MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
作者: K R Prajwal, Bowen Shi, Matthew Lee, Apoorv Vyas, Andros Tjandra, Mahi Luthra, Baishan Guo, Huiyu Wang, Triantafyllos Afouras, David Kant, Wei-Ning Hsu
分类: cs.SD, cs.AI, eess.AS
发布日期: 2024-10-27
备注: ICML 2024
💡 一句话要点
MusicFlow:一种用于文本引导音乐生成的级联流匹配模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本到音乐生成 流匹配 级联模型 自监督学习 音乐填充 音乐延续 零样本学习 条件生成
📋 核心要点
- 现有文本到音乐生成模型通常参数量大,推理速度慢,难以兼顾生成质量和效率。
- MusicFlow利用级联流匹配,分别建模语义和声学特征的条件分布,实现高效的文本引导音乐生成。
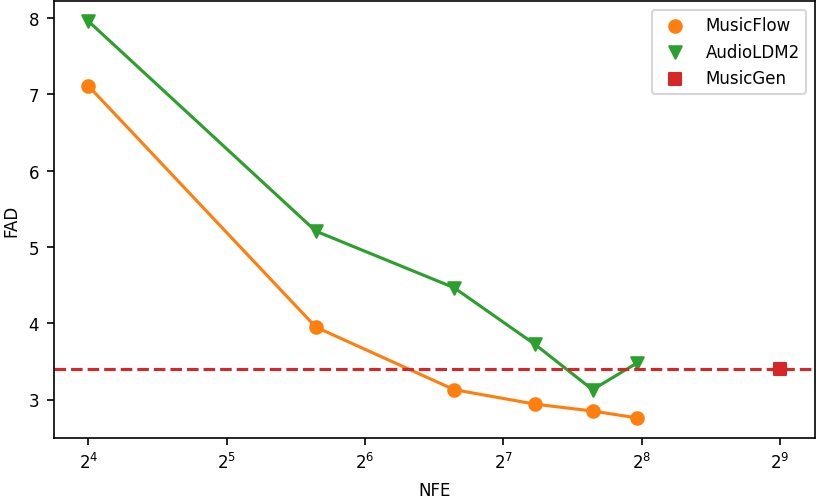
- 实验表明,MusicFlow在保证音乐质量和文本一致性的前提下,显著降低了模型大小和推理时间,并在音乐填充和延续任务上表现出色。
📝 摘要(中文)
本文介绍MusicFlow,一个基于流匹配的级联文本到音乐生成模型。该模型利用自监督表示来桥接文本描述和音乐音频,构建两个流匹配网络来建模语义和声学特征的条件分布。此外,我们采用掩码预测作为训练目标,使模型能够以零样本方式泛化到其他任务,如音乐填充和延续。在MusicCaps上的实验表明,MusicFlow生成的音乐具有卓越的质量和文本一致性,同时模型大小仅为现有模型的2~5倍,且所需的迭代步骤减少5倍。此外,该模型还可以执行其他音乐生成任务,并在音乐填充和延续方面取得有竞争力的性能。代码和模型将公开。
🔬 方法详解
问题定义:文本引导的音乐生成旨在根据给定的文本描述生成相应的音乐。现有方法通常依赖于大型模型和大量的迭代步骤,导致计算成本高昂且推理速度慢。此外,许多模型难以泛化到其他音乐生成任务,如音乐填充和延续。
核心思路:MusicFlow的核心思路是利用级联流匹配来建模文本描述和音乐音频之间的复杂关系。通过将生成过程分解为语义特征生成和声学特征生成两个阶段,可以有效地降低模型的复杂性并提高生成效率。此外,采用掩码预测作为训练目标,增强了模型的泛化能力。
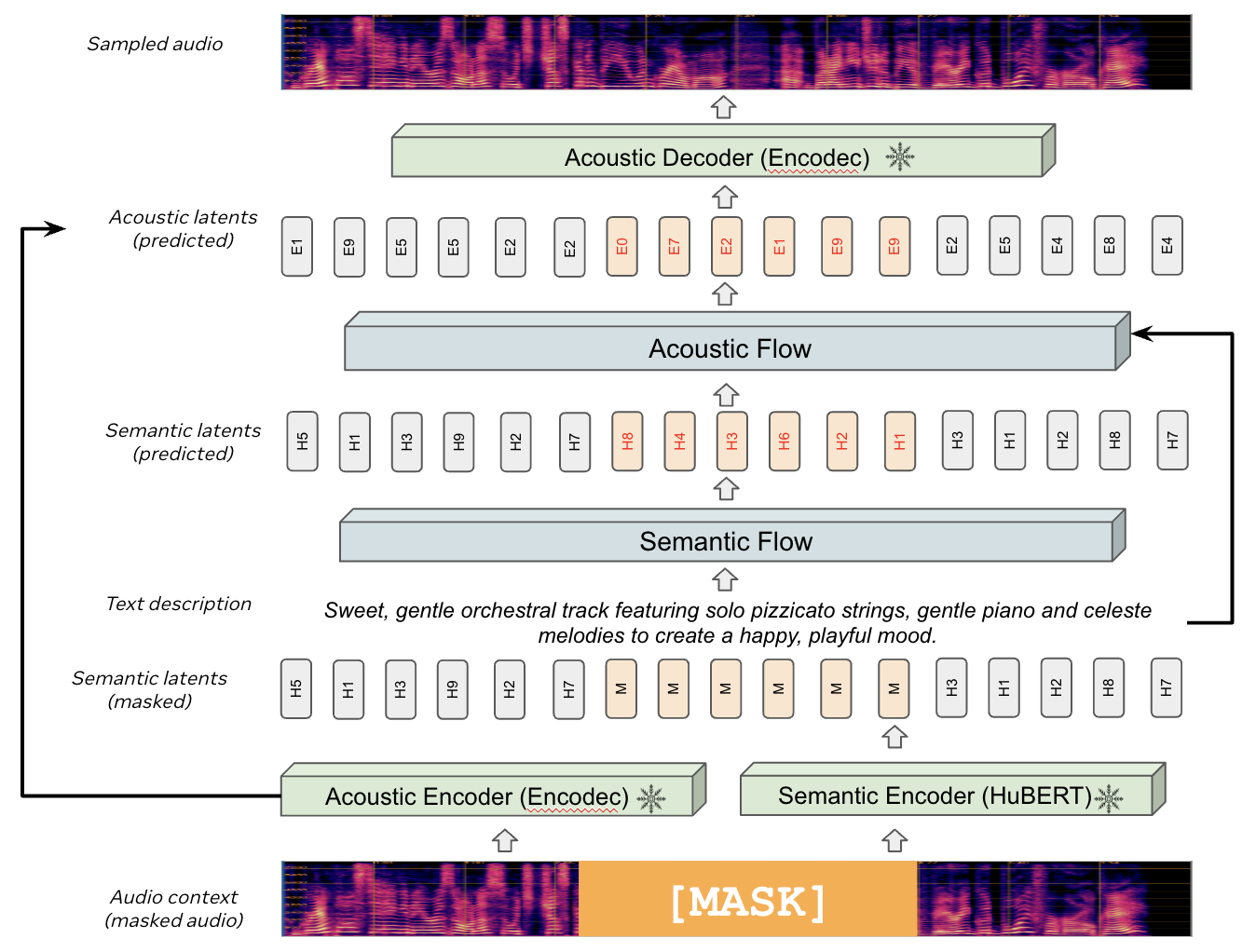
技术框架:MusicFlow包含两个主要的流匹配网络:语义流匹配网络和声学流匹配网络。首先,语义流匹配网络根据文本描述生成语义特征表示。然后,声学流匹配网络以语义特征为条件,生成音乐的声学特征表示。最后,使用声码器将声学特征转换为音频。整个流程是级联的,信息逐步细化。
关键创新:MusicFlow的关键创新在于使用级联流匹配来建模文本到音乐的生成过程。与传统的自回归模型或扩散模型相比,流匹配具有更高的生成效率和更强的可控性。此外,采用掩码预测作为训练目标,使得模型能够以零样本方式泛化到其他音乐生成任务。
关键设计:MusicFlow使用预训练的自监督模型(如HuBERT)提取音乐的声学特征,并使用预训练的文本编码器(如BERT)提取文本的语义特征。流匹配网络采用连续归一化流(CNF)结构,通过求解常微分方程(ODE)来实现特征的转换。损失函数包括流匹配损失和掩码预测损失,用于优化模型的生成质量和泛化能力。
🖼️ 关键图片
📊 实验亮点
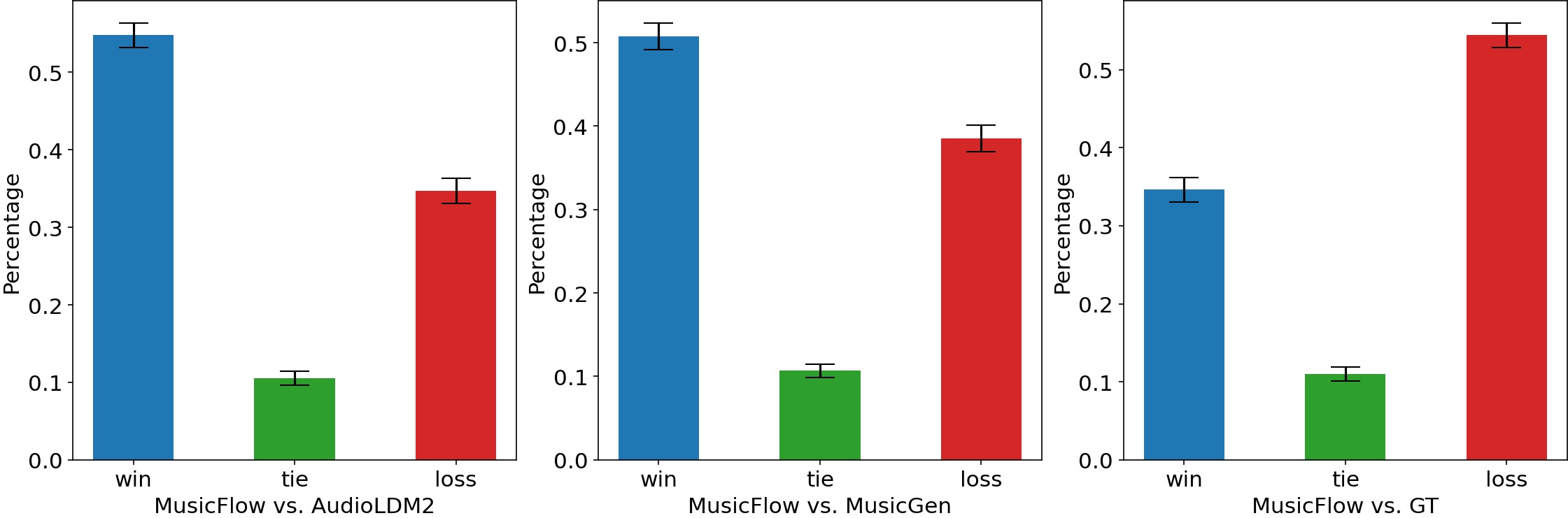
MusicFlow在MusicCaps数据集上取得了显著的成果。实验结果表明,MusicFlow生成的音乐在质量和文本一致性方面优于现有模型,同时模型大小仅为现有模型的2~5倍,且所需的迭代步骤减少5倍。此外,MusicFlow在音乐填充和延续任务上取得了有竞争力的性能,证明了其强大的泛化能力。
🎯 应用场景
MusicFlow具有广泛的应用前景,包括音乐创作辅助、个性化音乐推荐、游戏配乐生成、广告音乐生成等。该模型可以帮助音乐家和内容创作者快速生成高质量的音乐,并为用户提供更加个性化的音乐体验。此外,MusicFlow还可以应用于音乐教育领域,帮助学生更好地理解和创作音乐。
📄 摘要(原文)
We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation. Our code and model will be publicly available.