Tailored-LLaMA: Optimizing Few-Shot Learning in Pruned LLaMA Models with Task-Specific Prompts
作者: Danyal Aftab, Steven Davy
分类: cs.AI
发布日期: 2024-10-24 (更新: 2025-01-09)
期刊: https://www.ecai2024.eu
DOI: 10.3233/FAIA392
💡 一句话要点
Tailored-LLaMA:利用任务特定提示优化剪枝LLaMA模型中的少样本学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型剪枝 少样本学习 任务特定提示 LoRA微调
📋 核心要点
- 现有大型语言模型训练成本高昂,即使是参数较少的模型也需要大量计算资源,限制了其应用。
- Tailored-LLaMA通过结构化剪枝降低模型大小,并结合任务特定提示和LoRA微调,提高效率。
- 实验表明,即使模型压缩50%,Tailored-LLaMA在少样本学习中仍能保持较高的准确率,验证了其有效性。
📝 摘要(中文)
大型语言模型在语言理解和生成方面表现出令人印象深刻的能力。然而,即使是最简单的十亿参数变体,从头开始训练这些模型也需要大量的计算资源,这使得许多组织在经济上难以承受。本文以大型语言模型作为通用任务求解器为出发点,研究了其任务特定的微调。我们采用任务特定的数据集和提示来微调两个剪枝后的LLaMA模型,分别具有50亿和40亿个参数。该过程利用预训练的权重,并使用LoRA方法专注于权重的子集。微调LLaMA模型的一个挑战是设计针对特定任务的精确提示。为了解决这个问题,我们提出了一种新方法,在两个主要约束条件下微调LLaMA模型:任务特异性和提示有效性。我们的方法Tailored LLaMA首先采用结构化剪枝将模型大小从7B减少到5B和4B参数。随后,它应用针对特定任务精心设计的提示,并利用LoRA方法来加速微调过程。此外,对剪枝50%的模型进行不到一小时的微调,通过50次少样本学习,可以将分类任务的平均准确率恢复到20%压缩率下的95.68%和50%压缩率下的86.54%。我们对Tailored LLaMA在这两个剪枝变体上的验证表明,即使压缩到50%,这些模型在少样本分类和生成任务中仍保持超过基线模型准确率的65%。这些发现突出了我们的定制方法在以显著减少的模型大小保持高性能方面的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在资源受限场景下的应用问题。现有LLM虽然能力强大,但训练和部署成本高昂,特别是对于特定任务,通用LLM可能并非最优。现有微调方法可能无法充分利用任务特性,导致性能提升有限。
核心思路:论文的核心思路是结合模型剪枝、任务特定提示和LoRA微调,在降低模型复杂度的同时,提升特定任务上的性能。通过剪枝减少模型参数,降低计算需求;通过任务特定提示引导模型学习;通过LoRA微调加速训练过程,并减少资源消耗。
技术框架:Tailored-LLaMA的技术框架主要包含以下几个阶段:1. 结构化剪枝:对预训练的LLaMA模型进行结构化剪枝,减少模型参数量,得到更小的模型变体(5B和4B)。2. 任务特定提示设计:针对特定任务,设计有效的提示,引导模型学习任务相关知识。3. LoRA微调:使用LoRA(Low-Rank Adaptation)方法,在剪枝后的模型上进行微调,LoRA只训练少量参数,从而加速训练过程并降低资源消耗。4. 评估:在少样本学习场景下,评估微调后模型在特定任务上的性能。
关键创新:论文的关键创新在于将结构化剪枝、任务特定提示和LoRA微调相结合,形成一个完整的优化流程。这种方法能够在降低模型复杂度的同时,保持甚至提升特定任务上的性能。与传统的微调方法相比,Tailored-LLaMA更注重任务特性,能够更有效地利用有限的计算资源。
关键设计:在结构化剪枝方面,论文可能采用了某种策略来选择要剪枝的权重或神经元,例如基于重要性的剪枝。在任务特定提示设计方面,论文可能探索了不同的提示模板或生成方法,以找到最有效的提示。在LoRA微调方面,论文可能调整了LoRA的秩(rank)等参数,以平衡训练速度和性能。
🖼️ 关键图片
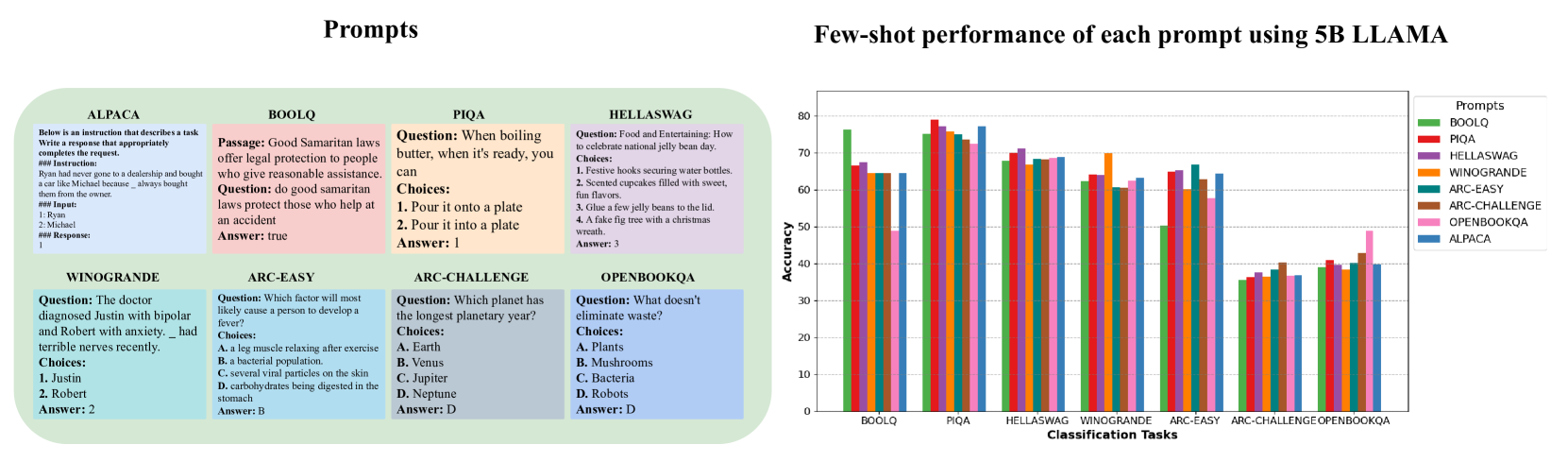

📊 实验亮点
实验结果表明,Tailored-LLaMA在显著降低模型大小的同时,仍能保持较高的性能。例如,对剪枝50%的模型进行不到一小时的微调,通过50次少样本学习,可以将分类任务的平均准确率恢复到20%压缩率下的95.68%和50%压缩率下的86.54%。即使压缩到50%,模型在少样本分类和生成任务中仍保持超过基线模型准确率的65%。
🎯 应用场景
该研究成果可应用于各种资源受限的场景,例如边缘计算设备、移动设备等。通过Tailored-LLaMA,可以在这些设备上部署高性能的特定任务LLM,例如智能客服、文本摘要、机器翻译等。该方法有助于降低LLM的应用门槛,促进LLM在更广泛领域的应用。
📄 摘要(原文)
Large language models demonstrate impressive proficiency in language understanding and generation. Nonetheless, training these models from scratch, even the least complex billion-parameter variant demands significant computational resources rendering it economically impractical for many organizations. With large language models functioning as general-purpose task solvers, this paper investigates their task-specific fine-tuning. We employ task-specific datasets and prompts to fine-tune two pruned LLaMA models having 5 billion and 4 billion parameters. This process utilizes the pre-trained weights and focuses on a subset of weights using the LoRA method. One challenge in fine-tuning the LLaMA model is crafting a precise prompt tailored to the specific task. To address this, we propose a novel approach to fine-tune the LLaMA model under two primary constraints: task specificity and prompt effectiveness. Our approach, Tailored LLaMA initially employs structural pruning to reduce the model sizes from 7B to 5B and 4B parameters. Subsequently, it applies a carefully designed prompt specific to the task and utilizes the LoRA method to accelerate the fine-tuning process. Moreover, fine-tuning a model pruned by 50\% for less than one hour restores the mean accuracy of classification tasks to 95.68\% at a 20\% compression ratio and to 86.54\% at a 50\% compression ratio through few-shot learning with 50 shots. Our validation of Tailored LLaMA on these two pruned variants demonstrates that even when compressed to 50\%, the models maintain over 65\% of the baseline model accuracy in few-shot classification and generation tasks. These findings highlight the efficacy of our tailored approach in maintaining high performance with significantly reduced model sizes.