Large Language Model-assisted Speech and Pointing Benefits Multiple 3D Object Selection in Virtual Reality
作者: Junlong Chen, Jens Grubert, Per Ola Kristensson
分类: cs.HC, cs.AI
发布日期: 2024-10-28
备注: under review
💡 一句话要点
提出AssistVR,利用大语言模型辅助VR中多目标3D物体选择
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 虚拟现实 多目标选择 大语言模型 语音交互 人机交互
📋 核心要点
- VR中选择遮挡物体,尤其多目标选择,是难题,传统方法如迷你地图效率低,用户体验欠佳。
- AssistVR结合语音和光线投射,利用大语言模型理解用户意图,辅助选择VR场景中多个目标物体。
- 实验表明,AssistVR在多目标选择中优于迷你地图基线,即使目标物体难以用语言描述,依然有效。
📝 摘要(中文)
在虚拟现实中,选择被遮挡的物体是一个具有挑战性的问题,特别是当涉及多个物体时。随着人工智能技术的进步,我们探索了利用大型语言模型,通过多模态语音和光线投射交互技术,辅助虚拟现实中的多目标选择任务的可能性。我们通过一项对比用户研究(n=24)验证了研究结果,参与者在具有不同场景复杂度的虚拟现实场景中选择目标物体。性能指标和用户体验指标与基于迷你地图的遮挡物体选择技术(作为基线)进行了比较。结果表明,所提出的技术AssistVR在存在多个目标物体时优于基线技术。与语音界面的普遍认知相反,即使目标物体难以用语言描述,AssistVR也能够优于基线。这项工作证明了由大型语言模型驱动的智能多模态交互系统的可行性和交互潜力。基于结果,我们讨论了沉浸式环境中未来智能多模态交互系统设计的意义。
🔬 方法详解
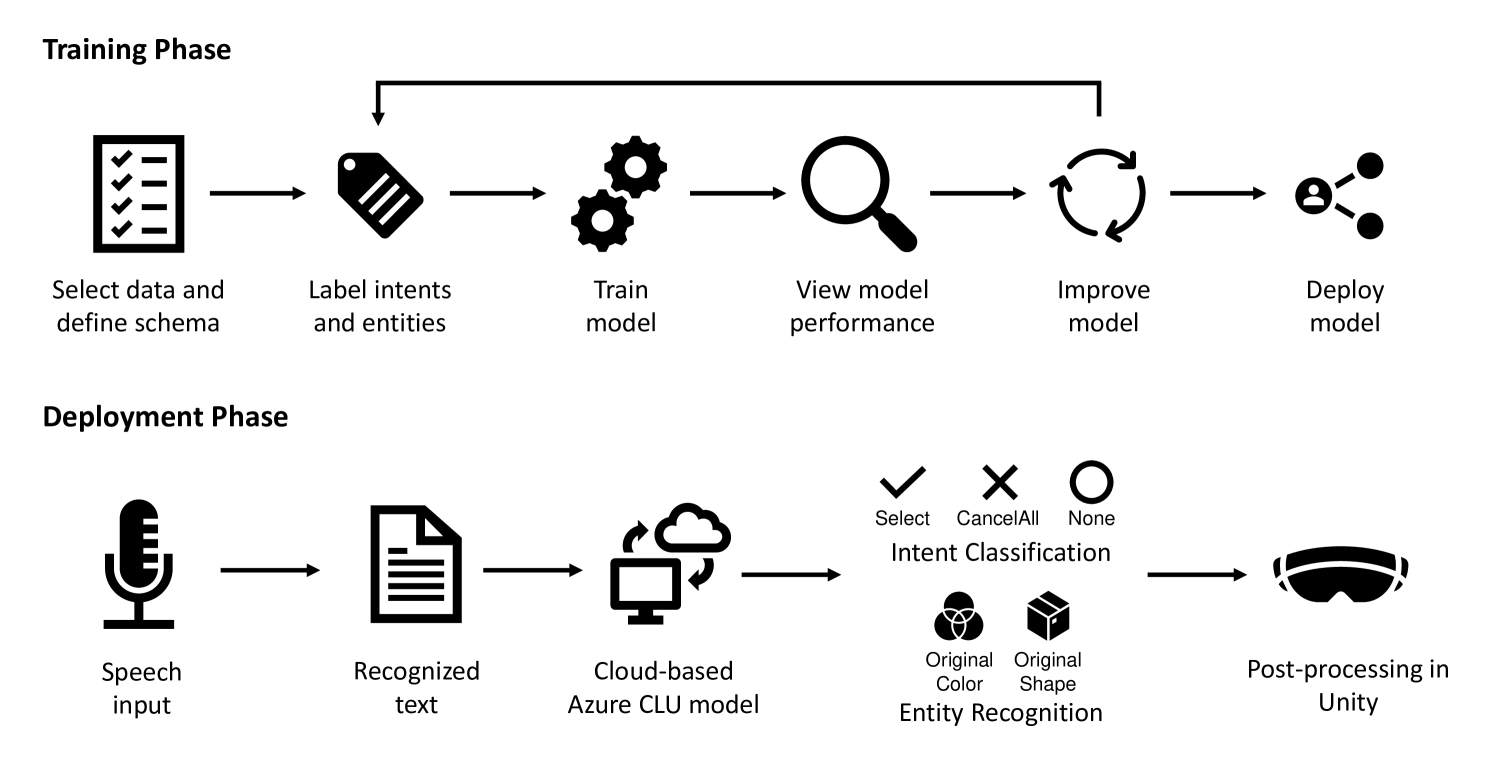
问题定义:论文旨在解决虚拟现实(VR)环境中,用户难以高效选择被遮挡的多个3D物体的问题。现有方法,例如基于迷你地图的选择方式,在复杂场景下效率较低,用户体验不佳。用户需要花费大量时间在迷你地图和主视角之间切换,难以快速定位和选择目标物体。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大自然语言理解能力,结合语音输入和光线投射技术,构建一个智能的多模态交互系统。用户可以通过语音描述目标物体,LLM理解用户意图后,结合光线投射技术,辅助用户快速准确地选择目标物体。这种方法旨在提高选择效率,改善用户体验。
技术框架:AssistVR系统的整体框架包含以下几个主要模块:1) 语音输入模块:负责接收用户的语音指令。2) 自然语言理解模块:使用大型语言模型(LLM)解析语音指令,提取目标物体的描述信息。3) 目标物体定位模块:根据LLM的输出,结合场景信息,定位潜在的目标物体。4) 光线投射辅助选择模块:通过光线投射技术,将潜在的目标物体高亮显示,辅助用户进行选择。5) 用户反馈模块:接收用户的选择结果,并进行确认。
关键创新:该论文的关键创新在于将大型语言模型(LLM)应用于VR环境中的多目标选择任务。与传统的基于菜单或迷你地图的选择方法不同,AssistVR利用LLM的自然语言理解能力,允许用户通过语音描述目标物体,从而实现更自然、更高效的交互。此外,该系统结合了语音输入和光线投射技术,进一步提高了选择的准确性和效率。
关键设计:论文中没有详细描述LLM的具体选择和训练细节,这部分信息未知。光线投射的具体实现方式(例如,光线的颜色、粗细、高亮方式等)也未详细说明。用户研究中,场景的复杂度通过控制场景中物体的数量和遮挡程度来调整。性能指标包括选择时间、错误率等。用户体验指标通过问卷调查进行评估。
🖼️ 关键图片


📊 实验亮点
用户研究表明,在多目标选择任务中,AssistVR显著优于基于迷你地图的基线方法。即使目标物体难以用语言精确描述,AssistVR依然能够保持较高的选择效率和准确率。这表明,基于大语言模型的多模态交互方式在VR环境中具有巨大的潜力,能够有效解决传统交互方式的局限性。
🎯 应用场景
该研究成果可应用于各种VR/AR场景,例如:工业设计中复杂零部件的选择、建筑设计中特定构件的选取、游戏开发中多个道具的拾取等。通过语音交互和AI辅助,能够显著提升用户在沉浸式环境中的操作效率和体验,降低学习成本,拓展VR/AR技术的应用范围。
📄 摘要(原文)
Selection of occluded objects is a challenging problem in virtual reality, even more so if multiple objects are involved. With the advent of new artificial intelligence technologies, we explore the possibility of leveraging large language models to assist multi-object selection tasks in virtual reality via a multimodal speech and raycast interaction technique. We validate the findings in a comparative user study (n=24), where participants selected target objects in a virtual reality scene with different levels of scene perplexity. The performance metrics and user experience metrics are compared against a mini-map based occluded object selection technique that serves as the baseline. Results indicate that the introduced technique, AssistVR, outperforms the baseline technique when there are multiple target objects. Contrary to the common belief for speech interfaces, AssistVR was able to outperform the baseline even when the target objects were difficult to reference verbally. This work demonstrates the viability and interaction potential of an intelligent multimodal interactive system powered by large laguage models. Based on the results, we discuss the implications for design of future intelligent multimodal interactive systems in immersive environments.