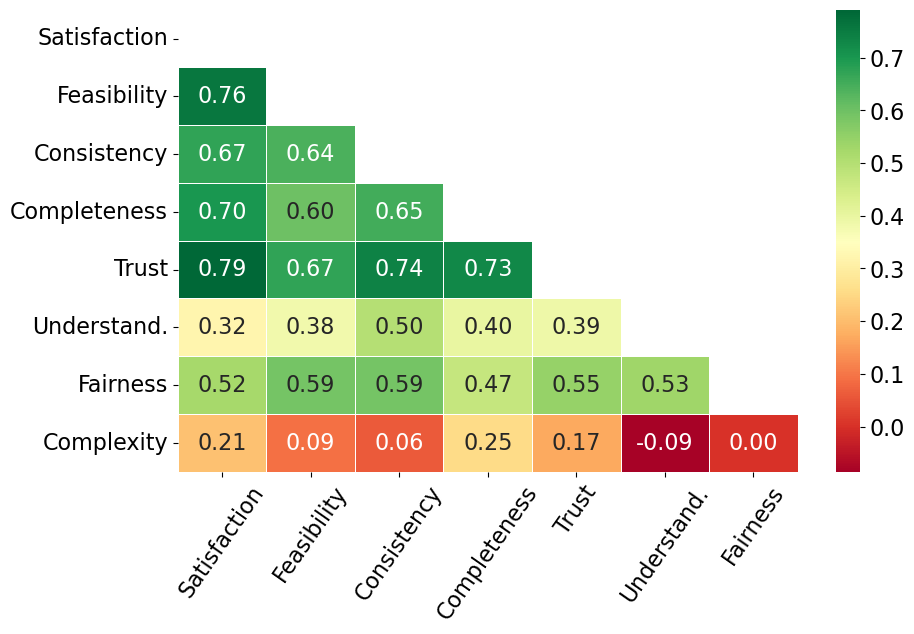
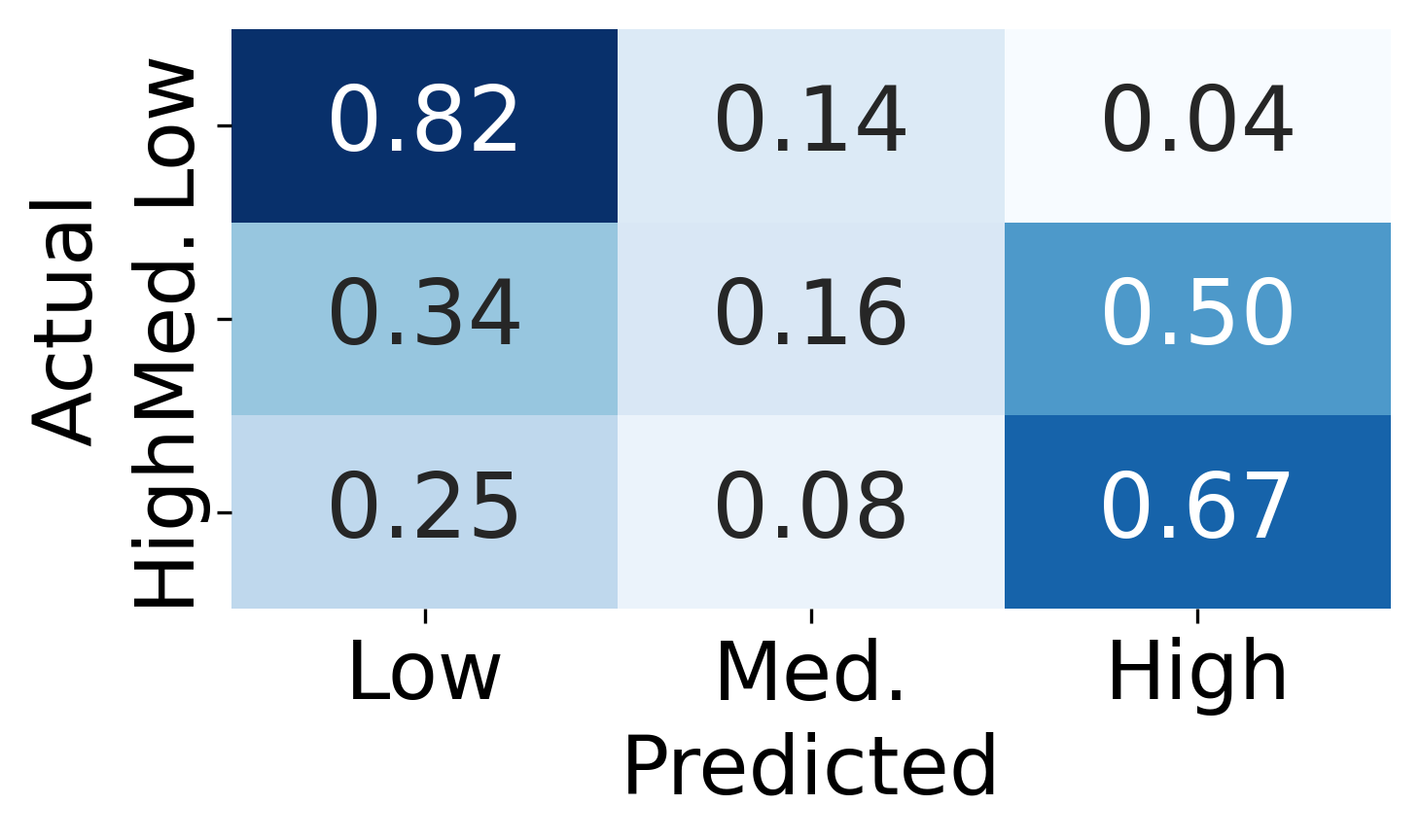
实验结果表明,经过微调的大语言模型在预测人类对反事实解释的评分方面取得了显著的成果。在零样本评估中,LLM的准确率高达63%,经过微调后,准确率提升至85%(3分类)。这些结果表明,利用大语言模型进行反事实解释评估具有很大的潜力,可以为可解释人工智能的发展提供新的思路。
🎯 应用场景
该研究成果可应用于各种需要可解释人工智能的领域,例如金融、医疗和法律。通过利用大语言模型进行反事实解释的评估,可以提高决策的透明度和可信度,并帮助用户更好地理解和信任机器学习模型。未来,该方法可以推广到其他类型的解释方法评估中,促进可解释人工智能的发展。
📄 摘要(原文)
As machine learning models evolve, maintaining transparency demands more human-centric explainable AI techniques. Counterfactual explanations, with roots in human reasoning, identify the minimal input changes needed to obtain a given output and, hence, are crucial for supporting decision-making. Despite their importance, the evaluation of these explanations often lacks grounding in user studies and remains fragmented, with existing metrics not fully capturing human perspectives. To address this challenge, we developed a diverse set of 30 counterfactual scenarios and collected ratings across 8 evaluation metrics from 206 respondents. Subsequently, we fine-tuned different Large Language Models (LLMs) to predict average or individual human judgment across these metrics. Our methodology allowed LLMs to achieve an accuracy of up to 63% in zero-shot evaluations and 85% (over a 3-classes prediction) with fine-tuning across all metrics. The fine-tuned models predicting human ratings offer better comparability and scalability in evaluating different counterfactual explanation frameworks.