ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference
作者: Xin He, Shunkang Zhang, Yuxin Wang, Haiyan Yin, Zihao Zeng, Shaohuai Shi, Zhenheng Tang, Xiaowen Chu, Ivor Tsang, Ong Yew Soon
分类: cs.AI, cs.CL
发布日期: 2024-10-23
备注: Mixture-of-Experts, Inference, Offloading
💡 一句话要点
ExpertFlow:优化专家激活与令牌分配,提升MoE模型推理效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 模型推理 专家卸载 动态调度 资源优化
📋 核心要点
- 现有MoE模型推理面临高内存需求和专家缓存利用率低下的挑战,阻碍了其在资源受限环境中的部署。
- ExpertFlow通过预测路由路径进行专家卸载,并动态调度令牌,从而优化专家激活和内存管理。
- 实验表明,ExpertFlow显著降低了GPU内存占用,并提升了推理速度,验证了其在资源受限场景下的有效性。
📝 摘要(中文)
稀疏混合专家模型(MoE)在性能上优于稠密大型语言模型(LLM),但由于其高内存需求,在推理过程中面临着巨大的部署挑战。现有的卸载技术,涉及在GPU和CPU之间交换激活和空闲专家,通常受到刚性专家缓存机制的限制。这些机制无法适应动态路由,导致缓存利用率低下,或者产生过高的预测训练成本。为了解决这些特定于推理的挑战,我们引入了ExpertFlow,这是一个全面的系统,专门用于通过适应灵活的路由并在CPU和GPU之间实现高效的专家调度来提高推理效率。这减少了开销并提高了系统性能。我们方法的核心是一种基于预测路由路径的卸载机制,该机制利用轻量级预测器在计算开始之前准确预测路由路径。这种主动策略允许对专家缓存进行实时错误纠正,从而显着提高缓存命中率并减少专家传输的频率,从而最大限度地减少I/O开销。此外,我们还实施了一种动态令牌调度策略,通过重新排列不同批次中的输入令牌来优化MoE推理。这种方法不仅减少了每个批次中激活专家的数量,而且提高了计算效率。我们广泛的实验表明,与基线方法相比,ExpertFlow实现了高达93.72%的GPU内存节省,并将推理速度提高了2到10倍,突显了其有效性和实用性,是资源受限推理场景的强大解决方案。
🔬 方法详解
问题定义:MoE模型推理时,由于模型参数量巨大,需要大量的GPU内存。现有的专家卸载方法,例如简单地将不活跃的专家卸载到CPU,存在专家缓存利用率低、I/O开销大的问题,无法有效支持动态路由,限制了MoE模型在资源受限环境中的应用。
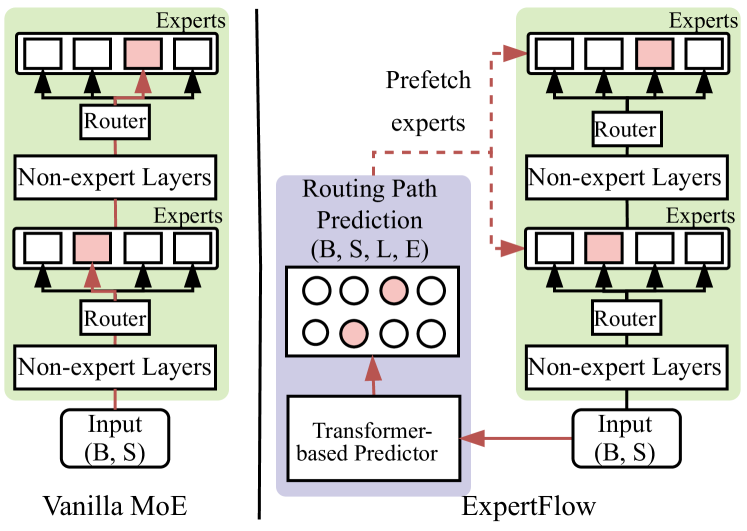
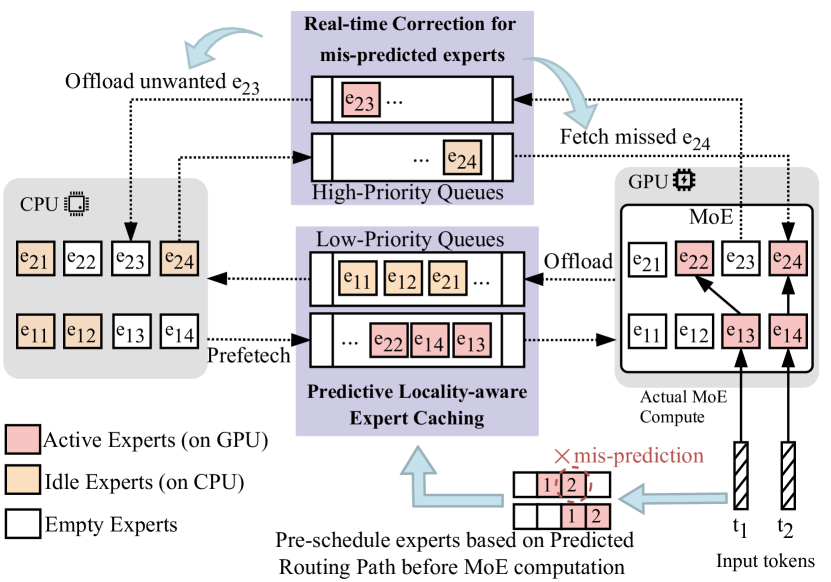
核心思路:ExpertFlow的核心思路是预测专家的路由路径,提前将需要的专家加载到GPU,并动态地调整token的分配,从而提高专家缓存的命中率,减少I/O开销,并优化计算效率。通过预测路由,系统可以主动管理专家在GPU和CPU之间的迁移,避免不必要的专家加载和卸载。
技术框架:ExpertFlow包含两个主要模块:预测路由路径的专家卸载机制和动态令牌调度策略。首先,使用一个轻量级的预测器预测token的路由路径。然后,根据预测结果,提前将需要的专家从CPU加载到GPU。其次,通过动态令牌调度,将token重新分配到不同的batch中,减少每个batch中激活的专家数量,从而提高计算效率。
关键创新:ExpertFlow的关键创新在于预测路由路径的专家卸载机制和动态令牌调度策略的结合。传统的专家卸载方法通常是基于静态的缓存策略,无法适应动态的路由。ExpertFlow通过预测路由路径,实现了主动的专家管理,提高了缓存命中率。动态令牌调度策略进一步优化了计算效率,减少了每个batch中激活的专家数量。
关键设计:预测器采用轻量级网络结构,以减少预测开销。动态令牌调度策略采用贪心算法,将token分配到激活专家数量最少的batch中。损失函数的设计需要平衡预测精度和计算开销。具体参数设置(如预测器网络结构、学习率、batch size等)需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ExpertFlow在GPU内存节省方面表现出色,最高可达93.72%。同时,推理速度也得到了显著提升,最高可达2到10倍。与基线方法相比,ExpertFlow在资源利用率和推理效率方面都取得了显著的优势,验证了其有效性。
🎯 应用场景
ExpertFlow可应用于各种资源受限的MoE模型推理场景,例如移动设备、边缘计算设备等。通过降低GPU内存需求和提高推理速度,ExpertFlow使得在这些设备上部署高性能的MoE模型成为可能。这对于自然语言处理、计算机视觉等领域的应用具有重要意义,例如智能助手、图像识别等。
📄 摘要(原文)
Sparse Mixture of Experts (MoE) models, while outperforming dense Large Language Models (LLMs) in terms of performance, face significant deployment challenges during inference due to their high memory demands. Existing offloading techniques, which involve swapping activated and idle experts between the GPU and CPU, often suffer from rigid expert caching mechanisms. These mechanisms fail to adapt to dynamic routing, leading to inefficient cache utilization, or incur prohibitive costs for prediction training. To tackle these inference-specific challenges, we introduce ExpertFlow, a comprehensive system specifically designed to enhance inference efficiency by accommodating flexible routing and enabling efficient expert scheduling between CPU and GPU. This reduces overhead and boosts system performance. Central to our approach is a predictive routing path-based offloading mechanism that utilizes a lightweight predictor to accurately forecast routing paths before computation begins. This proactive strategy allows for real-time error correction in expert caching, significantly increasing cache hit ratios and reducing the frequency of expert transfers, thereby minimizing I/O overhead. Additionally, we implement a dynamic token scheduling strategy that optimizes MoE inference by rearranging input tokens across different batches. This method not only reduces the number of activated experts per batch but also improves computational efficiency. Our extensive experiments demonstrate that ExpertFlow achieves up to 93.72\% GPU memory savings and enhances inference speed by 2 to 10 times compared to baseline methods, highlighting its effectiveness and utility as a robust solution for resource-constrained inference scenarios.