Improving Small-Scale Large Language Models Function Calling for Reasoning Tasks
作者: Graziano A. Manduzio, Federico A. Galatolo, Mario G. C. A. Cimino, Enzo Pasquale Scilingo, Lorenzo Cominelli
分类: cs.AI
发布日期: 2024-10-24
💡 一句话要点
提出一种基于RLHF的小型语言模型函数调用优化框架,提升其在推理任务上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 函数调用 推理任务 强化学习 直接偏好优化
📋 核心要点
- 大型语言模型在复杂推理任务中表现出色,但在数学问题求解和逻辑推理方面仍面临挑战。
- 该研究提出一种框架,通过函数调用能力,训练小型语言模型解决特定逻辑和数学推理任务。
- 实验结果表明,该方法在模型大小和性能之间取得了平衡,提升了小型模型在推理任务中函数调用的能力。
📝 摘要(中文)
本文提出了一种新颖的框架,用于训练小型语言模型进行函数调用,专注于特定的逻辑和数学推理任务。该方法旨在提高小型模型在这些任务中使用函数调用时的性能,并确保高精度。该框架采用一个代理,给定一个问题和一组可调用函数,通过将可用函数的描述和示例注入到提示中来查询LLM,并在逐步推理链中管理它们的调用。此过程用于从大型LLM创建正确和不正确的推理链聊天完成的数据集。该数据集用于使用来自人类反馈的强化学习 (RLHF) 训练较小的 LLM,特别是采用直接偏好优化 (DPO) 技术。实验结果表明,该方法如何在模型大小和性能之间取得平衡,从而提高小型模型在推理任务中函数调用的能力。
🔬 方法详解
问题定义:现有的大型语言模型虽然在通用推理任务上表现出色,但训练和推理成本高昂,难以在资源受限的环境中使用。小型语言模型虽然计算成本较低,但在复杂的数学和逻辑推理任务中表现不佳,尤其是在需要函数调用来辅助推理时。因此,需要一种方法来提升小型语言模型在特定推理任务中函数调用的能力,同时保持较低的计算成本。
核心思路:该论文的核心思路是利用大型语言模型生成高质量的训练数据,然后使用强化学习从人类反馈(RLHF)的方法,特别是直接偏好优化(DPO),来训练小型语言模型。通过这种方式,小型模型可以学习大型模型的推理能力和函数调用技巧,从而在特定任务上达到可接受的性能水平。
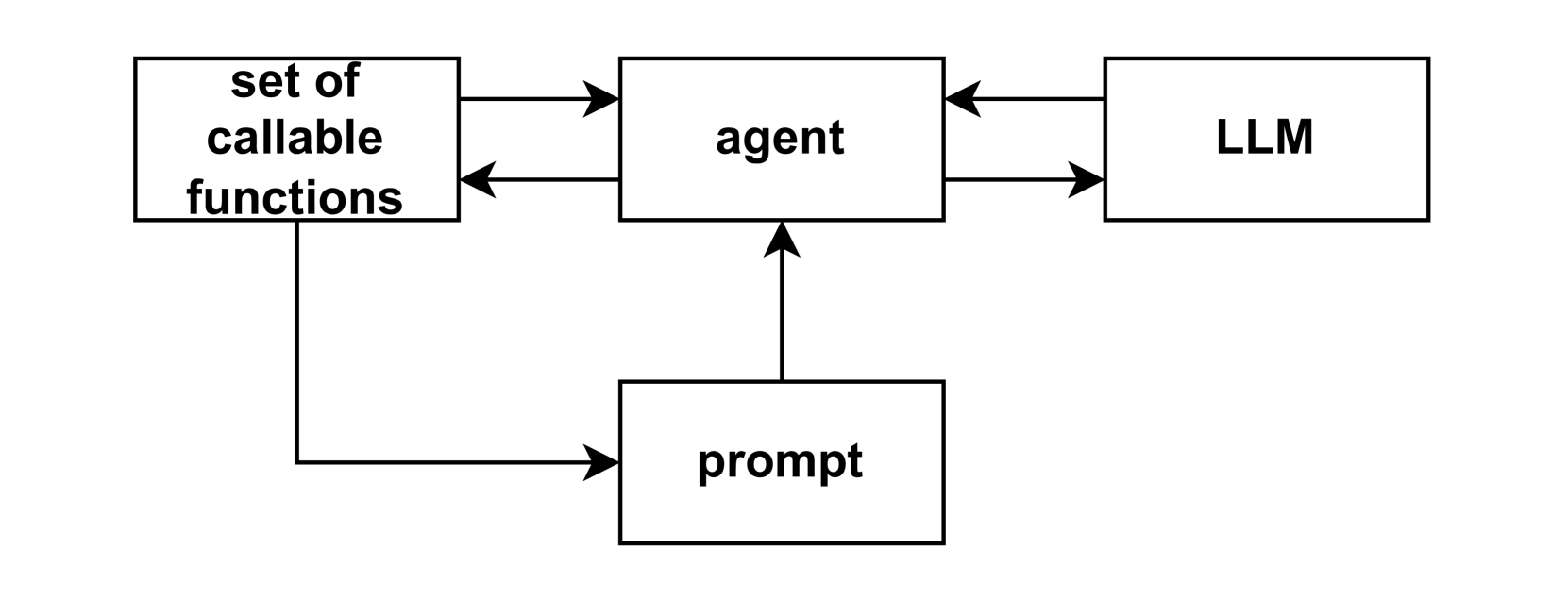
技术框架:该框架包含以下几个主要步骤:1) 数据生成:使用大型语言模型作为教师模型,给定一个问题和一组可调用函数,通过提示工程,让大型模型生成推理链,并记录函数调用过程。同时,也记录错误的推理链。2) 数据集构建:将大型模型生成的正确和错误的推理链整理成数据集,用于后续的RLHF训练。3) 模型训练:使用小型语言模型作为学生模型,利用DPO算法,根据数据集中的偏好信息,优化模型的策略,使其能够更好地进行推理和函数调用。
关键创新:该论文的关键创新在于:1) 利用大型语言模型生成高质量的训练数据,避免了人工标注的成本和偏差。2) 使用DPO算法,简化了RLHF的训练过程,提高了训练效率。3) 针对小型语言模型,优化了函数调用的训练方法,使其能够在特定任务上达到较好的性能。
关键设计:在数据生成阶段,通过提示工程,引导大型模型生成包含函数调用的推理链。在DPO训练阶段,需要仔细设计奖励函数,以鼓励模型生成正确的推理链,并避免错误的推理。具体的参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该研究通过实验证明,所提出的框架能够有效提升小型语言模型在推理任务中的函数调用能力。具体的性能数据和对比基线在摘要中未提及,属于未知信息。但总体而言,该方法在模型大小和性能之间取得了较好的平衡,使得小型模型能够在特定任务上达到可接受的性能水平。
🎯 应用场景
该研究成果可应用于资源受限的场景,例如移动设备或嵌入式系统,在这些场景中,大型语言模型无法部署。通过训练小型语言模型,可以在这些设备上实现智能助手、自动推理等功能,具有广泛的应用前景。此外,该方法还可以用于定制化特定领域的语言模型,例如医疗诊断、金融分析等。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have demonstrated exceptional capabilities in natural language understanding and generation. While these models excel in general complex reasoning tasks, they still face challenges in mathematical problem-solving and logical reasoning. To address these limitations, researchers have explored function calling abilities, allowing LLMs to execute provided functions and utilize their outputs for task completion. However, concentrating on specific tasks can be very inefficient for large-scale LLMs to be used, because of the expensive cost of training and inference stages they need in terms of computational resources. This study introduces a novel framework for training smaller language models in function calling, focusing on specific logical and mathematical reasoning tasks. The approach aims to improve performances of small-scale models for these tasks using function calling, ensuring a high level of accuracy. Our framework employs an agent that, given a problem and a set of callable functions, queries the LLM by injecting a description and examples of the usable functions into the prompt and managing their calls in a step-by-step reasoning chain. This process is used to create a dataset of correct and incorrect reasoning chain chat completions from a large-scale LLM. This dataset is used to train a smaller LLM using Reinforcement Learning from Human Feedback (RLHF), specifically employing the Direct Preference Optimization (DPO) technique. Experimental results demonstrate how the proposed approach balances the trade-off between model size and performance, improving the ability of function calling for reasoning tasks, in smaller models.