LLMs Can Evolve Continually on Modality for X-Modal Reasoning
作者: Jiazuo Yu, Haomiao Xiong, Lu Zhang, Haiwen Diao, Yunzhi Zhuge, Lanqing Hong, Dong Wang, Huchuan Lu, You He, Long Chen
分类: cs.AI, cs.CL, cs.CV, cs.LG
发布日期: 2024-10-26 (更新: 2024-11-12)
🔗 代码/项目: GITHUB
💡 一句话要点
提出PathWeave框架,实现多模态大语言模型在模态上的持续演进,解决新增模态时的计算负担问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 持续学习 大语言模型 模态扩展 Adapter-in-Adapter
📋 核心要点
- 现有MLLM方法在扩展新模态时,依赖大量模态特定预训练和联合微调,导致计算成本巨大,限制了其可扩展性。
- PathWeave框架利用持续学习,通过模态路径切换和扩展,使MLLM能以增量方式学习新模态,无需联合预训练,降低计算负担。
- 实验表明,PathWeave在持续学习中表现出良好的可塑性和记忆稳定性,性能与SOTA模型相当,同时显著降低了训练参数量。
📝 摘要(中文)
多模态大语言模型(MLLMs)在多模态理解方面表现出令人印象深刻的能力,因此受到了广泛关注。然而,现有方法严重依赖于大量的模态特定预训练和联合模态微调,这导致扩展到新模态时产生巨大的计算负担。本文提出了PathWeave,一个灵活且可扩展的框架,具有模态路径切换和扩展能力,使MLLMs能够在模态上持续演进,以实现X模态推理。我们利用持续学习的概念,并在预训练的MLLMs之上开发了一种增量训练策略,使其能够使用单模态数据扩展到新的模态,而无需执行联合模态预训练。具体来说,我们引入了一种新颖的Adapter-in-Adapter (AnA)框架,其中单模态和跨模态适配器无缝集成,以促进高效的模态对齐和协作。此外,在两种类型的适配器之间应用了基于MoE的门控模块,以进一步增强多模态交互。为了研究提出的方法,我们建立了一个具有挑战性的基准,称为模态持续学习(MCL),它由来自五个不同模态的高质量QA数据组成:图像、视频、音频、深度和点云。大量的实验证明了所提出的AnA框架在持续学习期间学习可塑性和记忆稳定性的有效性。此外,PathWeave的性能与最先进的MLLMs相当,同时将参数训练负担降低了98.73%。
🔬 方法详解
问题定义:现有MLLM在扩展到新的模态时,需要进行大量的模态特定预训练和联合模态微调,这导致了巨大的计算负担。这种方式不仅效率低下,而且难以适应快速涌现的新模态。因此,如何让MLLM能够以更高效、更灵活的方式持续学习新的模态是一个关键问题。
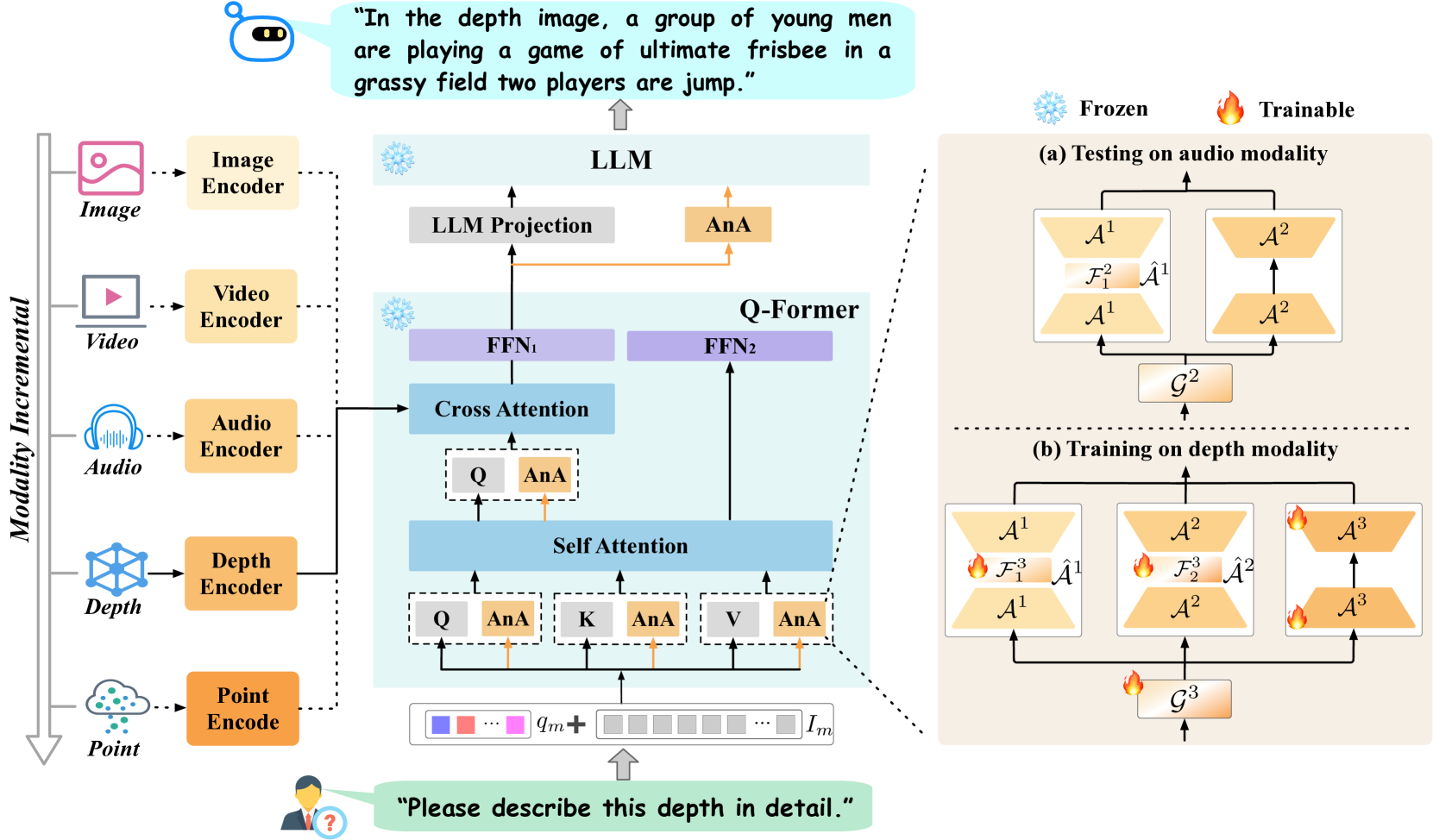
核心思路:PathWeave的核心思路是利用持续学习的思想,通过增量训练的方式,让MLLM能够逐步学习新的模态,而无需从头开始进行联合预训练。通过引入Adapter-in-Adapter (AnA)框架,实现单模态和跨模态信息的有效融合,并利用MoE门控机制增强多模态交互。
技术框架:PathWeave框架主要包含以下几个关键模块:1) 预训练的MLLM:作为基础模型,提供强大的语言理解能力。2) Adapter-in-Adapter (AnA)框架:包含单模态适配器和跨模态适配器,用于分别处理单模态信息和融合多模态信息。3) MoE门控模块:位于单模态适配器和跨模态适配器之间,用于动态调整不同模态信息的权重,增强多模态交互。4) 增量训练策略:利用单模态数据,逐步训练AnA框架,使MLLM能够学习新的模态。
关键创新:PathWeave最关键的创新点在于Adapter-in-Adapter (AnA)框架和基于MoE的门控模块。AnA框架能够有效地分离单模态和跨模态信息的处理,使得模型能够更好地学习不同模态的特征表示。MoE门控模块能够动态地调整不同模态信息的权重,从而增强多模态交互,提高模型的性能。与现有方法相比,PathWeave无需进行大量的联合预训练,大大降低了计算负担。
关键设计:AnA框架中的单模态适配器和跨模态适配器可以采用不同的网络结构,例如Transformer或MLP。MoE门控模块可以采用不同的门控函数,例如Softmax或Sigmoid。增量训练策略可以采用不同的学习率和优化器。损失函数可以包括交叉熵损失和对比损失等。具体参数设置需要根据不同的模态和任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PathWeave在MCL基准测试中表现出良好的可塑性和记忆稳定性。与最先进的MLLMs相比,PathWeave在性能上具有可比性,同时将参数训练负担降低了98.73%。这表明PathWeave是一种高效且有效的多模态学习框架。
🎯 应用场景
PathWeave框架具有广泛的应用前景,例如智能助手、自动驾驶、医疗诊断等领域。它可以使智能系统能够理解和处理来自不同模态的信息,从而提供更全面、更准确的服务。此外,PathWeave框架还可以用于构建多模态数据集,促进多模态学习的研究和发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have gained significant attention due to their impressive capabilities in multimodal understanding. However, existing methods rely heavily on extensive modal-specific pretraining and joint-modal tuning, leading to significant computational burdens when expanding to new modalities. In this paper, we propose PathWeave, a flexible and scalable framework with modal-Path sWitching and ExpAnsion abilities that enables MLLMs to continually EVolve on modalities for $\mathbb{X}$-modal reasoning. We leverage the concept of Continual Learning and develop an incremental training strategy atop pre-trained MLLMs, enabling their expansion to new modalities using uni-modal data, without executing joint-modal pretraining. In detail, a novel Adapter-in-Adapter (AnA) framework is introduced, in which uni-modal and cross-modal adapters are seamlessly integrated to facilitate efficient modality alignment and collaboration. Additionally, an MoE-based gating module is applied between two types of adapters to further enhance the multimodal interaction. To investigate the proposed method, we establish a challenging benchmark called Continual Learning of Modality (MCL), which consists of high-quality QA data from five distinct modalities: image, video, audio, depth and point cloud. Extensive experiments demonstrate the effectiveness of the proposed AnA framework on learning plasticity and memory stability during continual learning. Furthermore, PathWeave performs comparably to state-of-the-art MLLMs while concurrently reducing parameter training burdens by 98.73%. Our code locates at https://github.com/JiazuoYu/PathWeave