Designing AI-Agents with Personalities: A Psychometric Approach
作者: Muhua Huang, Xijuan Zhang, Christopher Soto, James Evans
分类: cs.AI, cs.CY
发布日期: 2024-10-25 (更新: 2025-11-13)
💡 一句话要点
提出一种基于大五人格框架的AI智能体人格化设计方法,用于模拟人类决策。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI智能体 人格化设计 大五人格模型 心理测量学 大型语言模型
📋 核心要点
- 现有AI智能体缺乏系统性人格设计,难以模拟人类决策过程中的个性化差异。
- 利用大五人格理论,通过心理测量学方法量化人格特征,并将其融入AI智能体的提示设计中。
- 实验表明,该方法能使AI智能体在决策行为上更接近人类,但仍存在精细模式上的差异。
📝 摘要(中文)
本文提出了一种使用大五人格框架为AI智能体赋予可量化且经过心理测量学验证的人格的方法。通过三项研究,评估了该方法的可行性和局限性。研究1表明,大型语言模型(LLM)能够捕捉大五人格测量指标之间的语义相似性,为人格分配奠定了基础。研究2利用基于大五人格量表-2(BFI-2)的不同格式设计的提示创建AI智能体,发现由新模型驱动的AI智能体在Mini-Markers测试中与人类反应更加一致,但更精细的结果模式(例如,因子载荷模式)有时不一致。研究3在风险承担和道德困境情景中验证了AI智能体,发现使用BFI-2-Expanded格式提示的模型最能重现人类人格-决策关联,而安全对齐模型通常会夸大“道德”评分。总体而言,结果表明AI智能体在输入的大五人格特质与输出反应之间的相关性方面与人类一致,可以作为初步研究的有用工具。然而,更精细的反应模式的差异表明,AI智能体(目前)不能完全替代人类参与者进行精确或高风险的项目。
🔬 方法详解
问题定义:论文旨在解决如何为AI智能体赋予可量化、可控的人格特征,使其在决策过程中表现出与人类相似的个性化行为。现有方法缺乏系统性的人格建模方法,难以模拟人类决策的复杂性,尤其是在涉及风险和道德判断的场景中。
核心思路:论文的核心思路是利用心理学领域广泛认可的大五人格模型(Big Five framework)来量化人格特征,并将其融入到大型语言模型(LLM)的提示工程中。通过设计与不同人格维度相关的提示,引导LLM生成具有特定人格特征的AI智能体。
技术框架:整体框架包括三个主要阶段:1) 基于LLM分析大五人格量表之间的语义相似性,验证LLM理解人格特征的能力;2) 基于大五人格量表(BFI-2)的不同格式设计提示,创建不同人格类型的AI智能体;3) 在风险承担和道德困境等情景中,评估AI智能体的决策行为,并与人类的决策行为进行对比,验证人格化AI智能体的有效性。
关键创新:该方法的主要创新在于将心理测量学的人格理论与LLM的提示工程相结合,提出了一种系统性的人格化AI智能体设计方法。与以往依赖手工设计或简单规则的方法相比,该方法能够更精确地控制AI智能体的人格特征,并使其在决策行为上更接近人类。
关键设计:论文的关键设计包括:1) 使用不同格式的BFI-2量表设计提示,例如BFI-2-Expanded格式,以探索不同提示方式对AI智能体人格表现的影响;2) 使用风险承担和道德困境等情景来评估AI智能体的决策行为,并与人类的决策行为进行对比;3) 考虑了安全对齐模型对AI智能体道德判断的影响,发现安全对齐模型可能会夸大“道德”评分。
🖼️ 关键图片
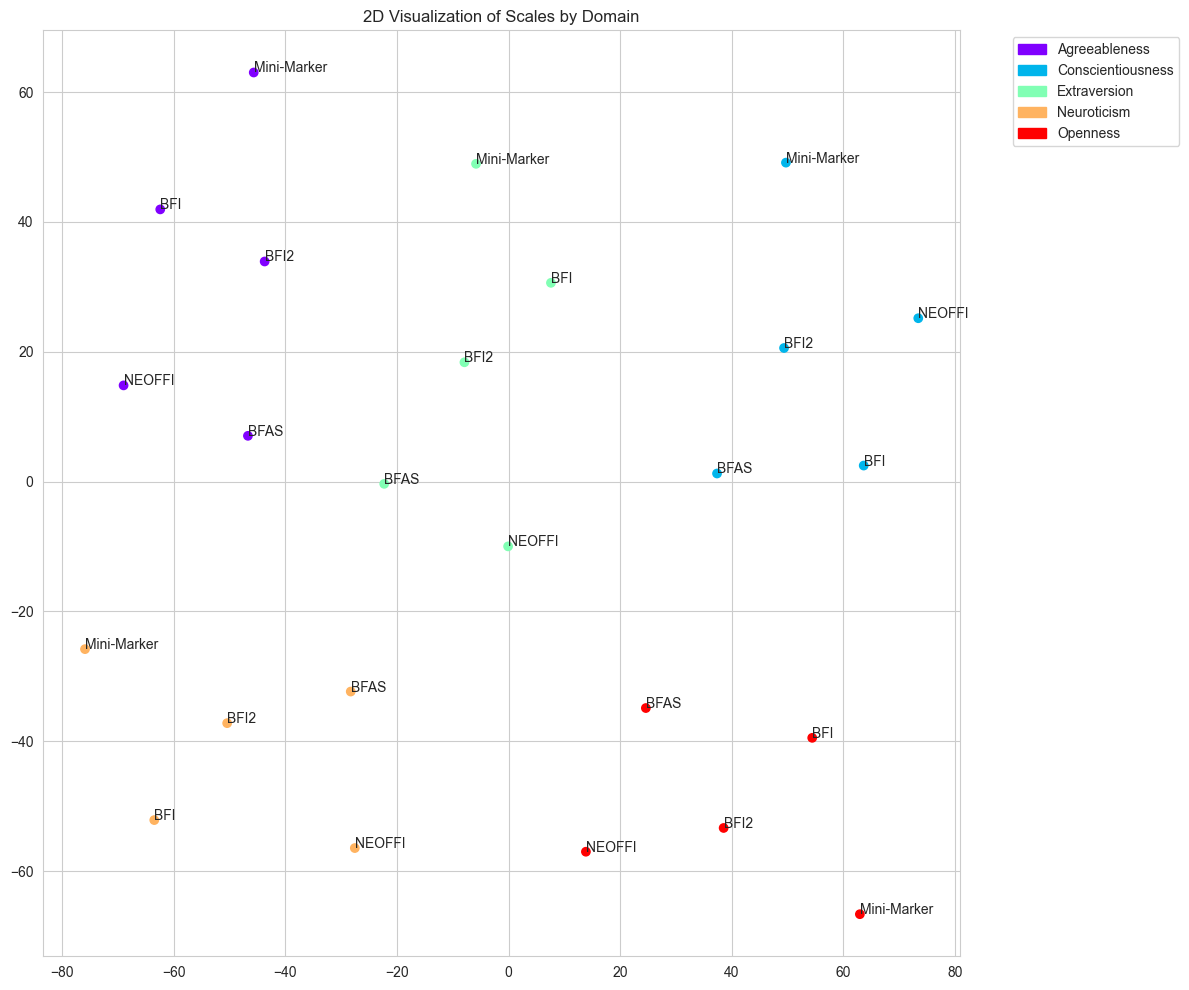
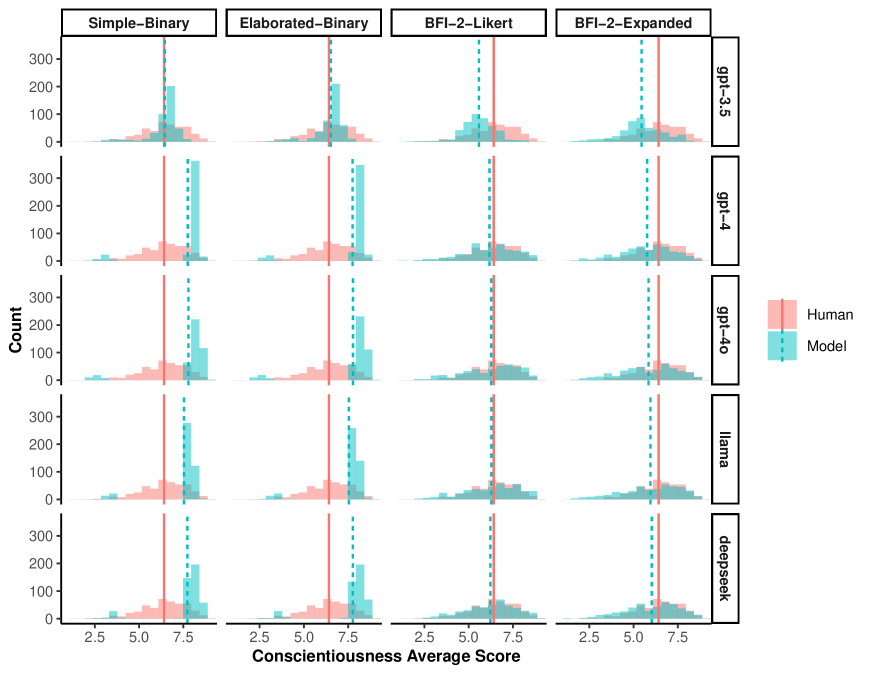
📊 实验亮点
实验结果表明,使用BFI-2-Expanded格式提示的AI智能体在风险承担和道德困境情景中,能够更准确地重现人类人格-决策关联。同时,研究发现安全对齐模型可能会影响AI智能体的道德判断,导致“道德”评分被夸大。这些发现为AI智能体的人格化设计提供了重要的参考。
🎯 应用场景
该研究成果可应用于人机交互、虚拟助手、游戏AI等领域。通过赋予AI智能体不同的人格特征,可以提高用户体验,增强AI智能体的可信度和亲和力。此外,该方法还可以用于研究人格特征对决策行为的影响,为心理学和社会科学研究提供新的工具。
📄 摘要(原文)
We introduce a methodology for assigning quantifiable and psychometrically validated personalities to AI-Agents using the Big Five framework. Across three studies, we evaluate its feasibility and limitations. In Study 1, we show that large language models (LLMs) capture semantic similarities among Big Five measures, providing a basis for personality assignment. In Study 2, we create AI-Agents using prompts designed based on the Big Five Inventory-2 (BFI-2) in different format, and find that AI-Agents powered by new models align more closely with human responses on the Mini-Markers test, although the finer pattern of results (e.g., factor loading patterns) were sometimes inconsistent. In Study 3, we validate our AI-Agents on risk-taking and moral dilemma vignettes, finding that models prompted with the BFI-2-Expanded format most closely reproduce human personality-decision associations, while safety-aligned models generally inflate 'moral' ratings. Overall, our results show that AI-Agents align with humans in correlations between input Big Five traits and output responses and may serve as useful tools for preliminary research. Nevertheless, discrepancies in finer response patterns indicate that AI-Agents cannot (yet) fully substitute for human participants in precision or high-stakes projects.