MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
作者: S Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, Dinesh Manocha
分类: eess.AS, cs.AI, cs.CL, cs.SD
发布日期: 2024-10-24
备注: Project Website: https://sakshi113.github.io/mmau_homepage/
💡 一句话要点
提出MMAU:一个大规模多任务音频理解与推理基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频理解 多模态学习 推理基准 自然语言处理 音频语言模型
📋 核心要点
- 现有音频理解基准缺乏对专家级知识和复杂推理能力的考察,限制了模型在实际应用中的表现。
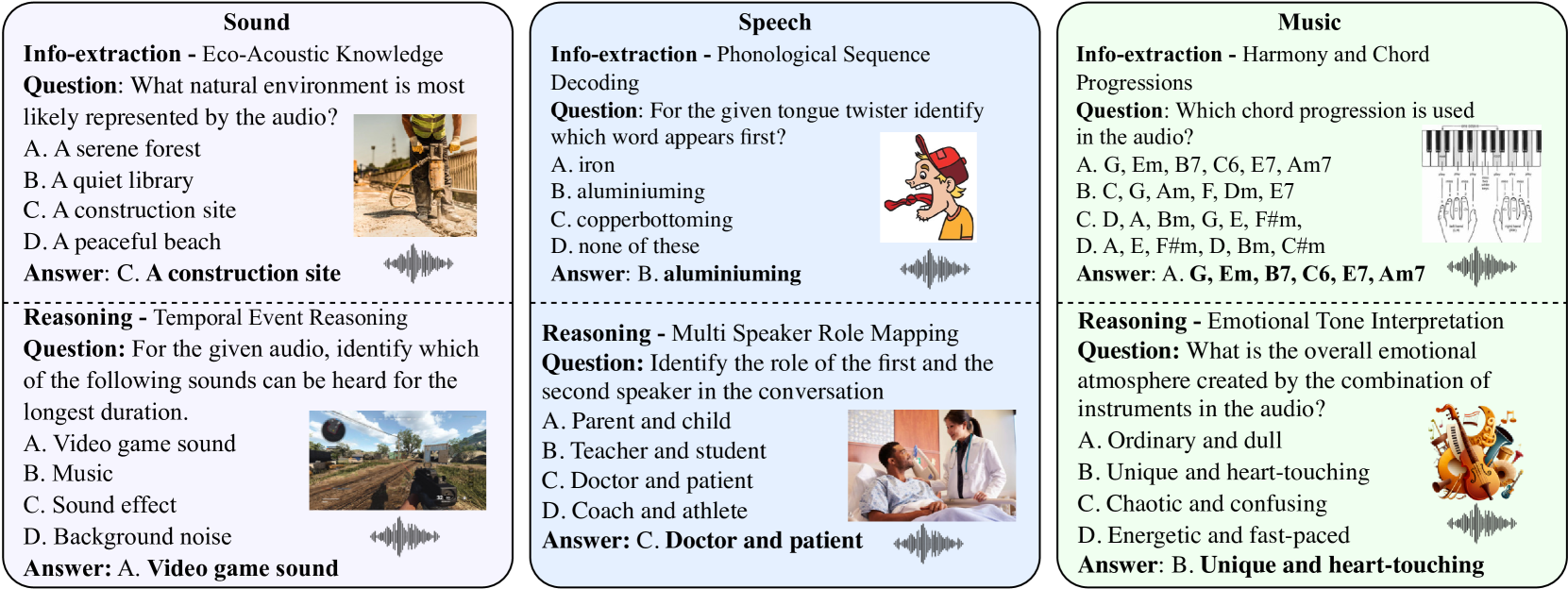
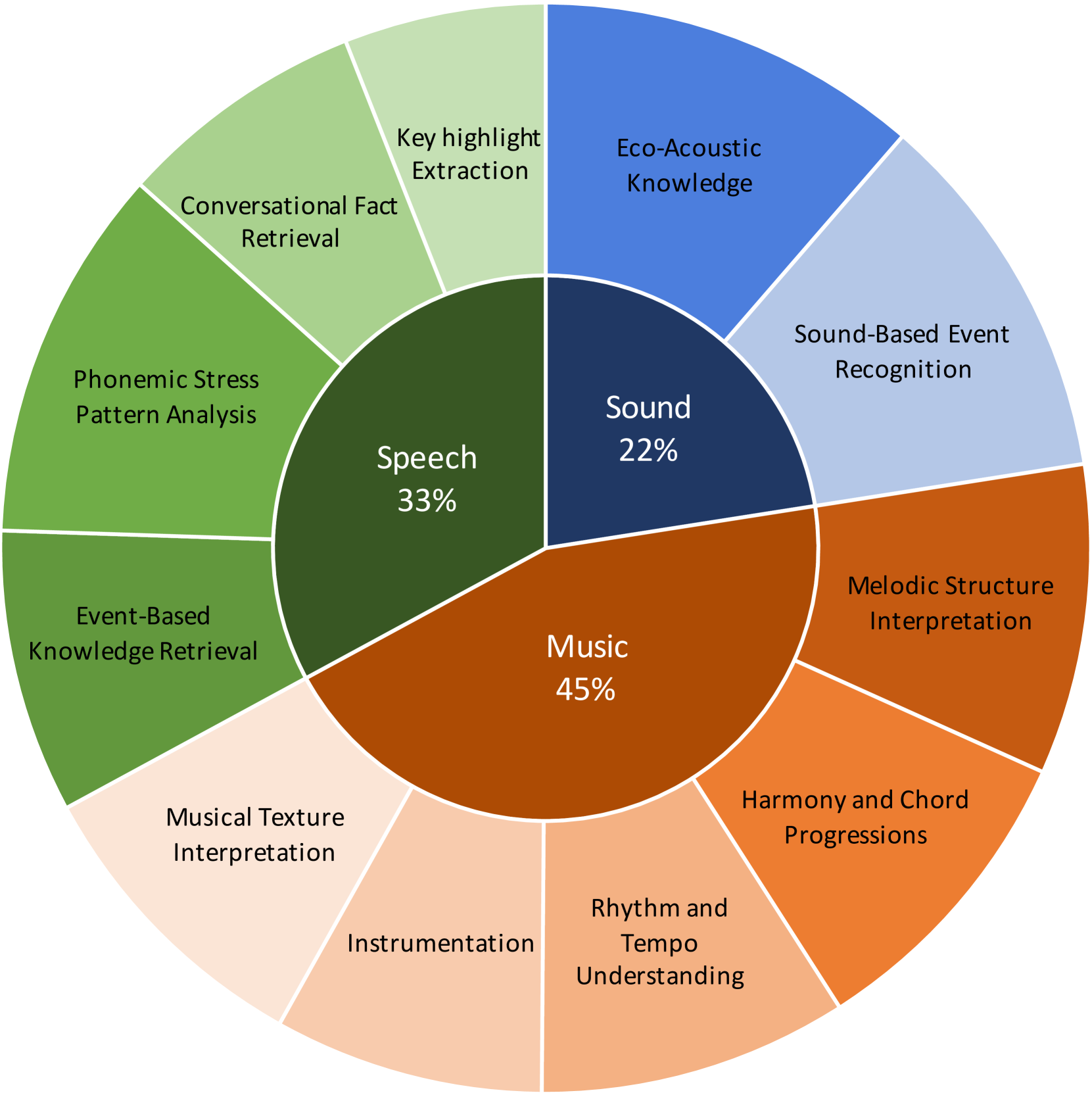
- MMAU基准通过构建包含语音、环境声音和音乐的多样化数据集,并设计需要信息提取和推理的任务来解决上述问题。
- 实验结果表明,即使是最先进的音频-语言模型在MMAU基准上表现仍然欠佳,证明了该基准的挑战性和价值。
📝 摘要(中文)
本文提出了MMAU,一个新颖的基准,旨在评估多模态音频理解模型在需要专家级知识和复杂推理的任务上的表现。MMAU包含1万个精心策划的音频片段,并配以人工标注的自然语言问题和答案,涵盖语音、环境声音和音乐。它包括信息提取和推理问题,要求模型展示27种不同的技能,涉及独特且具有挑战性的任务。与现有基准不同,MMAU强调高级感知和具有领域特定知识的推理,挑战模型解决类似于专家所面临的任务。对18个开源和专有(大型)音频-语言模型进行了评估,结果表明MMAU带来了巨大的挑战。值得注意的是,即使是最先进的Gemini Pro v1.5也仅达到52.97%的准确率,而最先进的开源Qwen2-Audio仅达到52.50%,突出了巨大的改进空间。我们相信MMAU将推动音频和多模态研究社区开发更先进的音频理解模型,从而能够解决复杂的音频任务。
🔬 方法详解
问题定义:现有音频理解模型在处理需要专家知识和复杂推理的任务时表现不佳。现有的基准测试无法充分评估模型在这些方面的能力,阻碍了模型在实际应用中的发展。因此,需要一个更具挑战性的基准来推动音频理解模型的发展。
核心思路:MMAU的核心思路是构建一个包含多样化音频内容(语音、环境声音、音乐)和复杂推理任务的基准。通过引入需要领域特定知识和推理能力的问题,来挑战模型,使其能够更好地理解和处理音频信息。
技术框架:MMAU基准包含以下几个关键组成部分: 1. 音频数据集:包含1万个音频片段,涵盖语音、环境声音和音乐。 2. 问题和答案:每个音频片段都配有自然语言问题和答案,需要模型进行信息提取和推理。 3. 评估指标:使用准确率作为主要评估指标,衡量模型在回答问题方面的表现。
关键创新:MMAU的关键创新在于其强调了高级感知和具有领域特定知识的推理。与现有基准相比,MMAU更加关注模型在处理复杂音频任务时的推理能力,并要求模型具备一定的领域知识。
关键设计:MMAU的关键设计包括: 1. 多样化的音频内容:确保数据集包含各种类型的音频,以提高模型的泛化能力。 2. 复杂的问题设计:设计需要信息提取、推理和领域知识的问题,以挑战模型的理解能力。 3. 人工标注的答案:使用人工标注的答案作为ground truth,确保评估的准确性。
🖼️ 关键图片

📊 实验亮点
在MMAU基准上,对18个开源和专有音频-语言模型进行了评估。结果显示,即使是最先进的Gemini Pro v1.5模型也仅达到52.97%的准确率,而最先进的开源Qwen2-Audio模型仅达到52.50%的准确率。这些结果表明,现有的音频理解模型在处理复杂音频任务时仍然面临巨大的挑战,MMAU基准为未来的研究提供了明确的方向。
🎯 应用场景
MMAU基准的潜在应用领域包括智能助手、自动驾驶、音频取证、音乐信息检索等。通过提高音频理解模型的性能,可以使这些应用更加智能和可靠。例如,智能助手可以更好地理解用户的语音指令,自动驾驶系统可以更准确地识别环境声音,音频取证可以更有效地分析音频证据,音乐信息检索可以更准确地识别音乐。
📄 摘要(原文)
The ability to comprehend audio--which includes speech, non-speech sounds, and music--is crucial for AI agents to interact effectively with the world. We present MMAU, a novel benchmark designed to evaluate multimodal audio understanding models on tasks requiring expert-level knowledge and complex reasoning. MMAU comprises 10k carefully curated audio clips paired with human-annotated natural language questions and answers spanning speech, environmental sounds, and music. It includes information extraction and reasoning questions, requiring models to demonstrate 27 distinct skills across unique and challenging tasks. Unlike existing benchmarks, MMAU emphasizes advanced perception and reasoning with domain-specific knowledge, challenging models to tackle tasks akin to those faced by experts. We assess 18 open-source and proprietary (Large) Audio-Language Models, demonstrating the significant challenges posed by MMAU. Notably, even the most advanced Gemini Pro v1.5 achieves only 52.97% accuracy, and the state-of-the-art open-source Qwen2-Audio achieves only 52.50%, highlighting considerable room for improvement. We believe MMAU will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.