ReasonAgain: Using Extractable Symbolic Programs to Evaluate Mathematical Reasoning
作者: Xiaodong Yu, Ben Zhou, Hao Cheng, Dan Roth
分类: cs.AI
发布日期: 2024-10-24
💡 一句话要点
ReasonAgain:利用可提取的符号程序评估数学推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 大型语言模型 符号程序 自动评估 数据集生成
📋 核心要点
- 现有数学推理评估依赖最终答案或静态示例,无法有效检测模型的错误推理或适应多种解法。
- 该论文提出使用符号程序自动生成多样化测试用例,以更严格地评估LLM的数学推理能力。
- 实验表明,基于符号程序生成的数据集评估,LLM的准确率显著下降,揭示了现有模型的脆弱性。
📝 摘要(中文)
现有的数学数据集通过最终答案或从静态示例中获得的中间推理步骤来评估大型语言模型(LLM)的推理能力。然而,前一种方法无法揭示模型使用捷径和错误推理的情况,而后一种方法在适应替代解决方案方面面临挑战。本文旨在利用符号程序作为一种自动评估手段,判断模型是否能在程序的各种输入中始终如一地产生正确的最终答案。我们首先使用GPT4-o提取流行数学数据集(GSM8K和MATH)的程序。对于那些使用原始输入-输出对验证过的可执行程序,我们发现它们封装了解决原始文本问题所需的正确推理。然后,我们提示GPT4-o基于提取的程序,使用替代的输入-输出对生成新的问题。我们将生成的数据集应用于评估一系列LLM。在我们的实验中,我们观察到使用我们提出的评估方法相比原始静态示例,准确率显著下降,表明最先进的LLM的数学推理能力存在脆弱性。
🔬 方法详解
问题定义:现有数学推理数据集的评估方法存在局限性。仅依赖最终答案无法发现模型使用捷径或错误推理的情况,而依赖静态示例的中间步骤则难以适应不同的解题思路。这使得对LLM数学推理能力的评估不够全面和鲁棒。
核心思路:该论文的核心思路是利用符号程序来生成多样化的测试用例。通过提取现有数据集的程序逻辑,并基于这些程序生成新的输入-输出对,可以创建更具挑战性的测试集,从而更准确地评估LLM的数学推理能力。这种方法能够克服现有方法的局限性,更全面地考察模型的推理能力。
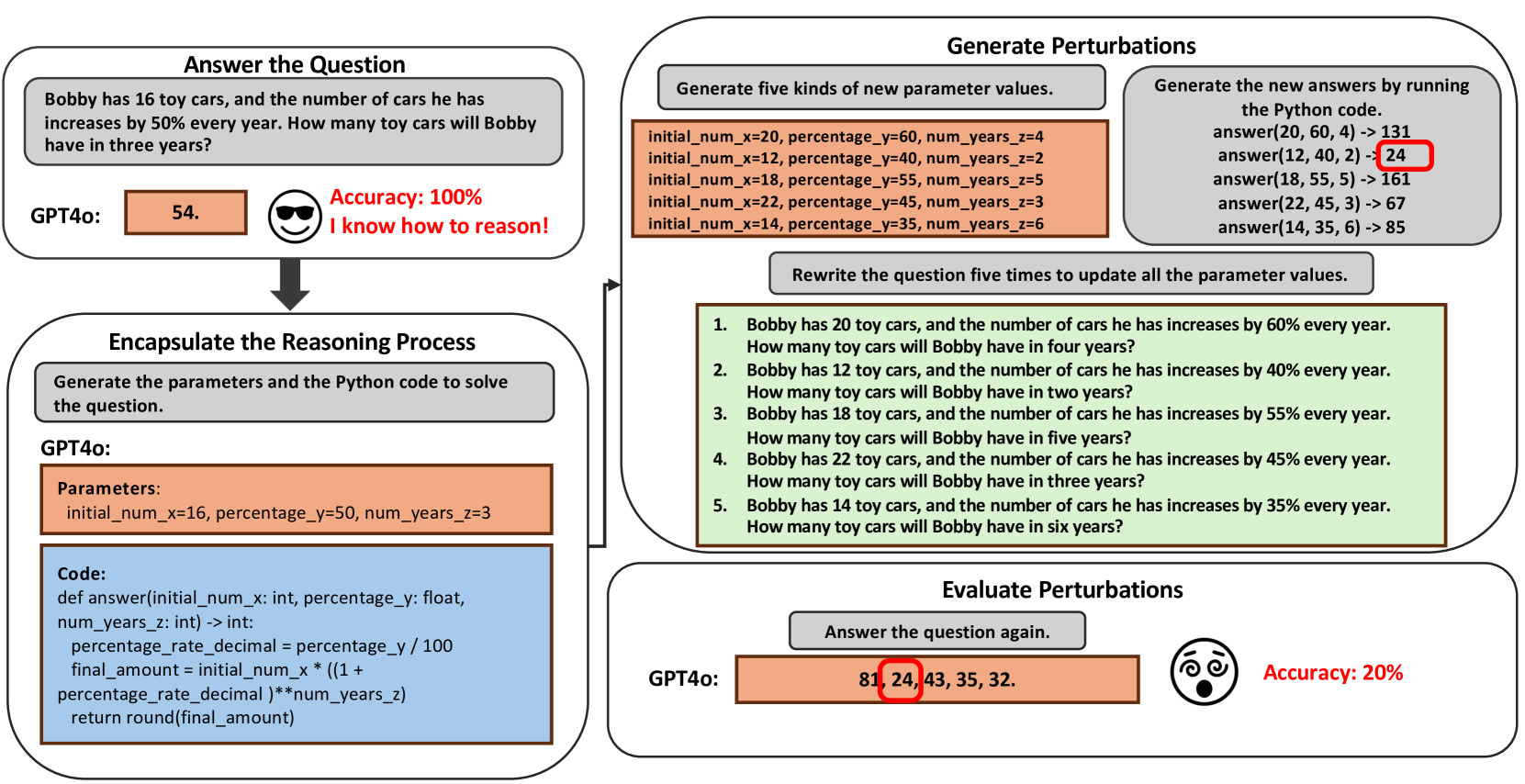
技术框架:整体流程包括以下几个主要阶段:1) 使用GPT4-o从GSM8K和MATH等数学数据集中提取符号程序;2) 使用原始输入-输出对验证提取的程序,确保其正确性;3) 利用GPT4-o基于提取的程序生成新的输入-输出对,创建新的测试数据集;4) 使用生成的数据集评估一系列LLM的数学推理能力;5) 分析实验结果,比较不同评估方法下的模型性能。
关键创新:该论文最重要的技术创新点在于使用可提取的符号程序来自动生成数学推理测试用例。与传统的静态数据集相比,这种方法能够生成更多样化、更具挑战性的测试用例,从而更准确地评估LLM的数学推理能力。此外,该方法还可以检测模型在不同输入下的推理一致性,从而发现模型潜在的脆弱性。
关键设计:论文的关键设计包括:1) 使用GPT4-o进行程序提取和问题生成,利用其强大的代码生成和理解能力;2) 通过原始输入-输出对验证提取程序的正确性,确保生成测试用例的有效性;3) 设计实验评估不同LLM在原始数据集和生成数据集上的性能,比较不同评估方法的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用该论文提出的基于符号程序的评估方法,LLM在数学推理任务上的准确率显著下降。例如,与在原始静态示例上的表现相比,某些模型的准确率下降了超过20%。这表明现有LLM的数学推理能力存在脆弱性,需要进一步改进。
🎯 应用场景
该研究成果可应用于更可靠地评估和提升大型语言模型的数学推理能力。通过自动生成多样化的测试用例,可以发现模型潜在的缺陷,并指导模型的训练和优化。此外,该方法还可以推广到其他需要复杂推理能力的领域,例如科学计算、逻辑推理等。
📄 摘要(原文)
Existing math datasets evaluate the reasoning abilities of large language models (LLMs) by either using the final answer or the intermediate reasoning steps derived from static examples. However, the former approach fails to surface model's uses of shortcuts and wrong reasoning while the later poses challenges in accommodating alternative solutions. In this work, we seek to use symbolic programs as a means for automated evaluation if a model can consistently produce correct final answers across various inputs to the program. We begin by extracting programs for popular math datasets (GSM8K and MATH) using GPT4-o. For those executable programs verified using the original input-output pairs, they are found to encapsulate the proper reasoning required to solve the original text questions. We then prompt GPT4-o to generate new questions using alternative input-output pairs based the extracted program. We apply the resulting datasets to evaluate a collection of LLMs. In our experiments, we observe significant accuracy drops using our proposed evaluation compared with original static examples, suggesting the fragility of math reasoning in state-of-the-art LLMs.